Chestiuni introductive privind crearea de aplicatii cu baze de date |
Este un fapt evident acela ca majoritatea aplicatiilor în domeniul economic utilizeaza date într-o forma sau alta. Aceste date sunt memorate adesea în una sau mai multe baze de date. Mediul Visual Basic poate crea, cu un efort de planificare si proiectare nu prea mare, programe puternice de gestionare a datelor. Unul din factorii cei mai importanti ai acestei planificari se refera la modul de organizare a datelor. O baza de date prost structurata poate sa conduca la esec chiar având cel mai bine gândit program, în schimb o baza de date bine proiectata poate usura mult munca programatorului.
Pentru a crea o structura de date bine organizata, va trebui sa ne familiarizam cu doua probleme:
Va trebui sa învatam cum sa proiectam o baza de date. În aceasta etapa va trebui sa decidem care date vor trebui incluse în baza de date si cum vor fi ele organizate;
Va trebui sa învatam modul de implementare a bazei de date proiectate în baza de date efectiva, propriu-zisa.
În acest capitol voi lua ca exemplu proiectarea si crearea unei baze de date care contine informatii cu privire la situatia la învatatura a unor studenti dintr-o anumita serie si an de studiu (note la diferitele discipline, absente, total credite obtinute, calculul mediei etc.). Pe baza ei vor fi exemplificate si alte notiuni din aceasta carte.
1.1. Elemente de proiectare a unei baze de date |
Pentru a proiecta o aplicatie cu baze de date trebuie stabilite nu doar rutinele-program, pentru o performanta cât mai buna, ci trebuie acordata de asemenea o foarte mare atentie organizarii fizice si logice a modului de stocare a datelor. O buna proiectare a bazelor de date asigura urmatoarele:
P timp minim de cautare la localizarea unor înregistrari specifice;
P memorarea datelor în modul cel mai eficient posibil pentru a împiedica baza de date sa creasca exagerat de mult;
P actualizarea datelor într-un mod cât mai usor cu putinta;
P o suficienta flexibilitate pentru a permite includerea unor noi functii cerute de program.
La proiectarea unei baze de date trebuie avute în vedere mai multe obiective, care vor fi enumerate mai jos. Desi ar fi ideal sa poata fi împlinite toate aceste obiective de proiectare, în unele cazuri ele se exclud reciproc si ca trebui cautata o solutie optima. Cele mai importante obiective în proiectarea unei baze de date sunt:
P eliminarea datelor redundante;
P capacitatea de a localiza foarte rapid anumite înregistrari individuale;
P posibilitatea de a face îmbunatatiri usor de implementat pentru baza de date;
P pastrarea unei usoare întretineri a bazei de date.
Crearea unui proiect bun de baze de date implica urmatoarele sase etape
1°. Modelarea aplicatiei
2°. Determinarea datelor necesare pentru aplicatie;
3°. Organizarea datelor în tabele si stabilirea relatiilor între acestea;
4°. Stabilirea cerintelor de indexare si de validare pentru datele respective;
5°. Crearea si memorarea interogarilor necesare pentru aplicatie;
6°. Revederea proiectarii.
În cele ce urmeaza vom lua în discutie etapele de mai sus.
1.1.1. Modelarea aplicatiei |
Atunci când modelam o aplicatie, primul lucru pe care trebuie sa-l facem este sa determinam sarcinile pe care aplicatia trebuie sa le rezolve. De exemplu atunci când tinem evidenta studentilor si a rezultatelor acestora la învatatura, se stie ca se doreste posibilitatea calculului mediei fiecaruia dintre acestia, a numarului total de credite cumulat de fiecare în parte si eventual anumite statistici pe ani, grupe, sex sau alte criterii. Determinând sarcinile ce trebuiesc rezolvate de catre aplicatie se creeaza asa-numita specificatie functionala. Atunci când aplicatia pe care o creati este chiar pentru dumneavoastra, probabil ca va sunt clare toate sarcinile pe care doriti ca aplicatia sa le efectueze. Totusi a scrie aceste sarcini într-un document de specificatii este o idee buna. Acest document va poate ajuta sa nu pierdeti din vedere nimic din ceea ce doriti ca programul sa rezolve. Daca însa aplicatia pe care o creati este pentru altcineva, o specificatie functionala poate deveni un acord, o întelegere cu utilizatorul, asupra a ceea ce aplicatia va trebui sa rezolve. Aceste specificari pot constitui jaloane de atins pe parcursul proiectarii aplicatiei.
Atunci când creati programul pentru altcineva, cea mai buna cale de a învata ce operatii trebuiesc efectuate este de a vorbi cu persoana (beneficiarul) în cauza si a pune întrebari. Ca un prim pas ar trebui aflat daca ei nu au deja un sistem pe care doresc sa-l înlocuiasca cu altul mai bun, sau daca au anumite rapoarte pe care doresc sa le obtina. Puneti apoi o sumedenie de întrebari, pâna când ati înteles scopurile utilizatorului pentru programul pe care vi-l solicita.
1.1.2. Determinarea datelor necesare pentru aplicatie |
Dupa determinarea specificatiilor functionale pentru program se poate trece la determinarea datelor de care are nevoie aplicatia. În cazul aplicatiei propuse, cu privire la situatia la învatatura a unor studenti, va trebui sa cunoastem datele personale a fiecarui student, daca acesta este sau nu în regim cu taxa si daca si-a achitat sau nu taxele pentru anul în curs, inclusiv adresa sau telefonul la care acesta poate fi contactat în caz de neplata la timp a taxelor de scolarizare. Apoi trebuiesc cunoscute disciplinele si creditele aferente fiecarei discipline, respectiv notele obtinute la aceste discipline, datele examenelor si numele profesorilor care au dat notele. De asemenea, în cazul cerintei unor situatii pe grupe de studiu este necesar un index sau o interogare care sa afiseze studentii pe grupe, si în cadrul grupelor alfabetic. Se poate astfel observa ca modelul aplicatiei nu da doar indicii cu privire la datele necesare, ci defineste de asemenea alte componente ale bazei de date.
1.1.3. Organizarea datelor în tabele si stabilirea relatiilor între acestea |
Unul din aspectele cheie a unei proiectari eficiente a bazelor de date este determinarea modului în care datele vor fi organizate în baza de date. Pentru o buna proiectare, datele trebuiesc organizate într-un mod care sa permita o usoara extragere a informatiilor si care sa faca baza de date usor de întretinut. În cadrul unei baze de date, datele sunt memorate în una sau mai multe tabele. Pentru cele mai multe aplicatii cu baze de date se poate obtine o organizare eficienta a datelor prin memorarea datelor în mai multe tabele si prin stabilirea unor relatii între aceste tabele.
Tabele. Un tabel este o colectie de informatii cu privire la un anumit subiect. Stabilind un subiect-cheie pentru fiecare tabela se poate stabili daca o anumita data îsi are locul sau nu în respectivul tabel. De exemplu, daca institutia de învatamânt doreste sa tina o evidenta atât a studentilor cât si a profesorilor, proiectantul bazei de date ar putea fi tentat sa introduca datele ambelor categorii de persoane în aceeasi tabela - ambele necesitând nume, prenume, adresa, telefon. Totusi, uitându-ne la datele necesare studentilor, observam ca pentru acestia ar fi necesare si informatii cu privire la grupa de care apartin, la forma de învatamânt (cu sau fara taxa) si la achitarea sau nu a taxei pentru cei în regim cu taxa. Daca s-ar crea o singura tabela pentru studenti si profesori, multe câmpuri ar ramânea astfel necompletate în dreptul profesorilor. De asemenea ar fi necesar atunci sa se adauge un câmp care sa faca distinctia între un student si un profesor. În mod clar aceasta metoda ar conduce la mult spatiu de memorare ocupat fara nici un rost. De asemenea ar rezulta o procesare mai lenta a tranzactiilor care vizeaza numai studentii sau numai profesorii, deoarece programul va trebui sa sara tot timpul peste anumite înregistrari din tabel care nu intereseaza. Figura 1.1. arata o tabela de baza de date cu cele doua categorii (studenti si profesori) combinate. Figura 1.2. arata reducerea numarului de câmpuri într-un tabel doar cu profesorii.
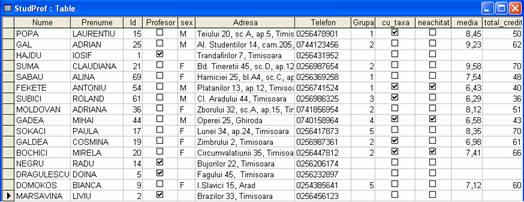
Figura 1.1. Combinarea într-o singura tabela a studentilor si profesorilor duce la risipa mare de spatiu
Normalizarea datelor |
A normaliza datele înseamna a elimina datele redundante dintr-o baza de date. Închipuindu-ne normalizarea dusa la extrem, acest lucru ar însemna ca fiecare informatie sa nu apara decât o singura data într-o baza de date. Practic însa acest lucru nu este întotdeauna posibil si nici de dorit.
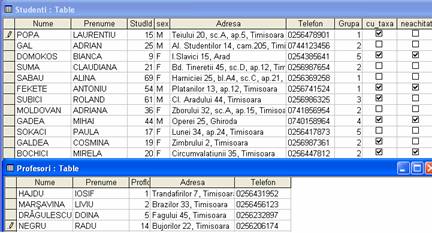
Figura 1.2. O tabela separata pentru profesori contine doar câmpurile care intereseaza si este mai eficienta
Observati, privind la figura 1.2, ca nu am introdus în tabela Studenti nici o informatie cu privire la vreun anumit examen, data acestuia, disciplina si profesorul, respectiv nota primita cu acea ocazie. Aceasta deoarece este de preferat ca informatiile cu privire la examene si note sa fie separate de tabela studentilor pentru ca diferitele informatii suplimentare cu privire la adresa, telefon sex, grupa, achitarea taxelor etc. sa nu se repete si aici, ci referirea la un anumit student sa se faca prin numarul acestuia de identificare, deci printr-un câmp numit de noi StudId. Similar în tabela cu înregistrarile notelor obtinute la diferitele examene se va face referirea la profesorul cu care s-a dat examenul prin numarul de identificare al acestuia, numit în acest exemplu ProfId - aceasta de asemenea pentru a nu încarca tabela notelor cu toate informatiile suplimentare care exista în tabelul Profesori cu privire la un anumit profesor.
Observatie. Aceste câmpuri de identificare, StudId din tabelul Studenti si ProfId din tabelul Profesori contin întotdeauna valori unice, distincte. Ele vor constitui si chei primare în respectivele tabele. Aceasta înseamna, spre exemplu, ca o anumita valoare a lui StudId poate exista doar pentru o singura înregistrare din tabelul Studenti si nu poate fi duplicata. Astfel va putea fi distins un anumit student de altul, chiar daca cei doi ar avea nume identice, si poate - prin absurd - si adrese sau orice alte câmpuri identice
Prin urmare, daca se plaseaza toate aceste date cu privire la notele studentilor într-o singura tabela, rezultatul ar arata asemanator ce ceea se poate vedea în figura 1.3. Deja aici citirea tabelei se complica la o simpla privire fugara, deoarece în locul numelor studentului si al profesorului avem numerele de identificare a acestora, care trebuie sa ne faca legatura cu tabelele Studenti si Profesori pentru a putea afla cine sunt acestia.
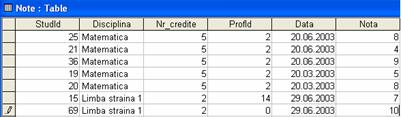
Figura 1.3. Datele nenormalizate conduc la tabele de date mari, ineficiente
Din figura de mai sus rezulta clar faptul ca în tabela Note foarte multe date se repeta. Aceasta repetare a unor informatii are doua urmari nedorite:
În primul rând se risipeste spatiu, deoarece multe informatii se repeta de nenumarate ori;
În al doilea rând ar putea fi un factor de pierdere a corectitudinii unor date. Daca de exemplu se hotaraste ca unei anumite discipline sa i se acorde un numar mai mare sau mai mic de credite decât s-a stiut initial, aceasta modificare va trebui facuta asupra tuturor înregistrarilor care se refera la respectiva disciplina, cu posibilitatea de a gresi si a lasa vreuna din înregistrarile mai vechi nemodificata.
O metoda mai buna de a organiza datele va fi de a separa disciplinele de note, si chiar si datele cu privire la un anumit examen de note. Astfel în tabela Discipline vor aparea doar denumirea disciplinei cu numarul de credite aferent si un identificator de disciplina (DId), în tabela Examene doar data, identificatorul de disciplina (DId), profesorul cu care s-a dat examenul - cunoscut prin identificatorul de profesor (ProfId) si un identificator de examen (ExId), iar în tabela Note doar identificatorul de student (StudId), nota si identificatorul de examen (ExId). Pentru identificatorul DId din tabela Discipline si pentru identificatorul ExId din tabela Examene ramâne valabila observatia enuntata în nota anterioara: Aceste câmpuri vor contine valori distincte si unice în tabelele respective si vor constitui chei primare în acele tabele. Astfel rezulta în locul tabelului din figura 1.3, trei tabele distincte de genul celor din figura 1.4.
Desigur, citirea datelor din aceste trei tabele este acum mult mai abstracta decât înainte, si pentru ochiul nostru ar putea parea mult prea complicat. Totusi , bazele de date asa-numit relationale se descurca foarte bine cu tabele de acest fel. Pentru aceasta ele utilizeaza chei de date. De exemplu tabela Note din figura 1.4 are un câmp numit ExId care, dupa cum o sugereaza si denumirea, va fi un identificator de examen. Acelasi câmp ExId este continut si în tabela Examene, unde însa ExId este cheie primara. Aceasta înseamna, dupa cum am enuntat deja în nota scrisa cu caractere italice mai sus, ca o anumita valoare a lui ExId poate exista doar pentru o singura înregistrare din tabela Examene
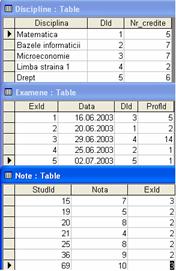
Fig. 1.4. Normalizarea completa a tabelelor asigura eficienta maxima.
Practic, fiecare înregistrare a tabelei Examene va contine un examen distinct, caracterizat printr-o anumita data, un anumit profesor (referit prin ProfId) si o anumita disciplina (referita prin identificatorul de disciplina DId
Spunem ca cele doua tabele Note si Examene sunt în relatie prin intermediul câmpului ExId. Observati însa ca în tabelul Note câmpul ExId nu va fi cheie primara, ci aici se va numi cheie straina, deoarece este în legatura cu câmpul ExId din tabela Examene si acel câmp este un câmp cheie. Totusi, în tabela Note, acelasi identificator de examen ExId se poate repeta de câte ori este necesar.
De asemenea în tabela Examene mai apar câmpurile DId si ProfId, care se regasesc si în tabelele Discipline si respectiv Profesori, tabele în care sunt în mod evident chei primare. Ele vor fi însa chei straine pentru tabelul Examene, în care pot aparea de câte ori este nevoie. Astfel nu vor fi restrictii în ce priveste posibilitatea ca un anumit profesor sa predea mai multe discipline sau o anumita disciplina sa fie predata de mai multi profesori - desigur la diversi elevi.
În concluzie: Într-o baza de date relationala, fiecare tabela are o cheie primara ce reprezinta un câmp (sau o combinatie de câmpuri) prin ale carui (carei) valori se identifica fara ambiguitate fiecare linie a tabelei. Unele tabele au si o cheie straina, ce reprezinta un câmp, care este cheie primara într-o alta tabela. Valorile cheii straine dintr-o tabela nu pot fi decât valori ale cheii primare din tabela corespondenta. Aceasta regula se numeste restrictie referentiala.
Microsoft Access ofera o reprezentare vizuala foarte sugestiva a relatiilor dintre tabelele unei baze de date. Modul de obtinere a acestei reprezentari este aratat la finalul unui paragraf viitor, si anume 1.2.1. În cazul exemplului discutat mai sus relatiile sunt reprezentate în Microsoft Access ca în figura 1.5.
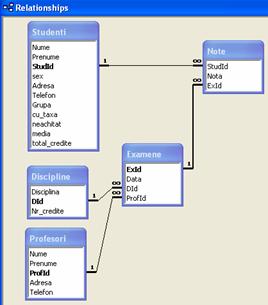
Figura 1.5. Reprezentarea relatiilor între tabelele unei baze de date în Microsoft Access
Câmpurile îngrosate reprezinta chei primare în tabelele
respective, iar simbolurile legaturilor (cifra 1 si simbolul ![]() ) indica faptul
ca, spre exemplu, unei singure înregistrari din tabelul Studenti, îi pot corespunde mai
multe înregistrari din tabelul Note
) indica faptul
ca, spre exemplu, unei singure înregistrari din tabelul Studenti, îi pot corespunde mai
multe înregistrari din tabelul Note
Sa încercam acum sa "citim" prima înregistrare din tabela Note în varianta ultima din figura 1.4. Studentul cu numarul de identificare 15 - deci POPA LAURENTIU (vezi figura 1.2.) a obtinut nota 7 la examenul cu numarul de identificare 3 - adica cel din data de 29.06.2003 (vezi tabela Examene din figura 1.4.) la disciplina cu numarul de identificare 4 (adica Limba straina 1 daca se urmareste tabelul Discipline) cu profesorul având numarul de identificare 14 - deci NEGRU RADU, rezultat din tabela Profesori. Comparati acum ceea ce ati citit cu informatiile extrase din tabela Note din figura 1.3. Desigur ele sunt identice si la fel vor fi si urmatoarele înregistrari.
Reguli pentru organizarea tabelelor |
Practic nu exista reguli absolute care sa delimiteze care date în care tabele trebuiesc introduse, dar, cu toate acestea am putea enumera câteva reguli generale care ar trebui urmarite pentru a proiecta o baza de date bine structurata. Acestea ar fi:
Orice tabel trebuie sa aiba o tema, de exemplu "Informatii despre abonati" sau "Tranzactii ale clientilor". Încercati sa va limitati la o singura tema pe tabel.
Spargeti tabela în doua tabele similare în cazul în care un numar de înregistrari au câmpuri lasate necompletate în mod intentionat (ca si despartirea tabelei Profesori de tabela Studenti
Mutati într-o alta tabela a informatiilor care se repeta într-un numar de înregistrari si stabiliti o relatie între acele tabele.
Daca exista o lista cu informatii de referinta, pe care vreti sa o pastrati (cum ar fi disciplinele si numarul de credite aferente fiecareia), puneti-le în propriul tabel.
Unde este posibil, folositi numere de identificare, ele ajutându-va sa legati tabele între ele si sa evitati greselile de dactilografie datorate introducerii unor siruri lungi de date (cum sunt numele).
Nu stocati informatii într-un tabel daca acestea pot fi calculate din datele altor tabele.
Adeseori, din motive de performanta, se ocolesc unele din aceste reguli. De exemplu, daca pentru a obtine vânzarile totale pentru un anumit vânzator este necesara însumarea mai multor mii de înregistrari, poate se merita a include un câmp de Vanzari totale în tabela Vanzatori, câmp care sa fie actualizat de câte ori se face o vânzare. În acest fel, atunci când sunt generate rapoarte, aplicatia nu va trebui sa efectueze un numar mare de calcule si procesul de raportare va fi mult mai rapid.
Un alt motiv pentru a devia de la aceste reguli este evitarea deschiderii unui numar prea mare de tabele în acelasi timp. Aceasta deoarece fiecare tabela deschisa utilizeaza resurse pretioase si de asemenea spatiu de memorare, încât aplicatia ar putea pierde considerabil din viteza.
Pe de alta parte, devierea de la aceste reguli de structurare a tabelelor conduce la doua probleme majore:
- cresterea marimii bazei de date din cauza datelor redundante;
- posibilitatea de a avea la un moment dat date incorecte din cauza ca s-a modificat continutul anumitor câmpuri si, dintr-un motiv sau altul, nu toate înregistrarile afectate au fost actualizate.
În concluzie va trebui cautat un optim între performanta aplicatiei si eficienta stocarii datelor în tabele.
1.1.4. Utilizarea indecsilor |
Atunci când se introduc date într-un tabel, înregistrarile sunt stocate în general în ordinea în care ele sunt introduse. Aceasta este ordinea fizica a datelor. De obicei însa utilizatorii doresc sa proceseze datele într-o ordine diferita de cea în care au fost introduse înregistrarile în tabele. Aceasta presupune definirea unei asa-numite ordini logice. Aceasta ordine logica va fi de asemenea utila atunci când se va dori cautarea într-un tabel a unei anumite înregistrari.
Indexarea este metoda cel mai des utilizata de a ordona tabelele de date. Un index este de asemenea o tabela, care contine o valoare cheie (derivata de obicei din valorile a unul sau mai multe câmpuri) pentru fiecare înregistrare din tabela de date; indexul însusi este memorat într-o ordine logica specifica si contine pointeri (indicatori de adrese) care spun motorului de baze de date unde este localizata înregistrarea curenta.
Indecsii sunt setati la proiectarea tabelei cu scopul de a mari viteza si de a garanta unicitatea unei înregistrari. Cartea de telefoane de exemplu este o lista indexata dupa nume. Atunci când cautati numarul de telefon al unei persoane îl puteti gasi rapid uitându-va doar la câteva pagini, daca stiti care este numele persoanei. Daca numerele de telefon ar fi date în cartea de telefon în ordinea în care au fost ele atribuite abonatilor, o astfel de carte nu ar folosi nimanui, fiind aproape imposibil de a gasi numarul unei anumite persoane.
O tabela poate avea mai multi indecsi diferiti asociati, pentru a asigura pentru anumite situatii ordonarea datelor într-un fel sau în altul. De exemplu tabela studentilor ar putea fi utila în ordine alfabetica a acestora sau poate în ordinea grupelor si eventual alfabetic în cadrul fiecarei grupe sau, poate, descrescator dupa media rezultata în urma introducerii notelor de examen. Fiecare index arata aceleasi date într-o ordine diferita, pentru un scop diferit.
Observatii.
1. Chiar daca este de dorit sa putem avea vederi diferite asupra datelor în toate ordonarile posibile, trebuie avut în vedere ca pentru baze de date mari a mentine o varietate foarte mare de indecsi poate prejudicia performanta aplicatiei, deoarece toti indicii trebuie actualizati ori de câte ori datele se modifica. si în aceasta problema programatorul aplicatiei va trebui sa aleaga o varianta optima de compromis.
2. Se pot însa crea diferite vederi a informatiilor dintr-un tabel si prin sortarea înregistrarilor sau prin specificarea unei ordini dorite utilizând clauza ORDER BY a unei comenzi SQL (Structured Query Language). Chiar daca indecsii nu sunt utilizati direct de un motor SQL, prezenta lor maresc viteze procesului de sortare atunci când exista o clauza ORDER BY.
Indexul poate fi un câmp sau o combinatie de câmpuri, iar câmpurile ar putea necesita valori unice sau nu. Daca un index necesita o valoare unica, el este denumit index unic.
Cele mai obisnuite tipuri de indecsi sunt cei cu expresii cheie singulare, adica cei bazati pe valoarea unui singur câmp din tabel. Exemple de astfel de indecsi sunt identificatorul de student (StudId) sau numele studentului (Nume) sau grupa (Grupa) etc. pentru tabela Studenti. Atunci când exista mai multe înregistrari cu aceeasi valoare a cheii de indexare, asa cum ar putea fi cazul cu numele studentului sau cum este sigur cazul cu indexarea dupa grupa, înregistrarile multiple sunt prezentate în ordinea fizica în cadrul ordinii impuse de indexul cheie singular. Figura 1.6 arata cum va arata tabela Studenti (cu ordinea fizica data în figura 1.2) în urma indexarii dupa câmpul Grupa
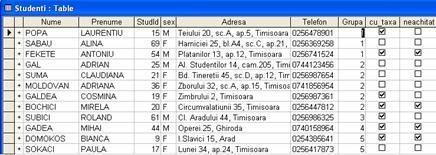
Figura 1.6. Tabela Studenti indexata dupa câmpul Grupa
Totusi, nu de putine ori ar putea fi necesara o ordine mai exacta. Acest lucru se poate face utilizând expresii cu chei de indexare multiple. Dupa cum si numele o spune, indexul cheie multipla se bazeaza pe valorile din doua sau mai multe câmpuri ale unui tabel. Un exemplu ar fi sa indexam tabelul Studenti dupa grupa si în cadrul grupei alfabetic dupa nume (si poate chiar la nume identice alfabetic dupa prenume). Daca totusi exista înregistrari care sa aiba aceiasi valoare cheie pentru doua sau mai multe înregistrari, acestea vor aparea ca si în cazul indecsilor cu chei singulare în ordinea fizica a înregistrarilor. În figura 1.7 se poate vedea tabela Studenti indexata cu o cheie multipla dupa Grupa, Nume si Prenume
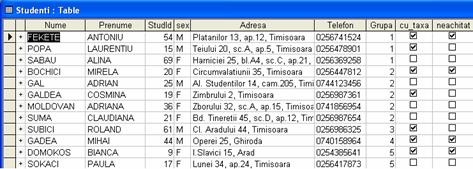
Figura 1.7. Tabela Studenti cu index cheie multipla dupa câmpul Grupa, Nume si Prenume
1.1.5. Utilizarea interogarilor |
Atunci când normalizati datele, de obicei plasati informatiile înrudite în mai multe tabele relationale. La accesarea datelor însa, veti dori sa vedeti informatiile din toate tabelele într-un singur loc, denumit tabela virtuala (view). Aceasta tabela practic nu exista ca atare, dar în baza de date este memorata descrierea ei. Aceasta descriere precizeaza ca datele view-ului provin dintr-o portiune a unei tabele, din mai multe tabele ori din mai multe portiuni ale mai multor tabele. Pentru a reusi acest lucru este necesara crearea de seturi de înregistrari, care sa consolideze informatiile legate prin relatii si aflate în doua sau mai multe tabele.
Un set de înregistrari se creeaza din mai multe tabele utilizând o comanda SQL care specifica numele câmpurilor dorite, locatia câmpurilor si relatia dintre tabele. Comanda SQL se poate însa memora ca o interogare (Query) în baza de date. (A se vedea capitolul cu privire la comenzile SQL).
Crearea unei baze de date utilizând Microsoft Access |
Microsoft Access are o interfata vizuala de proiectare foarte facila, pentru a defini tabele, indecsi, interogari si relatii între tabele. Este evident instrumentul cel mai performant de lucru cu bazele de date, mult superior lui Visual Data Manager, care are înca unele lipsuri mari (de exemplu pentru operatia simpla de modificare a tipului unui câmp dintr-o structura existenta a unui tabel trebuie recurs la artificii destul de complicate).
Foarte pe scurt va fi prezentata în continuare crearea bazei de date Catalog.mdb si a uneia din tabelele acesteia, de exemplu tabela Studenti
Crearea unui fisier nou de tip baza de date se face selectând File | New | Blank Database si alegând apoi folderul si tastând numele (Catalog) pentru noul fisier .mdb care va fi creat. La clic pe butonul Create va apare fereastra, în cazul de fata Catalog : Database, fereastra ce va contine toate obiectele bazei de date care - dupa dorinta - se vor adauga pe parcurs, ca: tabele (Tables), interogari (Queries), formulare (Forms), rapoarte (Reports) etc. (vezi figura 1.8).
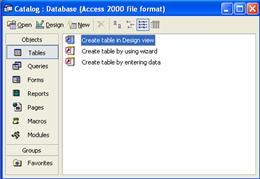
Figura 1.8. Fereastra Database a bazei de date Catalog.mdb
Acum utilizatorul are posibilitatea sa creeze noile tabele ale bazei de date alegând una din cele trei variante afisate în fereastra din figura 1.8:
P Create table in Design view - varianta pe care o vom utiliza efectiv mai jos;
P Create table by using the wizard - varianta care ne conduce la alegerea unei structuri de tabel cu ajutorul unui vrajitor, utilizând modele de structuri tabelare pentru cele mai diverse aplicatii economice, de afaceri, etc.;
P Create table by entering data - o varianta simplista si cu facilitati reduse de a defini un tabel prin introducerea liniilor de date în acesta si denumirea coloanelor cap de tabel, care vor deveni numele câmpurilor respective.
Se recomanda în general prima din variantele de mai sus ca fiind cea mai flexibila si performanta modalitate de a defini o tabela.
Alegând cu un dublu clic de mouse prima din cele trei variante, va apare o fereastra Table pentru definirea structurii noii tabele, ca cea din figura 1.9, în care se introduc pe rând numele câmpurilor, se alege din lista derulanta (Data Type) tipul dorit (Text, Memo, Number, Date/Time etc.) si se da o eventuala descriere a câmpului (un comentariu) în rubrica Description. În partea de jos a ferestrei Table, pagina General vor putea fi setate proprietati suplimentare cu privire la câmpul respectiv, proprietati care depind de tipul câmpului ales.
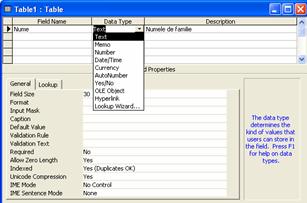
Figura 1.9. Fereastra Table pentru definirea structurii unei tabele
Observatii.
Pentru datele de tip Text proprietatea FieldSize indica lungimea în numar de caractere a câmpului.
Pentru datele numerice Number, proprietatea FieldSize ofera o lista de subtipuri numerice, ca Long Integer (valoarea implicita), Byte, Integer, Single, Double etc. din care se poate alege cea care corespunde cel mai bine tipului de date care va fi stocat în respectivul câmp.
Valoarea implicita cu care se initializeaza un câmp la adaugarea unei noi înregistrari este specificata de proprietatea DefaultValue.
Daca proprietatea Required are valoarea Yes, atunci trebuie sa se dea o valoare pentru câmpul respectiv. Câmpul nu poate ramâne necompletat în varianta ca mai târziu o valoare va fi oricum precizata.
Câmpurile de tip Text si Memo pot avea ca valoare siruri de lungime 0 (vid) daca proprietatea AllowZeroLength are valoarea Yes.
Proprietatea ValidationRule permite precizarea unei conditii de validare a câmpului respectiv, (de exemplu: >0 în dreptul unui câmp numeric).
Daca eventuala regula precizata de proprietatea ValidationRule nu este îndeplinita, atunci se poate afisa un mesaj de eroare precizat prin proprietatea ValidationText.
Cu proprietatea Format se poate specifica un format de afisare a valorii câmpului, format care poate fi în general ales dintr-o lista derulanta care este diferita de la un tip de date la altul.
Pentru tipurile de date Text sau Date/Time proprietatea InputMask ofera posibilitatea de a preciza un sablon de introducere a datelor, ca de exemplu un anumit sablon pentru introducerea numerelor de telefon (care, având de multe ori zerouri în fata, trebuiesc declarate de tip Text si nu Number!) sau pentru introducerea datelor calendaristice.
Proprietatea Caption precizeaza un sir de caractere care se ataseaza câmpului si care va aparea ca si cap de coloana în locul numelui acestuia, atunci când se va deschide tabela (cu meniul Open din fereastra Database).
Proprietatea Indexed se refera la crearea unui index sau nu pe baza valorilor câmpului respectiv, si permite alegerea uneia din urmatoarele trei variante:
No - nu se indexeaza dupa respectivul câmp;
Yes (Duplicates OK) - se indexeaza dupa câmpul respectiv, care poate avea valori identice în doua sau mai multe înregistrari;
Yes (No Duplicates) - se indexeaza dupa câmpul respectiv, nefiind permise valori identice în doua sau mai multe înregistrari.
Dupa definirea structurii tabelei prin completarea câmpurilor în fereastra Table si a proprietatilor acestora, se închide fereastra Table cu butonul de închidere. Va apare o fereastra cu întrebarea: Do you want to save changes to the design of Table1?, la care desigur ca se va raspunde cu Yes pentru a salva structura definita anterior, urmând a da apoi numele tabelei, respectiv Studenti. Daca pentru tabela respectiva nu s-a definit nici o cheie primara, va apare mesajul din figura 1.10:
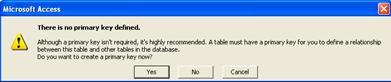
Figura 1.10. Mesajul cu privire la lipsa definirii unei chei primare
La întrebarea din mesaj se poate alege Yes, caz în care se va crea un câmp nou cu numele ID de tip Autonumber (numar cu autoincrementare de la o înregistrare la alta), care va fi considerat cheie primara, sau No, caz în care se salveaza structura tabelei asa cum era, fara nici o cheie primara. Daca se alege raspunsul Cancel se revine în fereastra de definire a structurii Table fara a se efectua nici o salvare.
În cazul ca s-a ales unul din raspunsurile Yes sau No, structura tabelei a fost creata si în fereastra Database a aparut tabela Studenti (vezi figura 1.11).
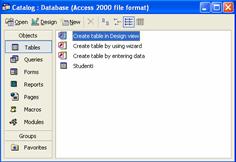
Figura 1.11. Fereastra Database în care s-a creat tabela Studenti
Daca
dupa ce s-a salvat tabela sub numele Studenti
se constata ca s-a gresit sau s-a uitat ceva la definirea
structurii tabelei, se selecteaza tabela Studenti din fereastra 1.11 si se alege din meniul contextual
al acesteia Design View (sau se
da clic pe butonul ![]() ).
).
Astfel
se deschide din nou fereastra Table,
în care se pot insera sau sterge linii (cu comenzile Insert Rows sau Delete Rows
din meniul contextual atunci se selecteaza o anumita linie), se pot
redenumi câmpuri sau modifica proprietatile acestora, se pot
adauga proprietati de indexare, reguli de validare etc. ca
si la crearea structurii unei tabele noi, respectiv se poate alege ca un
anumit câmp sa devina cheie primara de indexare (selectând linia
cu câmpul respectiv si dând un clic pe butonul ![]() Primary Key din bara de unelte
standard Microsoft Access atunci când este deschisa o tabela în modul
Design view). În final, structura
tabelei Studenti în fereastra Design view ar arata ca în figura 1.12.
Primary Key din bara de unelte
standard Microsoft Access atunci când este deschisa o tabela în modul
Design view). În final, structura
tabelei Studenti în fereastra Design view ar arata ca în figura 1.12.
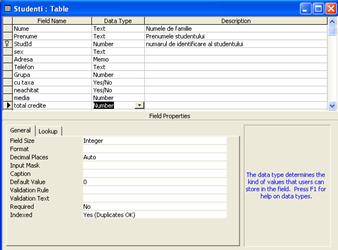
Figura 1.12. Structura tabelei Studenti în modul Design view
Pentru setari suplimentare a
indecsilor în ceea ce priveste ordinea, eventual descrescatoare,
de indexare, respectiv setarea unor indecsi dupa câmpuri multiple, va
trebui, tot din modul Design view,
selectat butonul Indexes ![]() . Pe ecran va apare fereastra Indexes, în care se specifica numele
indexului, unul sau mai multe câmpuri care intra în componenta
respectivului index si ordinea de sortare crescatoare (este
implicita) sau descrescatoare. Figura 1.13 arata fereastra Indexes în cazul tabelei Studenti
. Pe ecran va apare fereastra Indexes, în care se specifica numele
indexului, unul sau mai multe câmpuri care intra în componenta
respectivului index si ordinea de sortare crescatoare (este
implicita) sau descrescatoare. Figura 1.13 arata fereastra Indexes în cazul tabelei Studenti
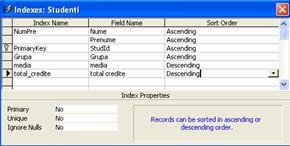
Figura 1.13. Fereastra Indexes pentru tabela Studenti
Observati în figura 1.13 ca NumPre este numele unui index câmp multiplu, în care indexarea se va face în primul rând crescator dupa nume, iar la nume identice dupa prenume.
Dupa efectuarea tuturor modificarilor se închide fereastra Table si apare o fereastra cu mesajul: Do you want to save changes to the design of table ′Studenti′ ?, la care, pentru a salva toate modificarile, se raspunde cu Yes.
Pentru a introduce date în
tabelele create se da dublu clic pe tabela dorita din fereastra Databases (sau se alege optiunea Open din meniul contextual care apare la
un clic dreapta de mouse pe tabele selectata, sau se alege butonul ![]() ) - a se vedea figura 1.11. În fereastra
aparuta se introduc datele dorite, ca în figura 1.14.
) - a se vedea figura 1.11. În fereastra
aparuta se introduc datele dorite, ca în figura 1.14.
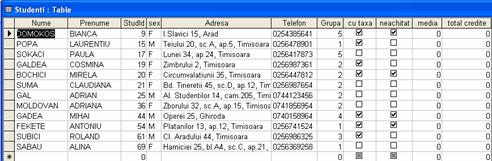
Figura 1.14. Datele introduse în tabela Studenti
Observatie. În general, datele vor fi introduse prin program si nu în modul prezentat mai sus. S-a dat si varianta aceasta doar ca exemplu didactic.
În ceea ce priveste crearea relatiilor, Microsoft Access ofera o reprezentare vizuala foarte sugestiva a relatiilor dintre tabelele unei baze de date. Aceasta reprezentare permite utilizatorului sa traga o linie între câmpurile relationale din tabele sau interogari. Astfel, din mediul Access daca alegem optiunea Relationships... din meniul Tools sau dam clic pe icon-ul corespunzator din bara de unelte standard, obtinem o fereastra intitulata Relationships Cu un simplu clic dreapta oriunde în aceasta fereastra putem adauga, prin intermediul optiunii Show Tables, câte o tabela a bazei de date. Apoi, cu metoda drag-and-drop se "traseaza" practic relatiile dintre tabele, unind câmpurile care fac legatura între doua tabele. Butonul de mouse se elibereaza când indicatorul mouse-ului va deveni un mic dreptunghi fixat pe câmpul destinatie. În caseta de dialog Relationships care apare se cere definirea legaturii pe care vrem sa o realizam. Tot aici, de obicei, se bifeaza optiunea Enforce Referential Integrity, care are rolul de a ne împiedica sa facem greseli la introducerea datelor.
În cazul exemplului discutat mai sus, relatiile sunt reprezentate în Microsoft Access ca în figura 1.5 de la paragraful 1.1.3.1.
Câmpurile îngrosate reprezinta chei primare în tabelele
respective, iar simbolurile legaturilor (cifra 1 si simbolul ![]() ) indica faptul
ca, spre exemplu, unei singure înregistrari din tabelul Studenti, îi pot corespunde mai
multe înregistrari din tabelul Note
) indica faptul
ca, spre exemplu, unei singure înregistrari din tabelul Studenti, îi pot corespunde mai
multe înregistrari din tabelul Note
Modificari asupra unei baze de date |
Oricât de bine ar fi proiectata si implementata o baza de date, nu e exclus ca la un moment dat sa fie necesara modificarea structurii bazei de date si a tabelelor ei componente pentru a gestiona si alte date. Modificarile pot însemna noi tabele sau indecsi în cadrul tabelelor, sau schimbari în proprietatile tabelelor, câmpurilor sau indecsilor. Câteodata s-ar putea dori stergerea unei tabele, unor câmpuri sau indecsi.
|
