indeksu: 115780
Opracowanie artykułu z tłumaczeniem:
"Learning User Similarity and Rating Style for Collaborative Recommendation" - Kwok-WAI Cheung, Lily F. Tian
Streszczenie:
Information filtering staje się coraz ważniejszą dziedziną ponieważ informacji przybywa. Systemy umożliwiające personalizowaną rekomendację dla użytkownika są w świetle zainteresowań w ostatnich latach. Collaborative filtering jest jednym z zwykle używanych przybliżeń, które normalnie wymagają definicji miary podobieństwa dla użytkownika (similarity measure). W tym artykule oni proponują użyć technik nauki maszyny (machine learning techniques) w celu nauczenia się optymalnej miary podobieństw dla użytkownika (user similarity measure) tak dobrze jak stylu oceny użytkownika (user ratings styles) dla powiększenia dokładności rekomendacji. Oni szacowali swoje metody używając EachMovie dataset.
Wstęp:
Przykład wzrostu informacji:
Product bokering in e-commerce - istnieje mnóstwo sklepów sieciowych i w każdym sklepie można znaleźć mnóstwo produktów.
Gwałtowny rozwój różnych technologii personalizacji ma miejsce w ostatnich latach, a systemy rekomendacji są jedną z nich. Systemy te dążą do wyeliminowania (filter out) nieinteresujących danych (lub przewidzenia interesujących) automatycznie w imieniu użytkownika zgodnie z jego preferencjami. Opierając się na podstawowych technologiach systemy rekomendacji dzielimy na:
content-based
collaborative
Rekomendacje content-based:
Systemy te wydobywają (extract) właściwości (characteristics) elementów (items) i porównują je z profilem zainteresowań użytkownika w celu przewidzenia zdania użytkownika o elemencie. Najprostszą metodą jest tutaj dopasowywanie słów kluczowych (keyword matching) z profilu użytkownika. Bardziej wyszukane techniki włączają miary podobieństw opartych na ontologiach (ontology-based similarity measures) i systemy z regułami (rule-based systems). Uwaga: wydobywanie właściwości o obrazach będzie się różnić od wydobywania właściwości muzycznych.
Wybranie dobrej reprezentacji właściwości elementów pozwala rekomendować tylko podobne elementy (dla content-based recommender system). Np. gdy ktoś interesuje się książkami komputerowymi, to system rekomendujący będzie mu dostarczał tylko informacje o tej dziedzinie. Nazywa się to over-specialization problem. W celu zróżnicowania rekomendacji powołują się na Mougouie, który zaadoptował strukturę wnioskowania case-based, gdzie każdy element jest traktowany jako point case, a podobne elementy są grupowane jako generalized cases (produkty o tej samej marce).
Zwiększając urozmaicenie rekomendowanych elementów można złagodzić problem over-specialization.
Rekomendacje collaborative (współpraca):
Rekomendacje lub filtrowanie collaborative przewiduje preferencje dla elementów w sposób word-of-mouth (słowa - usta). Preferencje są przewidywane w efekcie rozważań na podstawie opinii innych like-minded użytkowników. Jako że oceny (ratings) preferencji są używane zamiast cech domain-specific stosowalność systemów collaborative recommender jest bardziej uniwersalna.
Jeżeli system dowie się, że lubisz książki komputerowe i istnieje grupa użytkowników lubiąca książki komputerowe i fantastykę, to system będzie rekomendował Ci także fantastykę.
Sukces tego systemu polega na dostępności dużej liczby użytkowników dostarczających odpowiednio duży zbiór ich preferencji.
W praktyce trudno jest wymagać by użytkownicy dostarczyli za dużo ocen preferencji przed użyciem systemu zwłaszcza gdy dopiero zarejestrowali się do systemu. Więc dostarczenie dokładnych rekomendacji przy krótkim czasie używania jest jednym z wyzwań stawianych przed twórcami tych systemów. Jednym z możliwych rozwiązań jest (użycie model-based methods) utworzenie pewnego zwartego abstrahującego od preferencji użytkownika wzoru dla interpolowania brakujących danych. Ogólnie przybliżenia content-based mogą dać lepsze wyniki przy braku dostatecznej liczby wskaźników preferencji od użytkownika.
Kolejnym problemem collaborative recommendation jest subiektywność ocen. Gdyż każdy może inaczej oceniać ten sam materiał.
Metody memory-based:
Obliczane są najpierw podobieństwa między użytkownikami przez porównanie bezpośrednie ich wskaźników preferencji. Preferencje użytkownika dla brakujących elementów (items) są obliczane jako suma udziałów innych użytkowników dla tego elementu i odpowiednio zważone opierając się na mierze podobieństwa użytkownika (user similarity measure). Ważne dla rekomendacji jest jak definiujemy tą miarę.
Metody te są podobne do przybliżeń k-nearest neighbor (kNN), które są często używane w społeczności rozpoznającej wzory (pattern recognition). kNN podejmuje decyzję przez rozważenie tylko wejść danych sąsiadów zdefiniowanych stosownie do metrycznej odległości w przestrzeni właściwości (feature space). Używane są przy tym metryki: na odległość Euklidesową, na odległość Mahalanobis.
Łatwo zrozumieć, że użytkownicy podświadomie stosują swe własne skłonności (biases) dostarczając oceny preferencji. Dwa identyczne wskaźniki od dwóch różnych użytkowników mogą oznaczać zupełnie coś innego, bo jeden mógł być krytyczny w ocenie, a drugi wyrozumiały. Jednak średnio powinno wyjść dobrze, albo można też badając zachowania użytkowników wnioskować, że np. jeden daje zawsze niskie oceny, a inny zawsze trochę wyższe.
Bliskie prace przy nauce profilu użytkownika:
Literatura information retrieval podaje wiele różnych opisów badań nauki profilu i większość z nich używa przybliżeń content-based, gdzie profil jest reprezentowany jako zbiór mierzonych preferencji. Np. może to być rozkład prawdopodobieństwa na zbiorze słów kluczowych obliczonych używając naiwnej klasyfikacji Bayesa.
Dla collaborative recommendation częściej używa się technik uczenia maszyny. Przykłady: sieci Bayesa, ukryte modele klas (latent class models), neuronowe klasyfikatory sieci (neural network classifiers)
Memory-based collaboraive recommendation:
a - indeks aktywnego użytkownika
pa,j - przewidziana wartość oceny preferencji aktywnego użytkownika a dla elementu j
Zwykle przyjmuje się następujący wzór:
(1) 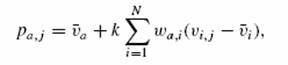
gdzie N - całkowita liczba użytkowników, ![]() jest
średnią oceną dla użytkownika i vi,j
jest oceną użytkownika i dla elementu j,
jest
średnią oceną dla użytkownika i vi,j
jest oceną użytkownika i dla elementu j, ![]() oznacza
wagę obliczoną jako podobieństwo pomiędzy
użytkownikami a i i, k jest czynnikiem normalizującym obliczonym jako:
oznacza
wagę obliczoną jako podobieństwo pomiędzy
użytkownikami a i i, k jest czynnikiem normalizującym obliczonym jako: ![]() .
Przyjęte jest ignorowanie iteracji sumy jeżeli jakiś
użytkownik nie ma określonego współczynnika preferencji dla
rozpatrywanego elementu (oczywiście można używać
jakichś domyślnych wartości - oni używali średnie
wartości). Piszą, że zamiast sumy można brać maksimum,
lecz oni tego nie używają.
.
Przyjęte jest ignorowanie iteracji sumy jeżeli jakiś
użytkownik nie ma określonego współczynnika preferencji dla
rozpatrywanego elementu (oczywiście można używać
jakichś domyślnych wartości - oni używali średnie
wartości). Piszą, że zamiast sumy można brać maksimum,
lecz oni tego nie używają.
Dalej podają, że Pearson correlation coefficient (współczynnik korelacji Pearson'a) jest najpopularniejszą miarą używaną jako funkcja podobieństwa (similarity function) i dany jest następująco:
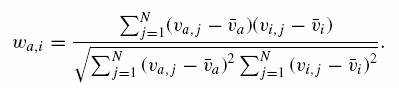
Ten wzór zakłada, że każdy użytkownik ma skłonności do oceniania równe średnim wskaźnikom preferencji.
Zamiast Pearson correlation coefficient może być używany wektor podobieństw (vector similarity) i właściwości oparte na wagach (feature weighting based).
Nauka funkcji podobieństw użytkownika:
Zamiast podawania funkcji, która
poprawiałaby się w czasie oni proponują nauczyć się
"optimum" z raz danego zbioru testowych danych. Chcą więc
uzyskać optymalną wartość ![]() taką, że całkowity
błąd przewidywania jest zminimalizowany. Definiując optymalną
funkcję kryterium tak by otrzymać korzyści paradygmatu
kolaboracji oni podzielili zbiór treningowych danych dla każdego
użytkownika na dwie części. Np. dla użytkownika i podzielili dane na zbiór treningowy Ti oraz zbiór walidacji Vi. Zbiór treningowy jest głównie
używany do obliczania wartości ocen preferencji, natomiast zbiór
walidacji służy do definiowania przewidywanych błędów do
zminimalizowania. Tak więc funkcja kryterium dla mierzenia
całkowitego przewidywania błędów dana jako funkcja
podobieństw użytkownika w:= staje się
taką, że całkowity
błąd przewidywania jest zminimalizowany. Definiując optymalną
funkcję kryterium tak by otrzymać korzyści paradygmatu
kolaboracji oni podzielili zbiór treningowych danych dla każdego
użytkownika na dwie części. Np. dla użytkownika i podzielili dane na zbiór treningowy Ti oraz zbiór walidacji Vi. Zbiór treningowy jest głównie
używany do obliczania wartości ocen preferencji, natomiast zbiór
walidacji służy do definiowania przewidywanych błędów do
zminimalizowania. Tak więc funkcja kryterium dla mierzenia
całkowitego przewidywania błędów dana jako funkcja
podobieństw użytkownika w:= staje się
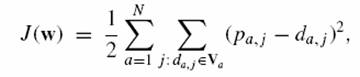
gdzie
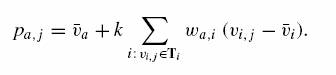
Przykład zbioru treningowego:

gdzie podkreślone elementy (losowo wybrane) są traktowane jako zbiór walidacji Va. Znaki zapytania oznaczają brakujące wskaźniki. Pozostałe elementy są używane jako Ti dla obliczeń przewidywanych wskaźników pa,j
Optymalna funkcja podobieństwa
może być stąd obliczona jako ![]() .
Prosta metoda opuszczania gradientu (gradient descend mathod) jest
używana tutaj do otrzymania w* i reguła aktualizowania wag może
być obliczona następująco:
.
Prosta metoda opuszczania gradientu (gradient descend mathod) jest
używana tutaj do otrzymania w* i reguła aktualizowania wag może
być obliczona następująco:
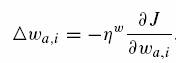
gdzie ![]() oznacza
współczynnik uczenia się dla wa,i, kontrolujący rozmiar kroku dla
szukania w*. Jest możliwe, że inne metody minimalizacji dają
lepsze wyniki, jednak oni chcą zbadać wykonalność
obliczeń funkcji podobieństw używając machine learning
approach w celu poprawienia wykonania przewidywań.
oznacza
współczynnik uczenia się dla wa,i, kontrolujący rozmiar kroku dla
szukania w*. Jest możliwe, że inne metody minimalizacji dają
lepsze wyniki, jednak oni chcą zbadać wykonalność
obliczeń funkcji podobieństw używając machine learning
approach w celu poprawienia wykonania przewidywań.
Inaczej niż dla funkcji podobieństw w, oni mogliby osłabić założenia brania średnich wskaźników oceny użytkownika skłonności i pozwolić systemowi na naukę tych skłonności. Wówczas zachodziłby następujący wzór na ocenę preferencji użytkownika:
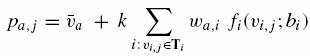
gdzie ![]() oznacza funkcję wskaźnika
transformacji dla i-tego użytkownika i bi oznacza skłonności
oceniania przez użytkownika i
oznacza funkcję wskaźnika
transformacji dla i-tego użytkownika i bi oznacza skłonności
oceniania przez użytkownika i
Liniowe transformacje oceny:
Przy założeniu liniowości reguła aktualizacji może mieć postać:
LM1-W (8)
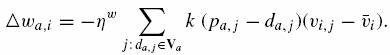
Na podstawie tej reguły podobieństwo pomiędzy aktywnym użytkownikiem, a użytkownikiem i musi być zmniejszona (zwiększona) gdy dla większości użytkowników j, przewidywana wartość oceny preferencji pa,j jest za duża (mała) gdy porównujemy z pożądaną wartością da,j (pierwszy czynnik) i ocena preferencji powoduje za duże (małe) oczekiwane wartości (drugi czynnik). Intuicyjnie oznacza to, że podobieństwa pomiędzy dwoma użytkownikami powinny być tłumione (wzmacniane) jeżeli opinie i-tego użytkownika często są złe (dobre) w stosunku do opinii aktywnego użytkownika. Po aktualizacji w wartość k także ulegnie aktualizacji względem swojej definicji. Proces aktualizacji iteruje aż do zbieżności.
Skłonności użytkowników do oceniania albo łagodniej albo krytyczniej powodują, że ocena preferencji użytkownika może nie być optymalnie oszacowana. Można więc osłabić wcześniejszą formułę otrzymując:
(9)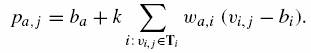
Używając gradient descent method reguła aktualizacji wa,i i bi są następujące:
LM2-W
(10)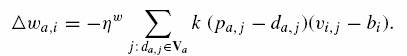
LM2-B:
(11)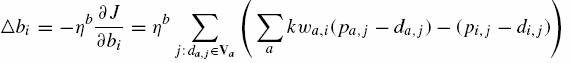
Względem powyższego wzoru bi maleje (rośnie) gdy większość elementów ma większą (mniejszą) przewidywaną ocenę niż pożądany wynik (drugi element). Intuicyjnie można rozumieć to tak że skłonności optymisty będą tłumione.
Nieliniowe transformacje oceny:
Linearność daje subiektywne
wrażenie. Trudno jest też uwierzyć, że zmiana oceny z 0.3
na 0.4 jest taka sama jak z 0.8 na 0.9 (skala 0 -1). Ogólnie zakładamy,
że użytkownicy są racjonalistami i dają wyższą
ocenę tylko gdy coś jest lepsze od innych rzeczy. Liniową
transformację możemy zamienić przez monotonicznie
rosnącą nieliniową. Oni proponują użycie funkcji sigmoid
jako nieliniowego kandydata na ![]() :
:
(12)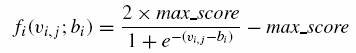
gdzie max_score odnosi się do najwyższej możliwej oceny.
Używanie gradient descent method bez modelowania skłonności użytkowników do reguły aktualizacji funkcji podobieństwa jest dane jako:
NLM1-W:
(13)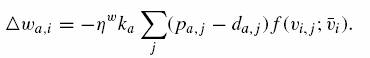
Dodając skłonności użytkownika, reguła aktualizacji przyjmuje postać:
NLM2-W:
(14)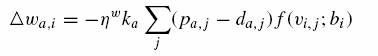
NLM2-B:
(15)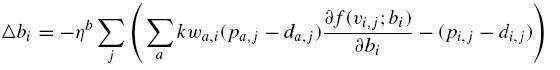
gdzie częściowa pochodna może być obliczona jako:
(16)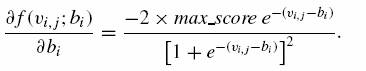
Struktura eksperymentu:
dataset: Do oszacowania i porównania przewidywanego wykonania proponowanego systemu rekomendacji z różnymi funkcjami podobieństw i funkcjami transformacji ocen wykonali różne eksperymenty oparte na EachMovie dataset. Zbiór ten był zbierany od 1995 do 1997 i zawiera oceny 72916 użytkowników na temat 1628 filmów. Wybrali 500 użytkowników mających po więcej jak 10 ocen filmów każdy. Podzielili te 500 osób na 2 grupy: treningowych użytkowników i testowych użytkowników. Oceny preferencji treningowych użytkowników były używane do treningów, gdy Ci z testowych użytkowników zostali podzieleni na treningowy zbiór, zbiór walidujący i testowy zbiór jak opisane było wcześniej.
Ocena preferencji użytkownika była określa przez atrybuty: liczba punktów i waga. Waga oznaczała czy użytkownik oceniał numerycznie film (1 - ok., <1 - "sounds awful"). Ponieważ film oceniany na zero lub "sounds awful" było oznaczone przez zero punktów oni rozróżniali dwa przypadki odwzorowując drugie określenie na -2. Dla wagi =1 przyjęli odwzorowanie punktów 1 - 6. Więc ogólnie ich zakres punktów był [-2, 6]
protocols: Zaadoptowali powszechnie używane protokoły zwane AllBut1 i GivenN. AllBut1 zakłada, że jedna ocena jest ukryta dla każdego testowego użytkownika i zadanie polega na wyznaczeniu tej wartości na podstawie pozostałych ocen preferencji. GivenN losowo wybiera N ocen preferencji dla każdego testowego użytkownika jako dane oceny dla wyznaczenia pozostałych. Wynik działania tego protokołu określa działanie systemu na początku, gdy liczba ocen jest ograniczona (oni używali jako N: 5 i 10). Oni zmieniali także proporcje pomiędzy zbiorami: testowym, walidacyjnym i treningowym co widać na rysunku:
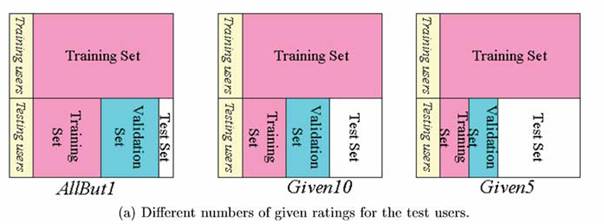


evaluation criterion (kryteria oceny)
Użyli Mean Absolute Error (MAE) do oceny dokładności przewidywań. MAE to średnia z absolutnej różnicy pomiędzy aktualną i przewidywaną oceną. Ta miara jest szeroko używana w literaturze systemów rekomendacji.
Wyniki eksperymentów i dyskusja:
Opierając się na powyższych protokołach porównali 6 algorytmów. Cztery z nich są różnymi wariacjami proponowanej machine learning approach oznaczanej jako LM1, LM2, NLM1, NLM2. Początkowe wartości funkcji podobieństwa wa,i dla nauki tych 4 systemów rekomendacji są losowe wartości z pomiędzy -1.0 do 1.0 i jako skłonności użytkowników przyjęto średnie wartości ocen poszczególnych użytkowników.
Pozostałe 2 algorytmy zwane BP i PC.
BP wspiera Baseline Performance, gdzie użyli średnich ocen dla testowych użytkowników jako przewidywane oceny dla wszystkich filmów.
PC odnosi się do konwencjonalnego użycie Pearson-correlation Coefficient (2) opisany wcześniej.
Tabele 1 - 3 pokazują wyniki testów. Najlepszy wynik jest pogrubiony. Zwiększanie liczby użytkowników treningowych zmniejszało błędy przewidywań (co jest intuicyjnie oczywiste).
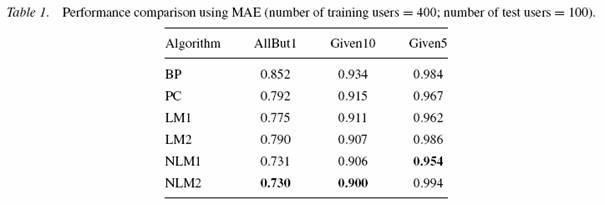
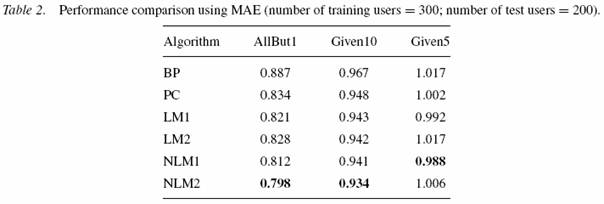
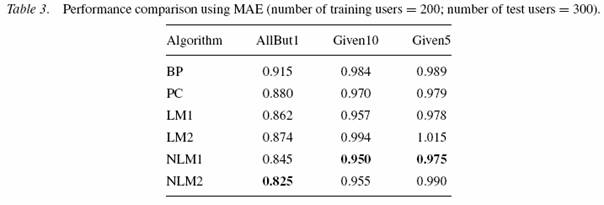
Porównanie BP i PC dało prawie dla wszystkich machine learning-based methods lepsze wyniki dla wszystkich protokołów (wyjątek LM2).
Liniowa i nieliniowa transformacja oceny wskazuje, że nieliniowa wersja osiągnęła bardziej znaczące wyniki od liniowej.
Wykres funkcji sigmoid:
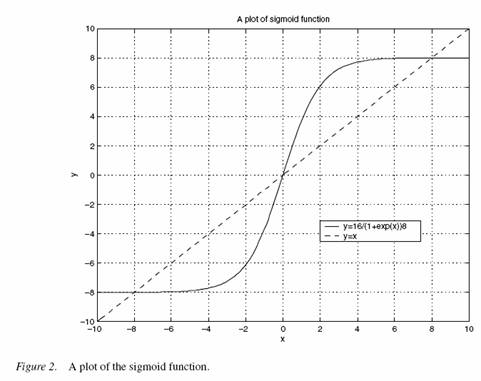
Dla eksperymentów AllBut1 i Given10 NLM2 daje najlepsze wyniki (patrz tabela 1 i 2). Jednak dla Given5 NLM1 okazuje się lepszy od bardziej skomplikowanego NLM2.
Także szacowali proponowane algorytmy w różnych proporcjach treningowych i walidacyjnych zbiorów dla testowych użytkowników. W szczególności wyniki dla NLM2 są podane w tabeli 4.
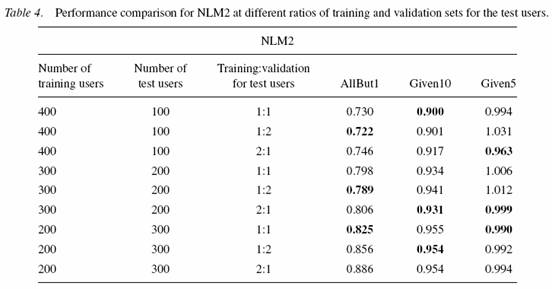
Patrząc na porozrzucane najlepsze wyniki widać, że żadna kombinacja proporcji treningowych i walidacyjnych nie jest uniwersalnie dobra.
Ogólnie zaobserwowali, że większy zbiór walidacyjny był bardziej korzystny gdy był większy zbiór treningowy użytkowników (np. przypadki dla 400 treningowych użytkowników) lub więcej danych dostępnych od testowych użytkowników dla treningu (np. AllBut1 przypadki). Mniej korzystna była sytuacja gdy liczba treningowych użytkowników malała (przypadki z 200 treningowymi użytkownikami) lub mniej danych od testowych użytkowników (przypadki Given5).
Wnioski i przyszłe badania:
Oni zaproponowali machine learning approach w celu uzyskania optymalnej funkcji podobieństwa dla użytkownika i stylów ocen użytkownika dla memory-based collaborative recommender systems. Ekperymentowali z kilkoma liniowymi i nieliniowymi funkcjami oceny transformacji (ratings transformation functions) i otrzymali lepsze wyniki niż porównane z standardowym correlation-based algorytmem.
W przyszłości chcieliby zobaczyć jak idea oceny transformacji może być włączona także do metod model-based do wykonania wzmocnienia.
Także chcieliby jakoś podzielić użytkowników na grupy na podstawie stylu oceniania. Wspominają też o zidentyfikowaniu użytkowników, którzy są poważni i krytyczni gdy ich bi jest stosunkowo niskie. Chcą też identyfikować użytkowników o najwyższym wpływie.
|
