Deoarece este dificil de înteles si analizat arhitectura acestor sisteme complexe în întregime, o arhitectura poate fi împartita în mai multe niveluri de functionalitate abstracte care ascund detaliile de implementare de componente. Aceste detalii sunt dezvaluite numai nivelelor de mai jos si numai la o examinare atenta.
Într-o retea de calculatoare, putem distinge o arhitectura fizica si o arhitectura logica. Arhitectura fizica descrie structura, functionalitatea si relatiile intermediare dintre implementarile protocoalelor de nivel jos si mediu din modelul stratificat de interactiuni în retea. Potrivit modelului OSI descris mai sus, din arhitectura fizica fac parte protocoalele nivelurilor fizic, legatura de date (data-link), transport si sesiune. Arhitectura fizica depinde, deci, nu numai de structura, functia si inter-relatiile dintre dispozitivele de retea, dar si de implementarile software ale protocoalelor din aceste nivele medii sau joase.
Arhitectura logica a retelelor de calculatoare descrie structura si relatiile software-ului care implementeaza protocoalele de nivel înalt ale modelului standard stratificat, si anume protocoalele straturilor prezentare si aplicatie. Aceasta arhitectura reflecta tehnologia integrata si unificata a retelei de calculatoare si poate fi construita peste diferite niveluri abstracte ale arhitecturii fizice.
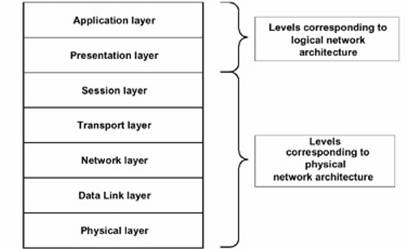
Figura : Legatura dintre arhitectura fizica si arhitectura 424b15e logica.
La ora actuala, urmatoarele tipuri de arhitectura logica de retea sunt cele mai utilizate:
arhitectura peer-to-peer;
arhitectura clasica client/server (cu variantele);
arhitectura client/server bazata pe web.
Aceste tipuri de modele de arhitecturi sunt în strânsa legatura cu diferite stagii de evolutie a sistemelor de calcul. Un model corect selectat pentru arhitectura logica a unei retele de calculatoare permite obtinerea productivitatii maxime, a eficientizarii protejarii resurselor de retea, flexibilitatea instalarii retelei si în acelasi timp reduce cheltuielile pentru construire si administrare.
Primul stagiu de evolutie a sistemelor de calcul a fost din 1940 pâna în 1970, mergând, de fapt, pâna la inventarea primului calculator (ENIAC, creat la scoala Moore, în iunie 1944).
De regula, fiecare calculator din vremea respectiva era bazat pe utilizarea partajata a unui calculator multi-utilizator, deoarece nu aparusera înca calculatoarele personale. Arhitectura acestor sisteme de calcul era centralizata, fiind utilizate terminale de tip caracter conectate la un calculator central.
În cazul în care calculatoarele erau conectate prin linii de comunicatii pentru a forma o retea, o asemenea retea avea o arhitectura peer-to-peer, în care nu existau calculatoare dedicate transmiterii resurselor pentru utilizare comuna de catre celelalte calculatoare din retea.
Deci, o arhitectura centralizata cade în categoria sistemelor de calcul autonome bazate pe utilizarea partajata a unui calculator multi-utilizator, în timp ce o arhitectura peer-to-peer cade în categoria retelelor de calculatoare care constau din calculatoare care sunt egale din punct de vedere al rangului, în care nu exista calculatoare dedicate utilizarii în comun de catre alte calculatoare.
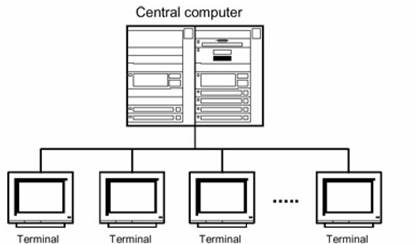
Figura : Arhitectura primelor sisteme de calcul.
În arhitectura centralizata, toate resursele de calcul, inclusiv informatia, erau concentrate pe un calculator central, cunoscut sub numele de mainframe. Terminalele de tip caracter care erau conectate la calculatorul central prin cabluri erau utilizate ca principal mijloc de acces la resursele informationale. Deoarece terminalul este un dispozitiv relativ putin sofisticat, acesta nu solicita nici o conditie sau operatie speciala pentru a fi pus în functiune. De asemenea, nu exista nici o configurare software care trebuia facuta de catre utilizatorul final, deoarece terminalul nu continea nici un software. Controlul terminalului era realizat centralizat de catre mainframe, iar toate terminalele erau de acelasi tip, garantându-se astfel ca un program arata la fel pe toate terminalele (executia se facea pe mainframe).
Din punct de vedere al stocarii si al securitatii datelor, marele avantaj al unei arhitecturi centralizate este simplicitatea relativa a construirii si administrarii sistemului de securitate al informatiei, aceasta fiind rezultatul centralizarii resurselor, deoarece este mult mai simplu de protejat mai multe obiecte daca acestea se gasesc într-o singura locatie.
În ciuda acestor avantaje, primele sisteme de calcul au avut numeroase dezavantaje, printre care lipsa de flexibilitate, dificultatea folosirii de catre utilizatorii finali si costuri ridicate.
Pe masura ce sistemele de calcul cu arhitectura centralizata au început sa intre în declin, retelele peer-to-peer au devenit din ce în ce mai populare, mai ales din cauza costului scazut, interconectând mai ales calculatoare personale si nu mainframe-uri. Acesta este si o proprietate majora a retelelor peer-to-peer, marcând absenta calculatoarelor centrale pe care sa existe toate resursele.
Printre dezavantajele semnificative ale retelelor peer-to-peer se numara atât nivelul scazut de siguranta, securitate si performanta, cât si complexitatea administrarii. În plus, aceste dezavantaje cresc din ce în ce mai mult, pe masura cresterii numarului de calculatoare din retele. Acest tip de arhitectura este, în concluzie, cel mai bine utilizata pentru interconectarea unui numar relativ mic de calculatoare, care au un nivel scazut de cerinte în ceea ce priveste securitatea si capacitatea de procesare a datelor.
Dezavantajele caracteristice ale sistemelor de calcul centralizate si, mai recent, ale retelelor de tip peer-to-peer au fost eliminate prin construirea de sisteme de calcul bazate pe arhitectura client/server. Aceasta arhitectura, aparuta dupa 1980, marcheaza cel de-al doilea stagiu de evolutie al tehnologiei calculatoarelor. Printre caracteristicile acestui stagiu putem enumara descentralizarea arhitecturii de calcul a sistemelor autonome si interconectarea acestora în retele globale de calculatoare.
Descentralizarea arhitecturii asociata cu primele sisteme de calcul a devenit posibila ca rezultat al aparitiei calculatoarelor personale, care, spre deosebire de terminale, pot îndeplini mai multe functii care erau îndeplinite de catre calculatoarele centrale. Ca rezultat al descentralizarii a devenit posibila crearea sistemelor de calcul distribuite locale si globale, care îsi puneau la dispozitie resursele pentru utilizarea lor în comun de catre alte calculatoare din retea. Calculatoarele care puneau la dispozitie resurse se numeau servere, iar calculatoarele care utilizau resursele se numeau clienti. Arhitectura unor astfel de sisteme de calcul distribuite a ajuns sa se fie cunoscuta sub numele de arhitectura client/server.
Un anumit server este caracterizat în primul rând de resursele pe care le mentine. De exemplu, daca resursa este o baza de date, serverul este cunoscut sub numele de server de baze de date, principalul scop al acestuia fiind interogarea datelor în folosul clientilor. În cazul în care resursa este un sistem de fisiere, serverul este un server de fisiere, iar scopul principal este de a transmite fisiere catre clienti. În general, serverele sunt capabile acum de a oferi o varietate de resurse pentru utilizare, prin utilizarea unui numar de programe server. Pe lânga toate acestea, serverele pot oferi acces la periferice (accesul la un server de imprimare sau print-server).
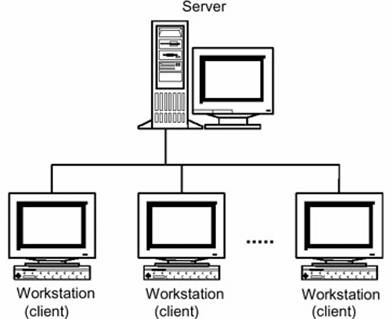
Figura : Arhitectura client/server clasica.
Putem distinge între câteva modele de arhitecturi client/server, fiecare dintre ele reflectând distribuirea componentelor arhitecturii software în calculatoarele din retea. Componentele software distribuite sunt mai apoi caracterizate în functie de capacitatile pe care le ofera.
Functiile oricarei aplicatii software pot fi divizate în trei grupuri:
functii legate de intrari si iesiri;
functii aplicate, specifice unui domeniu de aplicatiei;
functii legate de data mining si managementul datelor (baze de date, fisiere etc.).
Orice aplicatie software poate fi prezentata, în consecinta, ca o structura constând din trei componente:
componentele de prezentare, care implementeaza interfata cu utilizatorul;
componentele de aplicatie, care executa functiile aplicatiei;
componente care ofera acces la resurse informationale (manageri de resurse), acumuleaza informatii si gestioneaza date.
Ca rezultate, au aparut urmatoarele modele ale arhitecturii client/server, corespunzatoare metodelor de distribuire a celor trei componente software între statia de lucru si serverul din retea:
numai datele sunt stocate în server;
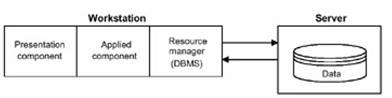
Figura : Numai datele sunt stocate pe server.
pe lânga date, gestionarul de resurse este localizat tot la nivel de server (un sistem de gestiune a bazelor de date, de exemplu);
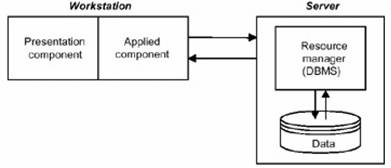
Figura : Gestionarul de resurse stocat la nivelul serverului,
datele, gestionarul de resurse si componentele aplicatiei sunt concentrate pe server;
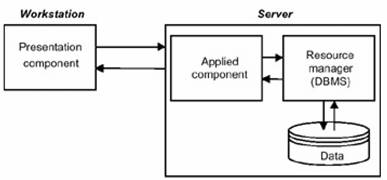
Figura : Gestionarul de resurse si aplicatiile sunt concentrate pe server.
componentele aplicatiei sunt localizate pe un server, în timp ce datele si gestionarul de resurse sunt localizate pe un alt server;
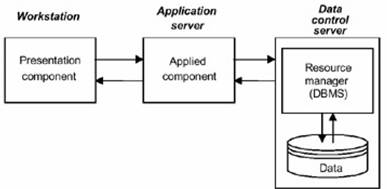
Figura : Componente distribuite.
Primul model al arhitecturii client/server, în care numai datele sunt localizate pe server, nu ofera o eficienta maxima, deoarece informatia este procesata pe statiile de lucru, iar fisierele continând aceste informatii trebuie transferate pentru procesare de la serverul din retea. Transferul unor mari volume de date prin retea are ca rezultat o rata mica a schimbului de informatii, conducând în schimb la supraîncarcarea retelei. Din aceste motive, acest model de acces la date aflate la distanta poate fi utilizat numai pentru retele relativ mici, în care se proceseaza un volum mic de date.
În cel de-al doilea model al arhitecturii client/server, pe server exista de asemenea un gestionar de resurse (SGBD, de exemplu). Acesta este modelul unui server cu control al datelor, în care componentele de prezentare si aplicatie sunt combinate si executate pe calculatorul client, care suporta toate functiile de introducere, afisare si functiile de aplicatie. De regula, accesul la resursele informationale se face cu ajutorul operatorilor unui limbaj specific (SQL, de exemplu, în cazul bazelor de date) sau cu ajutorul functiilor existente în biblioteci de programe specializate. Interogarile realizate catre resursele informationale sunt transmise catre gestionarul de resurse (baza de date din retea, de exemplu), iar acesta executa interogarile si returneaza datele rezultate catre client. Marele avantaj al acestui model, în comparatie cu primul, este faptul ca prin retea se transfera mai putine date, datorita faptului ca selectarea informatiilor necesare din fisiere nu are loc pe statiile de lucru si pe server. În plus, la momentul actual, exista numeroase instrumente de dezvoltare care permit crearea rapida a aplicatiilor, printr-o interfata standard si operând cu SGBD-uri care suporta SQL. In cele din urma, acestea conduc catre unificare, interoperabilitate si posibilitatea de a alege dintr-o gama larga de instrumente de dezvoltare.
Marele dezavantaj al acestui model este acela ca nu exista o linie stricta de demarcare între componenta de prezentare si componenta de aplicatie, acest lucru obstructionând dezvoltarea în continuare a sistemelor de calcul care au arhitecturi bazate pe acest model. În plus, schimbarea unei componente necesita schimbarea întregului sistem.
Ţinând cont de avantajele si dezavantajele de mai sus, putem concluziona ca acest model este cel mai bine utilizat pentru construirea de sisteme de calcul orientate catre procesarea unui volum de informatii moderat, care nu va creste semnificativ în timp. De aceea, complexitatea componentei de aplicatie nu ar trebui sa fie mare.
În comparatie cu modelul cu date controlate la nivel de server, modelul client/server two-tier este mai usor de operat. Acesta a fost dezvoltat considerându-se ca procesarea executata la nivel de client ar trebui limitata la functiile de prezentare, în timp ce functiile aplicatiei si de acces la date sunt executate de server. Functiile aplicatiei pot fi implementate în programe separate sau în proceduri stocate, care sunt executate pe serverul care controleaza accesul la date.
În contrast cu modelul cu date controlate de server, avantajele serverului integrat sunt evidente: eficienta mare si simplitate, administrare centralizata si o reducere a utilizarii resurselor de retea. Ţinând cont de avantajele indicate, este posibil sa concluzionam ca modelul cu server integrat este optim pentru retele mari, orientate catre procesarea unui volum mare de date, sau a unui volum care va creste în timp.
Deoarece componentele de aplicatie au devenit din ce în ce mai complicate si manifesta o cerere crescuta de resurse, poate fi utilizat un server separat (server de aplicatie). Acest lucru produce un model three-tier ca parte a arhitecturii client/server. Primul nivel din acest model este clientul, cel de-al doilea este serverul de aplicatie, iar cel de-al treilea este serverul de date. Arhitectura client/server este una cu doua niveluri doar în momentul în care componentele de aplicatie sunt situate la nivelul statiei de lucru împreuna cu componenta de prezentare, sau la nivel de server, împreuna cu gestionarul de resurse si date.
Prezenta unei demarcatii stricte între componentele aplicatiilor din arhitectura client/server si distribuirea balansata a acestor componente între calculatoarele de retea permite un nivel de flexibilitate care nu este disponibil în arhitectura peer-to-peer. Ca rezultat, resursele de calcul obtin o mai mare performanta, crescând si potentialul pentru îmbunatatirea si marirea functionalitatii sistemului.
Arhitectura client/server, care a aparut la cel de-al doilea stagiu de evolutie a tehnologiei de calcul este cunoscuta si sub numele de arhitectura client/server clasica. Aceasta are urmatoarele caracteristici:
serverul nu genereaza informatiile finale, ci doar date, care pot fi interpretate da catre client;
componentele aplicatiei sunt distribuite între calculatoarele din retea;
pentru schimbul de date între client si server pot fi utilizate protocoale proprietare, incompatibile cu standardul TCP/IP pentru Internet;
fiecare din calculatoarele din retea este orientat doar catre executia de programe locale.
Aceasta ultima caracteristica promoveaza ridicarea securitatii informatiei. În momentul în care pe fiecare calculator sunt executate numai programe locale, nu se produce migrarea programelor din retea în timpul procesarii interogarilor create de client catre server, coborând astfel probabilitatea de executare a programelor malitioase sau a vreunui virus.
Din punct de vedere al stocarii datelor si securitatii procesarii, arhitectura client/server are câteva potentiale dezavantaje:
atât distribuirea fizica a componentelor aplicatiilor cât si iregularitatile si eterogenitatea sistemelor de calcul complica semnificativ construirea si administrarea sistemului de securitate;
partea protejata a resurselor informationale localizata la nivelul calculatoarelor personale este caracterizata printr-o mare vulnerabilitate;
utilizarea protocoalelor proprietare pentru schimbul de date între calculatoare necesita dezvoltarea de instrumente de securitate unice, conducând la cheltuieli aditionale;
exista un timp de recuperare mare în cazul pierderii/distrugerii programelor instalate la nivel de client, fiind necesare proceduri speciale pentru reconectare.
Multe dintre dezavantajele retelelor de calculatoare cu o arhitectura client/server clasica pot fi eliminate prin construirea unui sistem de calcul cu o arhitectura care sa combine cele mai bune proprietati ale sistemului centralizate cu cele ale arhitecturii client/server. Noua arhitectura este numita arhitectura web sau arhitectura client/server bazata pe tehnologie web. Aceasta arhitectura, dezvoltata odata cu dezvoltarea Internetului, este considerata cel de-al treilea stagiu de evolutie a sistemelor de calcul.
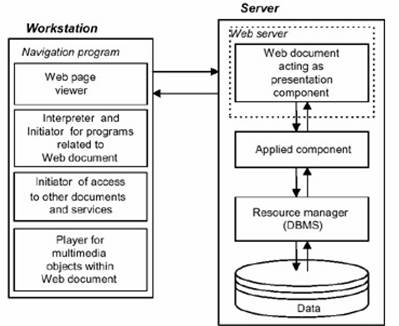
Figura : Arhitectura client/server bazata pe tehnologie web.
Caracteristica esentiala a arhitecturii Internet este întoarcerea catre server a unui numar de functii care au fost eliminate de la calculatorul central în cel de-al doilea stagiu, baza acesteia fiind tehnologia web. Baza tehnologiei web sunt asa-numitele "documente web", stocate pe server si vizualizate si interpretate de programe care opereaza la nivelul statiilor de lucru (navigatoare web/browsere web). Din punct de vedere logic, un document web reprezinta un document hypermedia, care consta din diferite pagini web legate prin legaturi (link-uri). Fiecare pagina web poate contine obiecte si legaturi catre alte pagini. Din punct de vedere fizic, un document web este un fisier text, localizat pe diferite gazde din retea. De fapt, un document web contine numai o singura pagina web, dar logic poate combina orice cantitate de asemenea pagini, care apartin de documente web diferite.
O pagina web poate fi asemanata cu o copie tiparita a unui document, continând atât text cât si imagini. Dar, spre deosebire de documentul tiparit, o pagina web se poate interconecta cu programe de calculator si poate contine legaturi catre alte obiecte. Executia programului conectat la pagina web începe automat în momentul tranzitiei catre legatura potrivita sau la deschiderea paginii web. Sistemul de legaturi obtinut astfel este bazat pe faptul ca anumite parti selectate dintr-un document, care pot fi reprezentate de text sau imagini, actioneaza ca legaturi catre alte obiecte care sunt conectate din punct de vedere logic cu ele. Deci, obiectele catre care conduc legaturile pot fi localizate pe orice calculator din retea. O pagina web poate contine legaturi catre urmatoarele tipuri de obiecte:
alte parti ale unui document web;
alte documente web sau documente care au alte formate (foi de calcul, prezentari etc.), care pot fi localizate pe orice calculator din retea;
obiecte multimedia;
un program care va fi executat pe server dupa tranzitia catre el printr-un link;
un program care va fi transferat de catre browser pentru interpretare sau executie de la server catre statia de lucru;
orice alt serviciu (e-mail, copierea de fisiere prin retea, cautari de informatii);
Din aceasta definitiei a conceptului de document web este clar ca programul de navigare executat la nivel de statie de lucru nu este restrictionat numai la vizualizarea de pagini web si executarea de tranzitii catre alte obiecte, acesta putând fi utilizat atât pentru activarea programelor pe server cât si pentru interpretarea sau lansarea în executie a modulelor legate de documente web pe statia de lucru.
Transferul de documente si de alte obiecte de la server catre statia de lucru dupa o cerere de la browser este îndeplinita de catre un program numit server web. În momentul în care browserul are nevoie de documente sau obiecte de la server, el transmite cererile necesare catre server, iar daca drepturile de acces sunt suficiente se va stabili o conexiune logica între client si server, iar serverul va transmite rezultatele procesarii catre browser, încheind astfel conexiunea.
Serverul web actioneaza ca un concentrator de informatii care transmite informatii din diverse surse si le prezinta utilizatorului sub o forma omogena, iar browserul, cu o interfata universala si naturala, permite utilizatorului sa vizualizeze informatiile respective, aproape indiferent de format.
Cu alte cuvinte, în cadrul documentelor web poate fi obtinuta integrarea datelor si a obiectelor program de diferite tipuri localizate pe diferite gazde din retea. Serverul web permite de asemenea distribuirea informatiilor în concordanta cu ordinea naturala a crearii si consumarii acestora, implementând în acelasi timp un acces uniform la document. Pe lânga faptul ca documentele web conecteaza atât date distribuite din punct de vedere fizic cât si date de diferite tipuri, acestea permit luarea în considerare a informatiilor cu nivel de detalii cerut, ceea ce simplifica semnificativ analiza volumelor mari de date. Exista posibilitatea concentrarii atentiei pe cele mai importante aspecte ale datelor, studiind mai apoi în detaliu materialul selectat. De asemenea, este posibila implementarea unui model multi-metoda în vederea prezentarii informatiilor, creând în acelasi timp vederi diferite ale datelor cerute, în functie de necesitatile utilizatorilor.
Arhitectura Internet cuprinde urmatoarele facilitati distinctive:
informatiile finale care vor fi prezentate utilizatorului de catre navigator sunt create pe server, în forma finala (si nu într-o forma intermediara, ca în cazul arhitecturii client/server clasice);
toate resursele informationale si aplicatiile sistem sunt concentrate pe server;
se utilizeaza protocolul TCP/IP pentru schimbul de date între client si server, protocol utilizat si pe Internet;
este facilitat controlul centralizat nu numai al serverului ci si al calculatoarelor client, deoarece acestea din urma sunt standardizate din punct de vedere al aplicatiei de navigare;
statiile de lucru pot executa programe de pe alte calculatoare din retea nu numai de pe cele locale.
Concentrarea tuturor resurselor informationale si a aplicatiilor la nivel de server simplifica semnificativ construirea si administrarea sistemelor de securitate, protectia obiectelor localizate într-un singur loc fiind realizata mult mai usor decât în cazul distribuirii fizice a acestora. De asemenea, utilizarea protocolului TCP/IP pentru schimbul de date între calculatoarele din retea are ca rezultat unificarea tuturor interactiunilor dintre statia de lucru si server - solutia interactiunii sigure cu un calculator se aplica în mod automat tuturor calculatoarelor.
|
