In the previous chapters I have described theories of human mind; how we sense, feel, and behave. The agent models I have described are all attempts to realistically reproduce some human abilities and within their field the results are quite nice. However to produce believable agents it seems that all you need is a good animator. To model interesting characters you really only need a set of predetermined animations and then play them at the right time. This is the case with many computer games (for instance The Sims [51]) where the visualised behaviours are only predetermined animations . The tricky part is that I want to have agents that both seem believable and act autonomously in overall behaviour as well as in location or object specific interactions. That is: my system should not just be some underlying motor that determines what task should be performed by what agent and then the graphics engine is left to sort out how to represent this. The reason for such a demand is that my agents should be able to follow opportunities anywhere at any time and try to achieve several goals at the same time.
To state such a thing is easy, to do it in practice is another matter and you will see in the following that some of my solutions indeed are inspired by a division between graphics-representation on one hand and agent-engine on the other.
Most agent models and theories are confined to a small area of the subject of believable agents. Most models present one part of a system and assumes either that the rest will follow easily or that their sub-system is general enough to fit in anywhere. Perhaps they are right but in lack of self-confidence it is very important for me to show that the theory and agent model may be used in practice. Therefore the implemented system is a major part of this project and has taken more than half the available time.
I chose to use the Will-model as a basis and the project has then evolved around that. The Will-model is designed from what Moffat and Frijda calls Occam's Design Principle: keep it as simple as possible. I try to do the same. Firstly the modular structure of the model is to be kept so that I may focus on one thing at a time. Secondly the model as a whole should be kept as simple as possible. This means that parts of the model are kept general and rather extended a bit than new ones emerge. This has mostly an impact on the structure of the source code and I shall not discuss that in this text. Besides, the system has been made slowly and continuously and therefore lacks a lot of clarity on how the code is structured. This is why I have left out copy-paste code examples. If you are interested in source code it is included on the CD-ROM (see appendix B).
To keep the ideas of the Will-model it has not always been possible to adapt the theories described in the former chapters. For instance the solution to equipment usage was firstly investigated in what theory I could find after which I sat down and thought many different solutions through. The final result is a mix of these things.
The system is based on my previous work on swarm intelligence but the agent model in this case is completely new.
The criterions for the design are that the system should have real-time performance and that it should be fun to look at for at least half an hour. Further it should show all the features that have been implemented. I will describe such an example at the end of this chapter.
Besides that the agent model is modularised the system as a whole consists of larger parts. There is the 3D-system that handles graphics, a standard agent model, a standard interface module, and a standard game module, an extension to the agent model, and environmental elements such as objects and locations. To keep focus I will only briefly mention other parts of the system than the agent model and environmental objects.
In this part of the text I describe my agent model. Firstly I describe the physical aspects of the agent: how does he look, that joints does he have, how does he appear, and so on. Secondly I describe the mind of the agent, or what is normally referred to as the agent-architecture.
The Will model only describes the mind of the agent and not the body. The idea Moffat and Frijda have is that the body and physics of the agent is only a minor element on the barrier between Will and the world -the dotted line in Figure 8. The model is presented mostly in theory and the implementations that I am aware of are fairly simple: they describe a Will-agent that plays a game with the user.
Here I take action and give my solution on how to integrate physics into the will architecture. However I do not go deeply into detail firstly because I in a previous project [1] have described many of the ideas and secondly because it would be boring and double the amount of text. However I find this section important because it explains what kinds of things the agents are able to do in their world and because the mind of the agents are influenced and may influence their physical (and graphical) states.

Figure 16 , a picture of the standard agent.
The standard agent is shown in Figure 16, above. He consists of several parts each represented by a geometric shape: head, body, arms, hands, and feet. The agent has no legs. Each bodily part is an object of its own or a particle as I will call it. The agent as a whole is also such a particle. A particle is the simplest physical unit in the world. I may have a position and rotation in space plus kinetic energy and weight. If a particle is placed in the world it will fall and move according the physical laws. A particle may also be solid which means that it cannot pass through other objects and/or the other way around. A physical particle has some characteristics that determine its volume, elasticity when it hits a surface, and wind resistance. In theory this means that if an agent's head was chopped off it would fall and roll away. In practice it means that the agent always stays on the ground and all his limps hold records of their own positions. Particles may also have some movement constraints. For instance, the head is not allowed to be turned backwards. This is the basis for joint movement. As each body part is a particle they are allowed to move around as they like, the movement constraints may then keep them from "falling off". Under certain conditions the environment may restrict joint movement, 141b12b for instance if the agent is carrying something. I return to this in the section .
All movement in the system is determined by the kinetic energies. Here I have movement in mind: to get an agent to move one has to change the position of his feet in order to create kinetic energy based on the friction between feet and ground. Then the physical laws will do the rest. This also means that the graphics and physical representation have direct consequence for the agent's mental states. In other words it is impossible just to have an underlying agent model and some more or less random animations on top. The reason that I chose this design was my naïve idea that it would make the movement more consistent and for instance avoid "skating" agents. However many new problems where introduced so you still experience "skaters" among the agents.
The agent's different kinds of movement are predetermined schemes of animation. For example, to walk is equivalent to wheeling the feet about in a circular motion and swinging the arms as shown in Figure 17 below.

Figure 17 , agent with wheeling feet and swinging arms.
There are a whole set of movement patterns including eating, dancing, playing piano and so on. I call these motor skills as to emphasise that they are the agent's abilities to move in certain ways. As all agents are almost physical alike they are all able to move in the same ways: they all have the same motor skills.
There is nothing sacred about motor skills. They are simply animation patterns and it shows that new ones have to be designed all the time to accommodate new kinds of behaviours. Some would claim that motor skills should be evolved by the agents themselves or figured out like you would decide what behaviour to display [47]. To make such a system would simply be too much work in my case and perhaps move the attention away from the subject.
The walk pattern is one of the simpler: it is a never ending monotone circular motion that may be described by the equations below.
|
Left foot:
|
Right foot:
|
This simply describes two ovals drawn as
the variable counter moves from 0 to
2![]() . The ovals are 0.5 units long and 0.15 wide like the one in Figure 17a, shown above. The "
. The ovals are 0.5 units long and 0.15 wide like the one in Figure 17a, shown above. The "![]() " that is included in the left equations separate the two
feet with half a turn. If we see counter
as a real number that grows with time then the feet would change positions as
the wheeling motions described. The lower foot would then create kinetic energy
as it is pushed backwards and the agent is then moved forwards accordingly.
" that is included in the left equations separate the two
feet with half a turn. If we see counter
as a real number that grows with time then the feet would change positions as
the wheeling motions described. The lower foot would then create kinetic energy
as it is pushed backwards and the agent is then moved forwards accordingly.
Every time the counter described above reaches a multiple of 2![]() the agent has completed another step and thus how fast the counter grows determines how quickly the
agent walks. Sometimes things are timed due to external events and other times
agents should just be allowed to do things in their own tempo. In a dancehall
agents should keep the rhythm but mostly we would expect them to walk and eat
in their own phase. The system uses three kinds of counters that all run from 0
to 2
the agent has completed another step and thus how fast the counter grows determines how quickly the
agent walks. Sometimes things are timed due to external events and other times
agents should just be allowed to do things in their own tempo. In a dancehall
agents should keep the rhythm but mostly we would expect them to walk and eat
in their own phase. The system uses three kinds of counters that all run from 0
to 2![]() and then loop:
and then loop:
Counters have been elaborated in the previous project .
As foot movement is described with a cyclic equation so are all other motor skills. The equation below is the generalised movement equation:
![]()
where V is the new computed value. C, Ccosarg and Csinarg are constants, which are added in the equation. Mx, Mcos, Msin, Mcosarg and Msinarg are constants that are multiplied in the equation. The identifier x is a variable that is associated with one of the three timers.
I chose to base the animations on cyclic movement because of the natural joint movement of human limbs: naturally a limb will swing from its joint and slow down before it changes direction.
Not all motor skills are as simple as walking. Nothing needs to be changed to include movement of other limbs but to break up sequences of movement and combine them we need to time the patterns to the counters. This could be the movement of a dance with several different steps or additional events, say every minute an eating agent will burp. The solution is simple: every movement equation is given a time span and references to one or more of the counters. Only when the counter is within this time span the equations apply. For example, the "eat and burp" motor skill could have the following scheme:
|
Individual counter within [0 ; 2 Global counter within [0 ; 0.5], do burp motions (and sound) |
The result is that the agent always eats and once every minute burps for about 5 seconds. However all eating agents will burp at the same time but this is just an example, spontaneous burps are regarded as future work.
Motor skills do not have to be repeated in a monotone loop. They may stop after some given time either specified by the motor skill or specified by the agent at run-time. For instance, if the food is eaten up the agent may himself send a stop signal to the eating skill.
Lastly, the equations of the motor skills should be regarded only as guidance for the agent's movement. To avoid jerky motions an amount of equalising is done between the prior positions and the new ones. This ensures a smooth animation.
The agents may look a bit different to show their status and roles through the cloths they wear and they may also display emotions and other visual gimmicks. The appearance is a physical feature but is influenced by the agent's mind as well. A very angry agent might set the appearance of his face to an angrier texture and turn up the colour of red in his skin. This is the case in Figure 18 where a variety of agent appearances are shown.

Figure 18 , variety of different agents.
Appearance is a purely graphics element and has nothing to do with how agents see each other. The purpose of appearance is to make the agents more believable to the human observer so we may get an idea of what kind of person an agent is and what state he is currently in. Obviously no one would be fooled into believing that these agents are humans but this is deliberate in the best "Dautenhahnian" sense: she claims that things should not be too realistic to avoid the uncanny valley [29]. Admittedly I have no chance on reproducing realistically believable humans so I am better off aiming at these cartoon-like characters.

Figure 19 , agents with equipment. Left: a lady with a pool-cue. Right: an angry man with a plate.
The agents are also able to possess and carry equipment as illustrated in Figure 19. The first image shows an agent carrying a pool-cue in his right hand. The agent is able to carry equipment in his hands, on the back, and on the head. It is only possible to carry one thing at each position at a time. As you might see this is quite simple in the current version and it is a prime candidate for future work to enhance equipment handling capabilities.
In Figure 20 below the entire implemented agent model is displayed. In this part of the text I describe the concerns and go through each implemented module one at a time. You may use Figure 20 below to keep an overview.

Figure 20 , the entire agent model.
As in the Will-model [16] my agent's mind evolves around the concerns. In the Will-model the concerns lie as a layer around the memory, see Figure 8 (page ). In this partition the concerns are what the agent cares about and the memory in the agent's current state. When modules want to read or change the current state they then have to be matched against the concerns first. In my model the principle is the same, however the partitioning has disappeared now the entire bobble illustrated below including the memory is called the concerns.

Figure 21, the concerns in detail.
The concerns may be seen as the central nervous system that combines different cognitive brain activities. In some respects it may be viewed as a large blackboard the brain modules may use to communicate and store data. Central to the concerns is that it does not have any cognitive processes. It might emit some few signals to the physics or reject input when out of memory but otherwise the concerns are a completely passive part of the agent's mind. The concerns do their influence through the structure as it is a collection of formatted data by convention assigned for each their purpose. In this way the concerns control how the modules may communicate and cooperate and it will be evident that direct module-to-module communication is impossible. This ensures that modules are not dependent of each other as is one of the design criteria.
If anything is, the memory is the most important part of the agent's mind however memory is a very bad name for this. The memory in the concerns is a long array of real numbers and the purpose of the agent's existence is to have as high values in the memory as possible. This also means that the memory is not what remembers past events, if the agent should have such abilities a "remember" module could be made. Therefore the memory ought to have been called "concerns" if not that name was already spoken for[1].
An entrance in the memory array could for instance represent hunger. A human would see that the lower a value the hungrier the agent is. In contrast, the agent does not see this as the memory has no labels (visual for the agent at least). He only registers that one of his values is low, nothing more.
We would expect a hungry agent to prefer actions that lead to eating of food. This happens as a side effect of how actions are chosen. The agent weights the possible actions due to what goals they claim to fulfil. A diner-location for instance has a goal that includes hunger satisfaction and thus a hungry agent will weight actions with this location heavier. I return later to precise what a location is (5.3.1).
If you ask the agent, he is not aware that he is eating something, he is simply trying to fulfil his need: get high values in his memory. Compared to the whole discussion of consciousness in chapter 2, you might claim that the agent is conscious from a functionalistic perspective but then he would be conscious about very different things than a human. A human would enjoy satisfying his hunger due to the knowledge that he has been hungry for some time. The agent on the other hand does not sense the relief of satisfying a need.
It comes down to how memory as such is handled. In general memory is any available data that tell about the agent's current state or previous ones. That includes almost all available data both internally and outsides the agent. The external data may also be perceived by other agents and thus by changing the environment the agents also interact with each other. This was the case in the former described ant-navigation (2.3.1) and Nishimura and Ikegami's approach to social interactions where the positions of agents influence their actions ( ). So, some data is seen by everybody and some is kept internally in the brain either as a part of the concerns or as local states in the modules. In my system the agents have some shared memory: the navigation relies on a one single Q-learning system where the agents read and change the data much like on a blackboard. This has been done to simplify the agents and give quicker convergence of the Q-values. Navigation is further explained in .
Besides this external versus internal representation, memory may be partitioned into two:
In my project the concept of memory is not as clear as one could hope but with this partition into conscious and unconscious parts of memory a distinction has been made between the data presented in the concerns and the data in the modules. The memory-part of the concerns should then be seen as what needs the agent consciously feels.
The complexity of the individual agent is kept low with the shared navigational data but in a future project each agent could have his own navigational Q-values.
Goals are the nerve in action selection. A goal is a list of what entry in the memory it influences and how it does this. Below is listed the main properties of an element in a goal:
|
Reference to memory entry Claimed influence Actual influence: how to compute and where to find the values |
The claimed influence and actual influence does not have to be the same. A fancy restaurant might claim to have really high hunger satisfaction but actually serve less food than the burger bar across the street. The actual influence includes several different modes for a goal that decides how to calculate it. The weight of a goal is calculated as this:
|
weight=0 For each entry e in the memory: weight = weight + (claimedValue - eValue)/2 |
The variable claimedValue is the value of the claimed influence at the current entry in memory. The value of eValue is then the agent's actual value in his memory at the current entry. After the procedure the weight is the combined difference between the agent's memory and the values claimed by the goal. In this way the agent does not distinguish between what concerns are satisfied only that they are it.
When a goal-related action is preformed the agent then updates his memory as this:
|
For every element in the goal: eValue = eValue + (goalValue - eValue) * timeFactor |
The variable eValue represents the agent's actual value at the memory entry corresponding with the current goal element. Then goalValue represents the actual influence value of the goal, how good it is at satisfying the needs. The timeFactor is a combination of how fast the agent should adopt the satisfaction and the actual update rate. It is obvious that the satisfaction is not linear -in contrast it looks as the graph below where the change is larger with larger difference between the goal's value and the agent's actual value in memory.

Figure 22, a typical pattern of the memory-value as the agent satisfies it.
The agent has a physical appearance as described above but it is his presence that determines how other agents perceive him. The presence is basically a set of goals that describe what benefits other agents may get from this one and how to achieve this benefit. An agent might for instance have the presence that he is good at satisfying anger and to do this you should hit him.
The presence is not controlled by any single component. Like the rest of the concerns any module may change the agent's presence as they see fit and in all it is up to the designer what conditions should yield what presence. As explained in the theory in the previous chapters we do however expect a relationship between appearance and presence: an agent in police uniform might not be the best subject for an assault. On the other hand, presence and appearance does not necessarily have to be connected. Scent for instance, as describe by [8] is not visible and some small signals such as heart pulse-rate might hardly be noticeable or at least impossible to graphically model.
The agents are able to send signals to each other. That is when one agent deliberately wants to contact another agent. The agent then sets a signal in the other agent as a one-way communication. The signals are thus special as they are passively perceived information.
Signals are used when agents cooperate or interact with each other. For instance before one agent attacks the other he will send a signal to the victim and if the victim sees the benefit in it he will defend himself. Interaction among agents is explained later (5.2.2.8).
The agent is able to plan sequences of
different actions and produce sub-plans if opportunities arise. I have
described some approaches on how to model planning: Chen et al. [30] for instance have only one plan in memory at any
given time then sub-plans are mostly a matter of coincidence when a previous
plan is reselected. In the
The agent I present plans very much like the PECS-model agent but with a major difference. My agents are allowed to have several plan-sequences organised as sub-plans of each other. A plan-sequence is basically the same as the PECS-plans with the difference that these sequences of actions may be build up and torn down in a stack-like manner. A typical plan-sequence over time could be:
|
Event |
Plan. |
|||
|
Hungry |
Be at diner | |||
|
Not at diner |
Be at diner |
Go to diner | ||
|
At diner |
Be at diner | |||
Read from above and down the agent is firstly hungry and chooses to be at the diner, then he realises that he is not at the diner and walks there. The scheme should then be understood as a stack laying down where the rightmost entrance is the current action. Once at the diner the agent reacts on the possible ways to satisfy hunger, which is explained later. This might yield a new action on the stack or a plan-entry as I shall refer to the squares:
|
Reacts at diner |
Be at diner |
Eat at table |
This might even solve the pool-cue problem described above: if the pool-cue is missing this action could be popped off the stack and the agent would still remember that he wants to play pool.
Every action has a goal that determines how appealing it seems to the agent. In the above diner example it seems only reasonable that walking to the diner should have the same importance for the agent as being at the diner. If the weight of walking to the diner is less than being at the diner, then the agent would have no reason to move into the right location and he would never get anything to eat. If the weight of walking is larger than being at the diner then the agent might choose instantly to leave the diner as he reaches it because something else is more attractive. An agent who wants to play pool needs a pool-cue, which may lead to a new sequence of different actions. If the agent somehow fails to retrieve the pool-cue we expect this entire new sequence to be re-evaluated but not the original bit. The point is that some actions are naturally considered a sequence and others are not. Even though it is possible to model this in a single stack of actions things becomes much easier when we introduce sub-plan.
Instead of just having one plan-sequence the agent has a stack of plan-sequences. The entries in this stack each represent an alternative plan-sequence so I call them sub-plans. In practice we have a two dimensional schema of plan-entries as this:
|
Be at saloon |
Play pool |
Go to pool-table |
|
|
Pickup pool-cue 1 |
Go to pool-cue |
|
|
|
Talk with agent 8 |
Turn towards agent 8 | ||
|
Pickup pool-cue 3 |
The rows represent the plan-sequences and from the top and down the sub-plans are shown (the lower the more resent). The action we would expect the agent to perform is then the lowest rightmost action, in this case "Pickup pool-cue 3". An extra column has been added at the left, which shows the actual weight of each sub-plan. We see that the last sub-plan has weight less than a prior one. This means that the agent is about to do something that is not the current most attractive plan-sequence. The sub-plan will then be deleted automatically and the agent will turn towards "agent 8". Even though the sub-plans above the active sub-plan have less weight they are not deleted because we don't know what the situation is once we have finished talking.
Conclusively any module at any time may add as many sub-plans as they wish. If they show to have the most weight the agent will execute them. If they are placed above a larger weight the agent will remember them for later evaluation.
I have described the problem of oscillation and how the different presented models deal with it in 3.3.3. In short oscillation is when the agent changes actions very quickly because once he has satisfied just a little bit of his concerns (the memory values) something else has higher priority.
Frijda uses a boredom-function: that is roughly a timer that determines when change of actions is possible. I initially tried this approach but it worked badly as the agent either needs some leaning abilities to determine the rate of boredom or the designer has to be a very clever guesser.
Velásquez [26] just hopes oscillation does not occur too often. This approach was easily tried out in practice but unfortunately oscillation does occur severely in my agents.
Chen et al. [30] records when a goal-satisfying action begins to be executed and then remembers the weight at this time. From then on they compare other sub-plans' weights to this initial value. Neither this works in my model because two equally weighted sub-plans still provoke oscillation. However it inspired me to a bit similar solution that seems to be working fine. As Chen et al. the agent records when an action is selected for execution. Then the weight of this sub-plan is multiplied by 2 as long as it is still chosen as the sub-plan for execution. The multiplication is not commutative. In this way the chosen sub-plan is always given a "head start" of the competing sub-plans. When a weight in multiplied it then of course matters how great the weight is. A small weight (near 0) only gets very little bonus from the multiplication by 2 but a small weight also resembles a quite content agent and he should be allowed to oscillate around if he feels like it. On the other hand when the agent gets unhappy the weights will be large and the bonus equally large. Thus he will naturally use more time doing one specific task right and then go on to the next one.
The system is not completely foolproof as agents sometimes get stuck with one action for an unreasonable amount of time. In future work the multiplication factor might itself be subject of some boredom-function or the like.
In the pool example the agent needs a pool-cue before he can play. What happens is that the action of playing pool has the requirement that the agent should be equipped with a pool-cue. The agent adopts this requirement and the reactor-module, explained below, sees opportunities in the different equipment around. Requirements work much like the memory-values: when missing it has high priority to fulfil the goal. The special thing is that requirements also hold some parameters to which kind of equipment the agent should be looking for.
If the agent has a perceiver-module its assignment is to sense the surroundings. Even though the agents are drawn with eyes this is not how they see. Instead they sense obstacles in a small radius around them much like Batchelor's ants [49]. Obstacles and what they are is then written to the agent's concerns so other modules may react on them (or perhaps change them).
Every agent and every object in the world has its own id. An agent is always able to sense this id and thus is able to distinguish between the other agents even if they look alike. This is a fundamental part of how the model works as it is used in interaction among agents and collision detection.
If the agent bumps into something, this is also registered but it is up to the modules to react on it.
The environment should not be seen as the direct input from the surroundings but more as how the agent believes the environment is. The data format of the environment does not only hold what is nearby but also how confident he is in this information. If the agent bumps into a wall, for instance, he will be pretty sure that the wall is still there even after bumping into it and he will hopefully try to walk around it. On the other hand, if the agent bumps into another agent he cannot be as sure because the other agent might itself be moving. This kind of information is for example used by the navigator described later (5.4.3).
Lastly, the agent has some data about his actual state such as which location he wishes to be at and what he hopes to be doing. This information is used by the navigator and by the navigational Q-leaning to find the right direction and by the reactor-module to refer to things in the world. In other words the actual state is the agent's referential abilities.
The perceiver registers the surroundings and updates the environment in the concerns. When an object is registered the perceiver determines where and what it is. Then it calculates how much the thing is believed to block as mentioned above: a wall blocks a lot and an agent less. Besides this the perceiver interprets the information and assigns blocking values to the areas just around the blocking object. This is to accommodate for eventual movement or keep distance to corners.
As in the model now the perceiver is quite simple. It senses only thing nearby and does not use any other information about objects than their position and kind. In future work the perceiver might be extended with some attention theory as described in 2.3.3 so it is able to predict movement, focus on regions, and see further than beyond nearest reach.
As the name suggests this unit handles execution of the plans. This is the unit that firstly cleans up among the sub-plans deleting any that is placed below a heavier one. Then it selects the bottom rightmost plan-entrance and evaluates it in 5 steps.
Without the executor module the agent would never get to do anything and therefore it is a basic part of the model.
The planner takes care of overall planning activities. That are what kind of thing the agent currently wants to do. The planner may decide that the agent should be at the diner but how to get there and what to do there is not the concern of this module. This is in correspondence with Frijda and Moffat's view of this module [16].
Mostly the planner is passive as the weight of the current actions are heavier than the beneficial weight of other locations but sometimes it wakes up and decides that the agent should try something completely new. Then it deletes the entire plan in the concerns and add only what new location should be considered. Consider for example that the agent is currently looking for a pool-cue at the bar. At some point the agent has become so hungry that despite the multiplication bonus (5.2.2.1.4.2) it would fulfil the concerns better to visit the diner. Then the planner-module deletes everything currently planned and tells the agent to be at the diner now.
At a specific location determined by the planner the agent reacts on what to do. For example, once at the diner the agent may choose between sitting at a table and eating or perhaps take some of the buffet. This works as all possible actions are signalled by their respective objects, called posts (see 5.3.1).
The reactor also inspects if there are any requirements for equipment. If this is the case all present equipment, including that possessed by others, are tested if they hold any of the requested abilities. All pieces of equipment that do, is added to the plan as each their sub-plan. It would not be sufficient just to add the most attractive (heaviest) piece of equipment as any other module may delete or change the plan. As an example: the reactor tells the agent to pickup any existing pool-cue sorted by the most attractive first. Then some other module inspects the plan and finds that the most attractive pool-cue is owned by another agent and therefore deletes the sub-plan. If the second best pool-cue had not been added by the reactor then the agent might never get a pool-cue.
The physics-module is the counter piece to the executor. As the executor-module sends request to the agent's body telling it what to do the physics-module should be considered as where the body is allowed to tell its needs to the brain. In practice the physics-module keeps track of the different memory-values and changes them over time. To do this the values in the memory need to have a reference to what needs they stand for. This is done with a mapping function so that the designer may refer to the same place in memory every time he wishes to inspect "hunger" for instance. Note that the agent does not know of this mapping function, it is only a tool for the designer. With the mapping function I then decide what needs the agents should have. In the current model I have chosen "hunger", "tiredness", "boredom", and "filthiness" but how many or few does not matter. What matters is that I use the same mapping function when I design the locations and in this way can model that the diner is good against hunger as an example. The module then evaluates these needs as time goes and in all cases I model that the values naturally decline so the agent slowly becomes hungrier, more tired and so on all the time.
In the current system the physics-module also holds the "aggressive/happy" state. Perhaps such data should be placed in a mental-state module but it would just be a copy-paste of the physics-module.
So far the modules I have described, except the physics-module, are suggested by Frijda and Moffat in the Will-model. An agent that only has these modules would be able to work just fine. However it seems a bit odd that the agents never communicate or have otherwise relationships and without any morale and sense of ownership the agents all end up with things that most certainly don't belong to them. Therefore I have implemented 3 additional modules to handle morale, cooperation, and social relations among agents.
The morale module is quite simple and only has the function to avoid that the agents steal (too much). The module constantly inspects the current plan and if this is to interact with an object that is owned by another agent then the plan is deleted. So agents never rob the other agents.
Some equipment is owned by a specific location. The agents are allowed to pickup the equipment and interact with it but we would expect the equipment to be returned when the agent leaves the location. As described above there is no warning sign from the planner-module when a change of location is about: the entire plan is simply deleted. Therefore the morale-module has its own state where it remembers what location the agent was at last update. If the current location is different then any equipment borrowed by the former location should be returned and the morale adds a sub-plan to return the equipment. The weight of this plan is determined by a "morale"-value in the memory so some agents may be more likely to steal than others. The result is that agents with low morale and agents with low memory-values tend to steal more often than content agents with high morale.
The co-operator handles interactions among agents, both one-way and two-way interactions. That could be agents that talk, fight, or dance for instance.
The module firstly inspects the perceived environment. If there are other agents nearby their presence is compared to the agent's concerns. As described above the presence is actually a set of goals that other agents may read and weight. The agent will not react on the presence as a whole but might only consider one characteristic. If the chosen characteristic in the presence has higher weight than the current plan, then he goes on establishing cooperation otherwise he stops inspecting the other agents. Included in the description of the presence is how to interact with the agent. The agent now knows which agent and what kind of interaction he should try to establish with him. He then produces an interaction-object. As described later, when an agent interacts with an objects it is the object that decides the more specific actions the agent should do. The interaction-object is then supposed to decide the actions of both implicated agents and thus coordinate their actions. The agent therefore sends a signal to the other agent including a reference to the interaction-object. To visualise, the protocol has been sketched in Figure 23 below.

Figure 23 , protocol for establishing cooperation.
The co-operator-module also inspects the signals received in the concerns. The signals are evaluated as if the sending agent was perceived as a part of the environment. The heaviest of both is then chosen and if they have the same weight then the signals win. When the agent reacts on a signal he only joins interaction with the interaction-object produced by the other agent. Then both agents are interacting with the same object and it will guide the two agents into cooperation.
From the theory described in 4.2.1 Thalmann suggests that groups can form from 3 things: explicitly programmed behaviour, reactive events, and leader agents. The presented approach to a co-operation-module is mostly compatible to the first: the interaction-object may be seen as a group-behaviour-skill that constitutes guidelines for group behaviour just as the motor-skills determines physical movement. There is no leader of the two interacting agents, if it seems that way it is due to the object's instructions and not the agent's will.
The co-operator-module has been designed only to support cooperation among two agents; my system does not support crowds. As each agent may produce an interaction-object it is though theoretical possible that the agents may chain up and produce crowds in this way. This has not been investigated further and may be considered future work.
The social-module is a mapping of memory-values like the physics-module. The system may include an arbitrary number of social hierarchies. That could be social status, authority, religious importance, and so on. Each hierarchy is represented by a collection of memory-entries large enough to possibly hold information on all the other agents. The values in these memory-entries represent how high or low in the hierarchy the corresponding agent is believed to be. Thus each agent has his own ideas of where in the different hierarchies the other agents are. He also has a value that determines where he believes himself to be in the hierarchy. One point is that the agents have no true position in any hierarchy.
To communicate social information is the difficult part and I will only give the idea here. Otherwise I wrote a paper on norms in which I present the social-module. Unfortunately it was not accepted but I include it in appendix A, not to have completely wasted my time. The paper describes in more detail how social communication such as gossip may be implemented in the system. The point is that the hierarchical data all have a very low claimed value (see ). Then these will not be selected for interactions. The agent's own value should as an exception be active for selection so that he may react on possibilities to increase (what he believes is) his social status. When agents communicate because they believe to gain status, the hierarchical memory-entries that the two agents disagree the most on is then chosen as conversation subject. That might be anyone of the agents' hierarchical values.
In all, one agent will be interested in gossiping with another agent that seems to have different status than him self. Then they will exchange data on the hierarchical position of the agent that they mostly disagree on. Thus the values may rise and lower according to what the other agents believes.
Lastly, agents never tell the truth: any hierarchical value that is communicated is exaggerated. If a very posh lady talks about a middle class guy she will say that he is a poor workman. The out-cast will say that the mall-guards are the supreme authority.
This is just one approach towards modelling social relationships. Another obvious solution was to keep hierarchical data only in the social-module to avoid the tricky part about the claimed goals versus the real changes. Future work awaits here.
The environment consists of a building containing various rooms. The building as such only has the purpose of confining the agents so that they won't run off. The roof of the building becomes transparent as the system starts so we are able to see inside and here the walls are partly transparent so we may keep the overview. A typical building is shown in Figure 24 below.

Figure 24 , building without roof.
In the building there are a set of locations. Locations are invisible areas but they typically align to the different rooms. A location is a living thing in the system: it is what defines the purpose of different areas and what to do there. For instance, a diner-location keeps track of when to open and close for visitors and signal to the agents if there are food available or not. An agent at a location will then be given something to do by the location. The diner might tell an agent to sit at an unoccupied table and wait for the waiter. Such assignments by the location has been standardised as posts.
The posts are what the agent's reactor-module sees once at a location and then chooses which one the agent should be assigned to. This depends both on what goals the post fulfils and if it is free or not. A post may never have more than one visitor at a time. Once the post has been chosen it more or less precisely tells the agent where he should be. A post might be at the dance floor and then it does not matter where on the floor the agent is. Other posts need far more precision if they for instance are part of a line up. At the post the agent will be told what motor-skill to perform.
There may also be connections between posts so that one leads to the other. In this way behaviour may be guided at the location. For example, a restaurant could have an initial post at the reception before they are sent onwards to other posts at the tables.
Posts may also be connected to an object. For instance, to sit on a chair at the diner this might happen: the agent enters the diner, he reacts on a post, and the post tells him to "sit" on a chair object. How objects work is described next.
As in The Sims ([51] and ) it is in my system the objects that determine how agents should interact with them. What the kind of interaction should be is determined by posts or the agent self.
And object has a set of possible interactions and if an agent tries to use the object in some other way it will reject him. There is a standard protocol for how objects and agents interact but besides this the objects are in fact independent programs within the system. The standard protocol is used by the agent to ask the object about different things like where to be, what motor skill to display, and so on. Included in the request the agent tells who he is and what kind of interaction he wants to do. The kinds of interactions are for instance: pass through, pick up, play pool, destroy, and on and on. Each object may have its own special interaction without that interfering with other objects. The agent is also able to see these interaction kinds and he is able to se the type of object: pool table, chair, for instance. The reactor-module uses this information when it searches for objects that fulfil some requirements.
An object also has an owner, who is an interacting agent with sole right to usage. As long as the object is owned by another agent it is not an interaction subject. It is up to the object who it will call its owner but if it is a one-agent-only object, like a chair or pool-cue the first interacting agent should get to own it. When the interaction stops or the object is dropped then the ownership is released again. Objects do not know if they belong to a location so when the morale-module registers objects stolen from locations it is because the location has a list of what object belong to it.
As most objects keep track of their owner some more complicated objects keep track of its users. A pool-table thus remembers who is playing and whose shot it is. The pool-table also calculates from where to take the shot and once performed evaluates the movement of the balls.
Lastly, objects have a set of joints that tell the agents how to carry them if they are picked up. Picked up objects, or equipped objects, also have some motor skill inhibitors that further restrict the joint movement of the agent. For instance, an agent that caries a pool-cue is not allowed to swing his arm as much as a normal walk requires because the tip of the pool-cue then would hit the ground.
When an object is design its type and functions are explicitly described. The agent however never realises what he is interacting with only what he can do or is told by a post to do with it. As explained in 2.2.2.4 Edelman gives great importance to how objects are categorised. In my case then agents directly into the functionality of the objects and so they need not categorise anything themselves.
In the system as is, there are implemented a small variety of objects that differ a lot in complexity. I believe the chosen objects will give an idea of what is possible when you run the CD-ROM example.
For the agents to find their way to the locations they need some kind of navigation. Further, for objects to appear solid collision detection is needed to insure that no agents occupy the same space at the same time. These two things have been investigated in previous projects [2] and and will only be out-lined here.
The world is divided into a grid with squares about twice the size of an agent. Each square keeps track of what is currently within it. The data written to the square by the agents are their unique id and solid objects also write their ids. In fact the perceiver-module only investigates the surrounding squares to see what are written in them. Collision detection is then simply a matter of blocking the agent from entering squares that are occupied by other things than him self. Figure 25 below shows a wire-frame screenshot where the occupied squares are shown as boxes around the agents and solid objects.
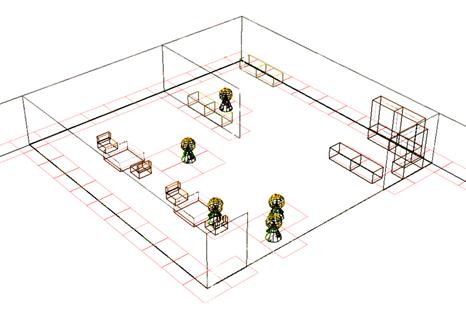
Figure 25 , wire-frame screenshot that shows the grid squares around the solid objects.
When an agent is interacting with an object he may request the object to "unlock" the blocking. If the object agrees it will let the agent pass into its square even though it is a solid object. This is why agents can sit at chairs. Much work still needs to be done to perfect this technique as we still see agents walking through objects in an odd manner.
Navigation is also based on the grid. For each location there is an extra grid map. Each square holds an arrow that points in what direction the agent should move to reach the corresponding location. The arrows are just guiding and the agent will in fact look along the path of arrows as far as possible until an object breaks the view. Then he will walk in the most direct path despite the arrows.
Firstly the direction of the arrows are estimated roughly by a fast branch and bound algorithm. Then as the simulation runs the agents change the directions of the arrows to be more like the actual path they have chosen. This is a kind of Q-learning where the angles of the arrows are seen as Q-values. The agents will never destroy the path but slowly optimise it and accommodate for new obstacles and situations.
Obstacle avoidance is a new part of the system. Its purpose is to keep the agent from walking into other things. One part of the obstacle avoidance is how blocked the agent believes the squares around him are as described above in 5.2.2.2. Another factor is how favourable the different squares are according to the optimal walking direction. Lastly the agent's current heading has influence on how he moves. For each of the 8 squares around him the resistance is calculated as follow:
|
resistancesq = avoid * curDirsq + (1 - avoid) * (optDirsq + blockingsq) |
Here resistancesq is the resistance of the square currently referred to as sq. The agent will conclusively rotate towards the square with the least resistance. The variable curDirsq is the difference between the current headed direction and what direction the square sq lies in. The angle is changed into a value from 0 to 1. Likewise optDirsq is the difference between the current square and the optimal angle towards to goal-destination. The value of blockingsq is then to what degree the agent believes the square is blocked where 0 is non-blocked and 1 is completely blocked. Lastly there is a variable called avoid that sets the relationship between the current direction and other data. If avoid is small then the agent will pay only little attention to his current direction. If the avoid value is very small the agent has a tendency to overreact on encountering obstacles. A high avoid value results in a slower reacting agent. It is very difficult for the system automatically to register what value is most reasonable as it is a matter of believability rather than optimisation. Therefore the value of avoid has been fixed at 0.25 in the current system.
A CD-ROM should be included with this text. See appendix B for technical information about the CD-ROM. The CD-ROM includes an executable version of the system I have described. It is a building with four rooms, or locations, each specialised to fulfil one of the agents needs.
When the program starts you are presented with six different characters. These are special characters you may include in the simulation run to investigate how different agents behave. Already there are several standard agents present in the simulation so you do not have to include any special characters. The characters and their personalities are:
When the system runs, you may inspect these characters parameters (see appendix B).
At the diner the agents satisfy their hunger. There are some tables placed against the walls just by the entrance, here the agents should pickup a plate (food source). Then they should find an empty table and sit and eat. After this the agents hopefully return the plates. If you select the character "Kuno the Robber" he often steals the plate.
Here the agents come to satisfy their tiredness. At the saloon the agents may play pool or sit down. To play pool they need one of the pool-cues that are "floating in the air". Pool-cue should be returned after use but note that they are not always placed exactly at their previous locations. You may in fact see pool-cue dropped at a completely different location. This is because agents that steal the pool-cue will re-evaluate their possessions at every location. Thus when leaving the diner, the agent might realise that he has actually "forgotten" to return the pool-cue and then quickly drop it.
At the dancehall the agents may either dance or play music to satisfy their boredom. In future work the agents should have roles so that servant-agents would play the music and the guest-agents dance to it.
The agents visit the bathroom to satisfy their filthiness. The agents need to be undressed before they shower and so they need a locker to their cloth as long. There are only four lockers and only three showers, so you might see queues here. To help keep track of the agents they do not leave hats or equipment in the lockers.
If this was to be a computer game you should need some kind of interaction ability. One approach to this is to give the agents some special abilities that only you can activate. Every agent has a willpower value and that determines if and how massively these skills take effect. The willpower will rise again after sometime. In Figure 26, below, your see a screenshot of a characters data displayed. The height of the column shows how much willpower he has at the moment. Beneath him is a list of the current implemented special skills. Some skills will, when activated, affect only the character and others have a sphere of influence.

Figure 26 , parameters shown for an agent.
This is only meant as an example of how interactions could be made there are of course many other ways to handle this.
In the previous many candidates for future work has been mentioned. The agents should be better at handling objects, they should perceive in more detail, and interaction among agents should be developed further. These are all things that mostly rely on a lot of programming. In contrast to include different roles in the system would require a new module and further it brings about the question of how to tell a good story. This is a subject that I have paid very little attention to in this project.
In the field of multimedia constructing good stories in simulations is a very hot issue and the amount of literature is enormous. One approach, done by Klesen et al. [34], is to have helpers support the main characters. For instance, you have the villain and the hero but if the hero is captures the villagers will riot and supply opposition to the villain in this way. Likewise the monsters in the forest will awake when the villain is in trouble. This is a very nice and simple idea that seems well suited to my system.
I claimed that the agents I wanted to design should be autonomous and perhaps they have become too independent. At least I find it sometimes confusing what the agents are actually doing and why. Perhaps a norm module would help to better this as claimed by Flentge et al. [20]. Otherwise the agent model would do well with some clarifying and a better oscillation-avoidance system.
Lastly, it would be interesting to investigate how evolution could influence the agents. Then they should be allowed to have offspring and to mutate. With this in mind, in the model now, the agents' proportions of their limbs are actually determined by a set of genes. However this is not activated in the example on the CD-ROM, but in future work I would find this interesting.
|
