O posibila clasificare a sistemelor de calcul se poate face dupa modul în care se face prelucrarea informatiei. Dupa acest criteriu putem avea:
a. sisteme cu un singur procesor atunci când se foloseste o singura unitate centrala de prelucrare (se foloseste prescurtarea CPU - Central Processing Unit).
b. sisteme multiprocesor atunci când în scopul cresterii vitezei de prelucrare se adauga înca un procesor, de exemplu coprocesorul matematic sau se cupleaza mai multe procesoare identice care pe lânga cresterea vitezei maresc fiabilitatea sistemului, sarcinile unui procesor defectat fiind automat preluate de un alt procesor.
c. retele de calculatoare care formeaza sisteme informationale distribuite pe distan 151b15b te mari si au un caracter aparte din punctul de vedere a proiectarii si functionarii.
Un model de arhitectura pentru un sistem de calcul care este folosita în analiza si proiectarea sistemelor de calcul a fost introdusa de savantul american John von Neumann ca rezultat al participarii sale la constructia în anii 1944 - 1945 a calculatorului ENIAC în S.U.A. Aceasta este cunoscuta în literatura de specialitate ca arhitectura von Neumann.
1.1. Arhitectura generalizata von Neumann
Dupa cum se observa în figura 1.1., un sistem de calcul este format din 3 unitati de prelucrare care sunt conectate între ele prin 3 cai (numite bus-uri) separate de transfer a informatiei.Vom analiza pe scurt scopul acestor elemente.
A. Unitatea centrala de prelucrare (CPU - Central Processing Unit) are rolul de a extrage instructiunile (care sunt de fapt comenzile programului ca aduna, scade, verifica semnul rezultatului, etc.) memorate într-un dispozitiv de stocare numit memorie, de a decodifica aceste instructiuni si apoi de a prelucra datele care sunt cerute de instructiuni. Rezultatele acestor prelucrari pot fi depozitate într-un registru intern al C.P. U., sa fie depus într-o locatie de memorie sau trimis la un dispozitiv de intrare / iesire (I/O - input/output).
Se observa ca executia unei instructiuni presupune executia urmatoarei secvente de actiuni:
a. Depunerea pe busul de adresa a unei informatii care localizeaza adresa de memorie ce contine câmpul de cod al instructiunii (secventa de ADRESARE).
b. Citirea codului instructiunii si depunerea acestuia într-un registru intern al decodificatorului de instructiuni. Aceasta informatie este vehiculata pe busul de date (secventa de LECTURĂ).
Deobicei aceste doua secvente sunt reunite in una singura numita secventa de FETCH.
c. Decodificarea codului instructiunii în urma careia CPU va cunoaste ce instructiune are de executat si ca urmare pregateste modulele ce vor participa la instructiunea respectiva (secventa DECODIFICARE)
d. Executia efectiva a operatiei specificate de de instructiune (adunare, scadere, salt, etc.) - secventa de EXECUŢIE.
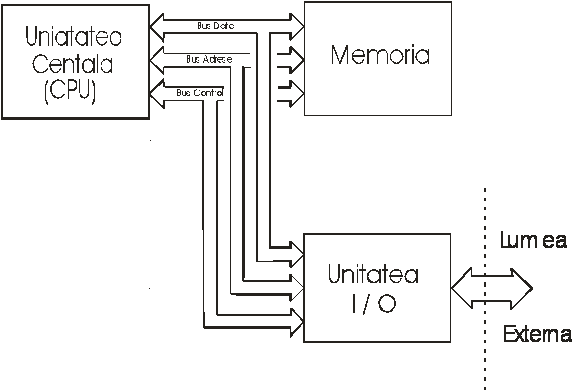
fig 1.1
Deobicei aceste doua secvente sunt reunite in una singura numita secventa de FETCH.
e. Decodificarea codului instructiunii în urma careia CPU va cunoaste ce instructiune are de executat si ca urmare pregateste modulele ce vor participa la instructiunea respectiva (secventa DECODIFICARE)
f. Executia efectiva a operatiei specificate de de instructiune (adunare, scadere, salt, etc.) - secventa de EXECUŢIE.
Se continua cu extragerea instructiunii urmatoare si trecerea ei prin secventele amintite s.a.m.d.
Sincronizarea operatiilor amintite se realizeaza prin generarea unui set de informatii pe magistrala de comenzi.
B. Unitatea de memorie în cadrul arhitecturii von Neumann are rolul de a stoca instructiunile pentru CPU, precum si datele asupra carora vor opera instructiunile (operanzii ). Aceste instructiuni trebuie sa fie memorate anterior începerii desfasurarii programului de prelucrare. Deasemeni unele date se vor memora anterior pornirii prelucrarii iar rezultatele prelucrarii se memoreaza în timpul executiei programului. Aceasta memorie, realizata în diverse tehnologii de-a lungul evolutiei calculatoarelor constituie suportul fizic necesar desfasurarii operatiilor executate de CPU.
Informatia în memorie este stocata la asa-numitele adrese. Pentru accesarea unei informatii din memorie se furnizeaza acesteia adresa acelei informatii iar circuitele de control al memoriei vor furniza continutul adresei care reprezinta informatia ceruta.
Similar si la scrierea în memorie.
Tehnologic, dispozitivele de memorie pot retine informatia
numai când sunt alimentate electric si avem de-a face cu asa-zisa memorie volatila
atunci când nu sunt alimentate electric formând memoria nevolatila si care este folosita în mod special la stocarea programelor pentru initializarea calculatorului si stocarii sistemului de operare.
C. Dispozitivele de intrare - iesire I/O (input/output) permit transferul informatiei între CPU, memorie si lumea externa.
Functional, aceste dispozitive de I/O pot fi adresate (apelate) de catre CPU similar ca si memoria ele dispunând de asemeni de câte un set de adrese. În mod clasic, schimbul de informatii cu exteriorul se face sub controlul CPU dar exista tehnici care vor fi amintite mai târziu atunci când accesul la memorie se poate face si fara interventia CPU (asa-numitele transferuri DMA - Direct Memory Access).
D. Busul de date este acea cale care leaga cele 3 blocuri functionale (o parte a sa poate sa iasa si în exteriorul sistemului) si pe care se vehiculeaza datele propriu-zise (numere sau caractere) sau instructiunile programului.
E. Busul de adrese este calea pe care sunt transmise de CPU adresele catre memorie când se face o operatie de citire sau scriere cu memoria sau se vehiculeaza adresele dispozitivului de I/O în cazul unui transfer cu un periferic.
F. Busul de comenzi vehiculeaza semnalele de comanda si control catre toate aceste blocuri si care permit o sincronizare armonioasa a functionarii sistemului de calcul.
Arhitectura de tipul von Neumann a fost o inovatie în logica masinilor de calcul care s-au construit pâna atunci prin faptul ca sistemul trebuia sa aiba o cantitate de memorie, similar cu creierul uman, în care sa fie stocate atât datele cât si instructiunile de prelucrare (programul). Acest principiu al memoriei a reprezentat unul din fundamentele arhitecturale ale calculatoarelor. Era vorba chiar de pogramele stocate în memorie si nu numai a datelor.
Nota: A început sa apara din ce în ce mai clar care este aplicabilitatea memoriei. Datele numerice puteau fi tratate ca si valori atribuite unor locatii specifice ale memoriei. Aceste locatii erau asemanate cu niste cutii postale care aveau aplicate etichete numerotate de exemplu 1. O astfel d locatie putea contine o variabila sau o instructiune. A devenit posibil ca datele stocate la o anumita adresa sa se schimbe în decursul calculului ca urmare a pasilor anteriori. În acest mod numerele stocate în meorie au devenit simboluri ale cantitatilor si nu neaparat valori numerice, în acelasi fel cum algebra permite manipularea simbolurilor x si y fara a le specifica valorile !
Calculatoarele ulterioare si mai târziu microprocesoarele au implementat aceasta arhitectura care a devenit un standard.
1.2. Evolutia si tendintele în domeniul arhitecturii interne
Aceasta arhitectura interna a fost dezvoltata în mai multe directii rezultând sisteme de calcul cu posibilitati noi si adaptate noilor cerinte cerute de societate. Pentru a vedea aceste noi directii ne vom folosi de o clasificare a sistemelor dupa arhitectura interna propusa de Flynn:
SISD (Single Instruction Single Data - o instructiune o data) sunt sistemele uzuale cu un singur microprocesor. Aici se încadreaza microprocesoarele clasice cu arhitectura von Neumann pe 8, 16, 32, 64 biti cu functionare ciclica - preluare instructiune, executie instructiune (rezulta prelucrarea datelor) s.a.m.d.
Tot în aceasta categorie trebuie introdusa si asa-numitele procesoare de semnal DSP (Digital Signal Processors) folosite actual de exemplu în placile de sunet, telefonie mobila, etc.
SIMD (Single Instruction Multiple Data - o instructiune cu mai multe date) sunt sistemele cu microprocesoare matriceale, la care operatiile aritmetice se executa în paralel pentru fiecare element al matricei, operatia necesitând o singura instructiune (se mai numesc si sisteme de procesare vectoriala). În principiu SIMD arata ca în figura 1.2.
Eficienta SIMD-urilor se dovedeste a fi ridicata în cazul unor programe cu paralelisme de date masive puse în evidenta de exemplu de anumite bucle de programe.
Exemplu: arhitectura de tablou sistolic construita în 1984 de General Electric, un tablou elemente rezultând 1 bilion de operatii pe secunda.
.
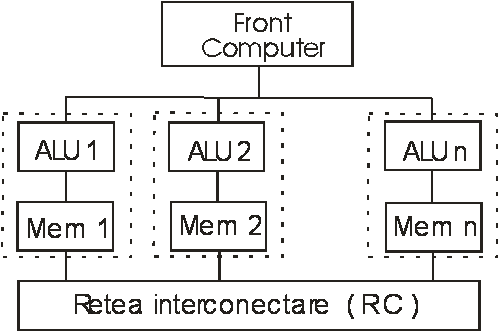
Fig. 1.2.
MISD (Multiple Instruction Single Data - mai multe instructiuni cu o data) .
Pentru a creste performantele sistemelor de calcul având frecventa ceasului data o solutie este executia în paralel a mai multe instructiuni.Extragerea instructiunilor din memorie este un punct critic în viteza de executie a acestora. Pentru a rezolva aceasta problema înca din perioada calculatoarelor mari ( mainframe ) instructiunile aveau posibilitatea sa fie extrase în avans si sa fie disponibile atunci cînd erau cerute de program. Pentru aceasta exista un set de registre numit tamponul pentru extragere în avans (prefetch buffer ). De fapt extragerea în avans împarte executia instructiunii în doua parti: extragerea si executia propriu-zisa .La sistemele de tip MISD aceasta strategie este extinsa si acest concept este cunoscut sub numele benzii de asamblare ( pipeline -conducta ).
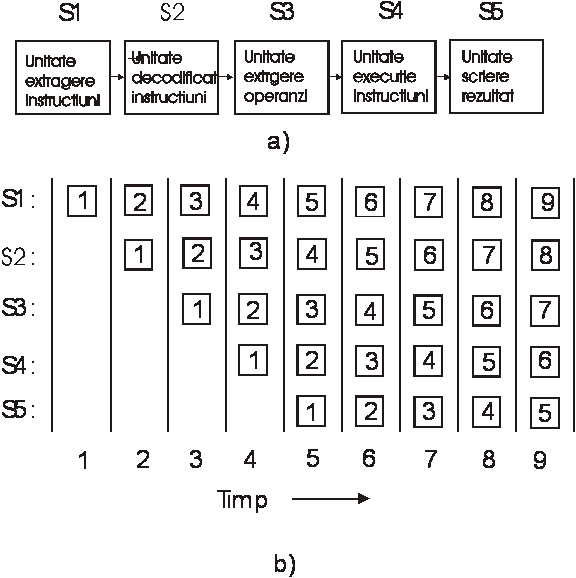
Fig. 1.3
În loc sa se împarta instructiunea în doua parti aceasta este impartita în mai multe parti, de fiecare parte ocupîndu-se o componenta hardware dedicata acesteia, toate partile hardware lucrînd in paralel.
. Figura 1.3 a ilustreaza o banda de asamblare cu 5 unitati , denumite si segmente ( stages ). Segmentul 1 extrage instructiunea din memorie si o plaseaza într-un registru tampon unde instructiunea îsi va astepta rindul. Segmentul 2 decodifica instructiunea determinîndu-i tipul si operanzii necesari. Segmentul 3 localizeaza si extrage operanzii din registrii sau memorie. Segmentul 4 executa proprizis instructiunea . În final segmentul 5 scrie rezultatul în registrul corespunzator.
În fig 1.3b se observa cum opereaza în timp banda de asamblare. Pe perioada ciclului 1 de ceas , segmentul S1 lucreaza cu instructiunea 1, extragînd-o din memorie. Pe perioada ciclului 2 , segmentul S2 decodifica instructiunea 1 în timp ce segmentul S1 extrage instructiunea 2. Pe perioada ciclului de ceas 3 , segmentul S3 extrage operanzii pentru instructiunea 1 , segmentul S2 decodifica instructiunea 2 iar segmentul S1 extrage a treia instructiune. La fel se petrec lucrurile si ptr. urmatoarele cicluri de ceas dupa cum se poate urmari pe figura, în final rezultind instructiuni executate la fiecare perioada de ceas. Daca am presupune ca ciclul masina este de 2 ns atunci pentru ca o instructiune sa treaca prin toate cele 5 segmente ale benziide asamblare vor fi necesare 10 ns. Datorita însa existentei benzii de asamblare la fiecare ciclu de ceas de 2 ns este terminata o instructiune! Astfel viteza creste de 5 ori !
Arhitecturi superscalare
Daca o banda de asamblare este buna atunci doua benzi vor fi si mai bune! În fig 1.4 am prezentat o varianta posibila a unui UCP cu doua benzi de asamblare.
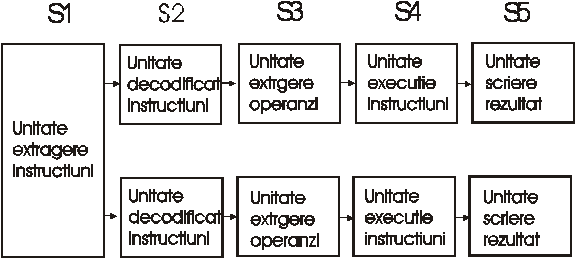
Fig. 1.4
Exista o singura unitate de extragere a instructiunilor care extrage perechi de instructiuni care sunt plasate pe cele doua benzi de asamblare. Trebuie îndeplinite unele conditii pentru ca acest asamblu sa functioneze corect ( cele doua benzi sa nu-si dispute resursele-registrii de exemplu- sau sa nu depinda de rezultatele celeilalte ,etc) conditii care trebuie garantate fie de compilator care analizeaza instructiunile , fie este implementat un hardware suplimentar care asigura o executie corecta.
Începînd cu procesorul I486 Intel a introdus benzi de asamblare în arhitectura procesoarelor sale. Astfel un I486 are o singura bada de asamblare pe cînd un procesor Pentium are implementate 2 benzi de asamblare . Acestea sunt notate cu U si V. Banda de asamblare U ( U pipeline ) poate executa orice tip de instructiune Pentium. Banda de asamblare V (V pipeline ) poate executa numai instructiuni simple pentru întregi.
Am putea proiecta procesoare cu patru benzi de asamblare dar acest lucru presupune o duplicare excesiva a structurii hardware. În locul acestei posibilitati s-a preferat o implementare putin diferita. Exista o singura banda de asamblare dar mai multe unitati functionale ca in fig 1.5.
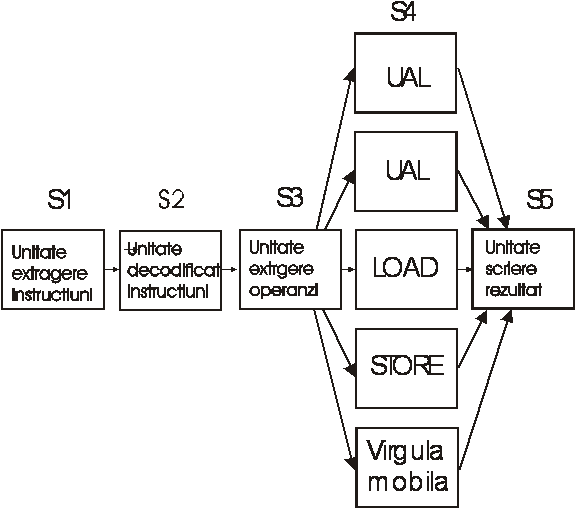
Fig. 1.5
Procesorul Pentium II are o structura similara. Pentru aceasta s-a introdus termenul de arhitectura superscalara (superscalar architecture). Ideea unui procesor superscalar implica ca segmentul S3 sa poata lansa instructiuni mult mai rapid decît poate executa segmentul S4 pe acestea! În realitate majoritatea unitatilor functionale din S4 au nevoie de mai mult de un ciclu de ceas pentru a termina treaba..Astfel S4 poate contine mai multe unitatti aritmetico-logice (UAL) sau de alt tip.
Amintim tot aici si asa - numita arhitectura Harward în care zonele de memorie pentru instructiuni au cai de adrese si date distincte fata de zonele de memorie destinate datelor rezultând astfel o crestere a vitezei. La tipurile noi de microcontrolere folosite în industrie sau în bunurile de larg consum se gasesc implementate aceste concepte de arhitectura facîndu-le foarte performante iar pretul de fabricatie este de ordinul dolarilor!
Celebrele supercomputere Cray a anilor 1970 foloseau de asemenea o arhitectura de tip MISD avînd si alte noutati în privinta arhitecturii interne pentru acea data.
MIMD (Multiple Instruction Multiple Data - mai multe instructiuni, mai multe date) sunt acele sisteme în care se încadreaza atât supercalculatoarele cu procesoare dedicate cât si sistemele multiprocesoare (vezi fig. 1.6). Putem sa consideram ca ultimele procesoare pentru PC-uri de la Intel din categoria dual core sau viitoarele cu mai multe nuclee se pot situa in aceasta categorie de arhitectura acestea inlocuind sistemele PC multiprocesor .
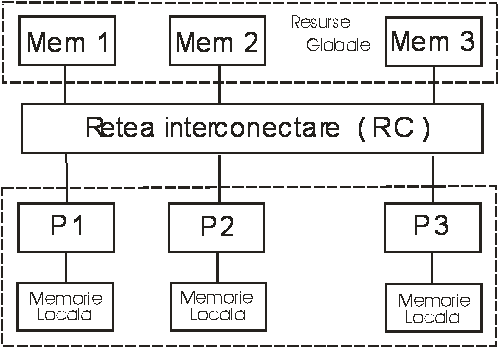
Fig. 1.3
Sa mai subliniem faptul ca aceste retele de interconectare (RC) pot implementa de la simpla arhitectura de sistem multiprocesor (SM) pe BUS COMUN (uniBUS - când numai un procesor are acces la BUS celelalte asteptând eliberarea busului) pâna la arhitecturi complexe de tip CROSSBAR care permite accesul simultan al tuturor microprocesoarelor la modulele de memorie globala cu conditia sa nu existe doua microprocesoare care sa acceseze simultan acelasi modul de memorie globala.
Exemplu: - firma DEC a produs un sistem având 16 procesoare PDP11/40 interconectate crossbar.
Pentru astfel de arhitecturi paralele cum se numesc acestea (MIMD) exista si sisteme de operare care asigura rularea în paralel a diferitelor procese. Astfel avem sisteme de operare (SO)
a) master - slave la care functiile SO sunt atasate unui microprocesor distinct - master - iar restul microprocesoarelor - numite slave - acceseaza aceste functii indirect prin intermediul unui microprocesor master.
b) divizat - nu exista un microprocesor evidentiat, fiecare microprocesor având functiile de sistem separat plasate în memorie.
c) flotant - când functiile SO sunt plasate în memoria comuna putând fi accesate de oricare microprocesor al sistemului, astfel ele "plutesc" de la un microprocesor la altul.
Tot în cadrul acestei ultime categorii trebuie amintite asa - numitele TRANSPUTERE care sunt de fapt microcalculatoare integrate într-un singur circuit, cu proprie memorie si retea de conectare punct cu punct cu alte transputere din aceeasi categorie. Cu acestea se pot construi masini SIMD sau MIMD folosindu-se limbaje de programare specifice proceselor paralele (ex. ORCAM), precum si algoritmi paraleli.
Întrebari la cap. 1
1. Care sunt unitatile de prelucrare într-o arhitectura de tip von Neumann ?
2. Care sunt busurile(magistralele) specifice unei arhitecturi de tipvon Neumann ?
3. Care sunt secventele de executie ale unei instructini tn CPU din cadrul unei arhitecturi tip von Neumann ?
4. Cum este accesata informatia din memorie la o arhitectura de calcul von Neumann ?
5. Cum sunt accesate dispozivele de intrare/iesire la o arhitectura de calcul von Neumann?
6. Ce informatie este stocata în memoria sistemelor cu arhitectura tip von Neumann
7.Cum se clasifica sistemele de calcul în functie de arhitectura interna dupa recomandarile cercetatorului Flynn ?
8. La ce sisteme de calcul se refera arhitectura de tip SISD ?
9. La ce sisteme de calcul se refera arhitectura de tip SIMD ?
10. Unde este aplicata tipul de arhitectura SIMD la procesoarele de tip INTEL ?
11. Desenasi o schema bloc de arhitectura de tip SIMD .
12. Care este principiul dupa care functioneaza o arhitectura de tip MISD ?
13. Numiti care ar putea fi operatiile executate in fiecare segment pentru o arhitectura MISD cu 5 segmente?
14. La ce se refera termenul de arhitectura superscalara pentru sistemele MISD?
15. Unde gasim implementata arhitectura de tip MISD în procesoarele de tip INTEL ?
16. Care sisteme intra în arhitectura de tip MIMD ?
17. Desenati o schema bloc de arhitectura de tip MIMD .
18. Ce fel de sisteme de operare exista pentru sistemele de tip MIMD ?
|
