4.1. - The Relational Data Model
4.1.1. - The Mathematical Concept
4.1.2. - Domains, Tuples, Attributes and Relations
4.1.3. - Relation Schemes
4.1.4. - Representing Data in the Relational Model
4.1.5. - Characteristics of Relations
4.1.6. - Operations on Relational Databases
4.2. - Data Flow in a X-BASE DBMS
4.2.1. - Data Fields
4.2.1.1. - Databases Work areas
4.2.1.2. - Memory Variables
4.2.1.3. - Display Fields
4.2.2. - Navigation in Tables
4.2.2.1. - Cursors
4.2.2.2. - Inspection Order
In 1970 Ted Codd, with their paper A Relational Model of Data for Large Shared Data Banks, introduced the relational model of data as a tool for general data base management.
The relational model represents the database as a collection of relations. Informally, each relation resembles a table or, to some extent, a simple files. When a relation is thought of as a table of values, each row in the table represents a collection of related data values. These values can be interpreted as facts describing a real-world entity or relationship. The table name and column names are used to help in interpreting the meaning of the values in each row of the table.
STUDENT (Student-Numbe 757d34h r, Name, Surname, Class)
TEACHER (Teacher-Number, Name Surname, Function)
DISCIPLINE (Code, Name, Hours)
EXAMINATION-MODE (Code, Name)
EXAMINATION-MODE.Name has the values:
EXAM (Student-Number, Teacher-Number, Discipline, Examination-mode, Mark)
For Example the first table is named STUDENT because each row represent facts about a particular student entity. The column names specify how to interpret the data values in each row, based on the column each value is in. All values in a column are of the same type.
In relational model terminology, a row is called a tuple, a column header is called an attribute, and the table is called a relation. The data type describing the types of values that can appear in each column is called a domain.
4.1.1. - The Mathematical Concept
The relational approach is based on the mathematical theory of relations. This clearly provides a sound theoretical foundation. On the other hand, it is perhaps slightly unfortunate that the terminology employed is taken directly from the theory, so that in some places the user is faced with having to learn new terms for familiar concepts.
In mathematics the term relation may be defined as follows:
Given sets D1, D2, .. Dn (not necessarily distinct), R is a relation on these sets if it is a set of ordered n-tuples (d1,d2,..,dn) such that di belongs to Di for i belonging to the set . Sets D1, D2, .. Dn are called the domains of R. The value n is called the degree of R.
Example:
PART ( Code, Name, Color, Weight)
COMPONENT ( Major-code, Minor-code, Quantity)
The significance of a tuple of the relation COMPONENT is that the major-part includes the minor-part in the indicated quantity as an immediate component.
Relations: PART , COMPONENT of degrees 4, respective 3
Domains: Code, Name, Color, Weight, Quantity
It is important to observe the following restrictions:
No two rows (tuples) are identical
Each relation has an identifier (PRIMARY KEY) that consists of any number of domains (qualified by role name if necessarily), from 1 to n (the degree of the relation). We assume that the primary key is non-redundant (none of its constituents is superfluous for the purpose of unique identification
The ordering of rows (tuples) is insignificant
Both these points are consequences of the fact that a relation is a set
The ordering of columns is insignificant, but once established the order must be maintained during all live time of the relation
Every value within a relation (each domain value in each tuples) is an atomic (non-decomposable) data item (e.g. a number or a character string). In other words at every row and column in the table there exists precisely one value, never a set of values.
A relation satisfying this restriction is said to be normalized.
The relational model can be defined as a user view of a database as a collection of time-varying normalized relation of assorted degrees.
There are the following correspondences of terms in the traditional terminology:
Relation - Homogeneous File
Domain - Single-valued Field
Tuple - Data Model Record (Occurrences)
Example:
RELATION SUPPLIERS (Code, Name, City) KEY (Code)
RELATION ORDERS (Supplier-code, Part-code, Quantity) KEY (Supplier-code)
4.1.2. - Domains, Tuples, Attributes and Relations
Domain
A domain D is a set of atomic values. A common method to specifying a domain is to specify a data type from which the data values forming the domain are drawn. It is also useful to specify a name for the domain, to help in interpreting its values. In general to each domain can be associated a lot of limits for the included values. Some examples of domains:
The Phone-number in a Romanian town - The 6-digit numbers valid in that town
Name - The set of names of persons
Employee age - Possible ages of employees of a company (a value between 16-80 years old)
Academic departments - The set of academic departments in a university (Electronic, Computer-Science, Electrotechnic)
Additional information for interpreting the values of a domain can also be given, for example the units of measurement.
Attribute
The name of a role played by some domain D in the relation R is called ATTRIBUTE Ai. D is called the domain of Ai and is denoted by dom (Ai).
Tuple
A n-tuple t is an ordered list of n values t = ( v1,v2,..,vn) , where each value vi, i belonging to , is an element of dom (Ai) or is a special null value.
Relation
A relation can be described by names or by values. These two descriptions correspond to the two levels of abstraction: LOGICAL and PHYSICAL.
Relation Schema
A relation schema R , denoted by R (A1 , A2 , .. ,An) , is made up of a relation name R and a list of attributes A1 , A2 , .. ,An. A relation schema is used to describe a relation. The degree of a relation is the number of attributes n of its relation schema. The term relation intension for a relation schema R is also commonly used.
Relation Instance (Relation)
A relation or relation instance r of the relation R (A1 , A2 , .. ,An) , also denoted by r® , is a set of n-tuples r = . The term relation extension for a relation instance r® is also commonly used.
The above definition of a relation can be restated as follows:
A relation r® is a subset of the Cartesian Product of the domains that define R :
r® ( dom (A1) x dom (A2) x .. x dom (An) )
4.1.3. - Representing Data in the Relational Model
In the relational model we can represent data that describe ENTITY SETS and RELATIONSHIPS among ENTITY SETS:
An ENTITY SET can be represented by a relation whose relation schema consists of all the attributes of the entity set. If this entity set is one whose entities are identified by a relationship with some other entity set, then the relation schema also has the attributes in the key for the second entity set, but not its non-key attributes. Each tuple in the relation represents one entity in the entity set.
A RELATIONSHIP among ENTITY SETS E1 , E2 , .. , Ek is represented by a relation whose relation schema consists of the attributes in the keys for each of E1, E2, .. , Ek. We assume, by renaming attributes if necessary, that no two entity sets have attributes with the same name. A tuple t in this relation denotes a list of entities e1, e2, .. , ek, where ei is a member of set Ei , for each i . That is, ei is the unique entity in Ei whose attributes values for the key attributes of Ei are found in the components of tuple t for these attributes. The presence of tuple t in the relation indicates that the entities e1, e2, .. , ek are related by the relationship in question.
Example 1
STUDENT-HOSTEL (Code * , Address , Administrator )
STUDENT (Student - Number * , Name , Surname , Class , Hostel )
* Symbol for KEY component
STUDENT
|
Student-Number |
Name |
Surname |
Class |
Hostel |
|
sn 1 |
n1 |
s1 |
c1 |
hc1 |
|
sn 2 |
n2 |
s2 |
c1 |
hc2 |
|
sn 3 |
n3 |
s3 |
c1 |
hc1 |
|
sn 4 |
n4 |
s4 |
c2 |
hc2 |
|
sn 5 |
n5 |
s5 |
c2 |
hc1 |
HOSTEL
|
Code |
Address |
Administrator |
|
hc1 |
a1 |
ad1 |
|
hc2 |
a2 |
ad2 |
|
hc3 |
a3 |
ad3 |
student sn I live in hostel hc j
Example 2
PART (Code *, Name, Color, Weight)
COMPONENT (Compound *, Component *, Quantity)
Example 3
EXAM (Discipline *, Examination-Mode *, Teacher *, Student *, Mark)
4.1.4. - Operations on Relational Databases
There are two kinds of operation by witch the data in databases can be manipulated:
UPDATE OPERATIONS
INSERT operation - adds a tuple to the relation (a record to the corresponding file) after verifying the new tuple is unique in the relation ; this can be prove by the unique value of the primary key
DELETE operation - deletes from the relation the tuple that have the same values for the primary key as the values that were be introduced
MODIFY operation - replaces the new values in the tuple identified by the primary key values that were be introduced ; because the tuple is identified by the primary key values, this values can't be modified, only by sequence of a DELETE and an INSERT operation
RETRIEVE OPERATIONS
The interrogation of a database consist of answer a question that contains a expression that must be verified by the tuples in the relations of the database. To implement a such query we must scan the tuples from the relations of the databases and retained the tuples that verifies the expression. In this procedure we can inspect more that one relation. The process of following logically connected data from relation to relation in order to obtain desired information is called NAVIGATION.
The location and the transfer of data in an X-BASE DBMS environment is briefly represented in the following figure.
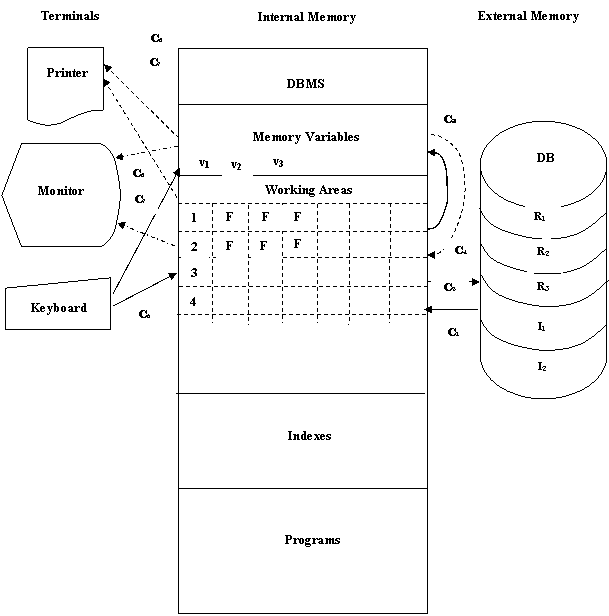
Commands C1 - POSITIONING C5
- GET + READ C2 - FLUSH C6
- SAY + READ C3 - ASSIGN VALUES (=) C7
- PRINT DISP LIST C4 - REPLACE
Fig. 2. - Data Flow in a X-BASE DBMS
4.2.1. - Data Fields
There are two kinds of data fields:
- Database fields
- Memory fields
The fields are qualified with the work area name (alias) for the database fields or with the letter M or m for the memory fields as follows:
allias.field-name
M.variable-name or m.variable-name
4.2.1.1. - Databases Work Areas
The database fields can be retrieved in the work areas. FoxPro allows you to open and manipulate files in 256 work areas. Work areas can be identified with the letters A through J for the first 10 work areas, the numbers 1-256 or by the database files alias if a database file is open in a work area. You can reference a work area before using the work area letter or number opens a database file:
- SELECT A
- SELECT 1
The last selected work area becomes the current work area. This is the active work area that are implicit referred.
To open a database file in a work area other the current work area, you must specify or select the work area. When a database file is opened, an alias witch it can be identified gives it. Unless you specify otherwise, the database file alias is the name of the database file (excluding the .DBF extension). To open a DBF you must issue the command USE:
USE [ < file > | ? ] [ IN < work area > ] [ ALIAS < alias name > ]
The USE command opens a database file in the currently selected area. If USE is issued without a DBF name the DBF opened in the currently WA is closed. A DBF is also closed when another DBF is used in the same area.
You may open a database file in an unselected work area by including the IN < work area > clause.
You may close a database file in another work area by issuing USE without a file name and including the IN clause.
The optional ALIAS may be used to create an alias name for the DBF opened with USE. A DBF may be referenced by its alias in commands and functions that required an alias, work area or DBF name.
When a DBF is opened with USE the DBF is automatically assigned an alias - the alias defaults to the name of the DBF.
There are two kinds of database file alias:
- User Assigned Alias
- System Assigned Alias
4.2.1.2. - Memory Variables
The Memory Variables help us to store data from database or entered from keyboard. If memory variables have the same name as a database field name the system always gives the field precedence over the memory variables if an express qualification didn't be made. The memory variables have a dynamically data type. This data type is taken from the data witch is stored last time in the variables.
4.2.1.3. - Display Fields
Display fields appear on the display screen. These all are memory variables or database fields that are transferred to the screen
4.2.2. - Navigation in Tables
4.2.2.1. - Cursors
The system dispose on an internal identifier of the records (the RECORD NUMBER) that is automatically updated from the system. This data can be interrogated with the system function RECNO ( ) but can not be modified by the user. The system dispose on an internal system variable that stores the CURRENT RECORD NUMBER that is the record that is referred by the system at a given time.
The positioning of the cursor in a DBF can be made as following:
select the DBF with the command SELECT
select an record by:
scanning with the command SKIP
searching with the command FIND or LOCATE
addressing with the command GO TO
4.2.2.2. - Inspection Order
The inspection order is given physical, by the chronological insertion order of the records in the database files, or logical by the order that is stored in the associated index.
The commands:
- GO TO
- SKIP n
- SCAN scope
The scope permits to define a record RANGE. When a scope clause is included in a command, this command acts on a range of records in the database. The following clauses are available:
ALL - all records in the database
NEXT (exp N) - n records beginning with the current record and continuing for the specified number (exp N) of records
RECORD (exp N) - the specified record number by the record number as (exp N)
REST - all the records beginning with the current record to end of file
FOR (exp L) - each record in the database file that meets the specified logical condition
WHILE (exp L) - each record in the database file that meets the specified logical condition until the condition become false
|
