TEHNOLOGIA SISTEMELOR INFORMATICE ECONOMICE
2.1. Organizarea datelor
2.1.1. Niveluri de organizare a datelor
Prin date întelegem valori ce pot fi stocate si care au semnificatie implicita. Ca exemplu, sa consideram numele, numarul de telefon, adresa persoanelor cunoscute. Se pot tine toate aceste informatii într-un carnet indexat alfabetic, sau pe o discheta într-un calculator personal utilizând programe specializate pentru aceasta.
Organizarea datelor presupune definirea si structurarea datelor în memoria interna sau în memoria externa (în colectii) si stabilirea legaturilor între date, conform unui model de date.
O structura de date defineste un grup de date (omogene sau eterogene) între care s-au stabilit o serie de legaturi în scopul realizarii unor mecanisme de identificare, selectie si prelucrare a componentelor acestui grup.
Organizarea datelor în structuri se realizeaza pe doua nivele: logic si fizic. Procesul de prelucrare a datelor (mai ales când acestea sunt de volum mare) impune necesitatea ca acestea sa fie uniform structurate, conform unor modele - nivelul logic. La nivel fizic forma de organizare si conservare a datelor este fisierul, care permite stocarea, identificarea si consultarea datelor memorate pe suporturile de stocare. Fiecare fisier cuprinde un grup de elemente numite înregistrari, articole (record). Înregistrarea este o entitate semantica care asociaza (prin legaturi) date de tip diferit, conform modelului de organizare utilizat.
Într-un calculator datele sunt stocate în memoria interna (temporar) si în memoria externa (persistent).
În memoria externa, evolutia modului de memorare a datelor a fost determinata de:
Accesul cât mai rapid si usor la date;
Stocarea unui volum cât mai mare de date;
Cresterea complexitatii datelor;
Perfectionarea echipamentelor de culegere, stocare, transmitere si prelucrare a datelor.
Evolutia organizarii datelor în memoria externa a avut în vedere câteva aspecte, tabelul 2.1.
Uzual datele sunt pastrate sub forma de înregistrari. O înregistrare este o colectie a valorilor datelor relationale, în care fiecare valoare este formata din unul sau mai multi bytes si corespund unui câmp particular al înregistrarii. Un câmp este o structura de date asociata grupurilor de înregistrari. Înregistrarile descriu entitati tip, valorile din câmpuri atributele lor, între înregistrari existând o serie de relatii.
Evolutia organizarii datelor în memoria externa
Tabelul 2.1. 
|
Aspecte Etape |
Mod de organizare a datelor (2) |
Structura de date |
Mod de prelucrare (4) |
Redundanta (5) |
Software utilizat (6) |
|
1. Înainte de 1965 |
Fisiere secventiale |
Logica coincide cu fizica |
Pe loturi (batch) |
Mare, necontrolat |
Operatii simple de I/E (limbaj asamblare si universal) |
|
2. Anii '60 |
Fisiere secventiale, indexate, directe |
Logica si fizica |
Loturi, on-line |
Mare, necontrolat |
Chei simple de acces (limbaje universale) |
|
3. Anii '70 |
Baze de date arborescente, retea |
Logica, fizica, conceptuala |
Loturi, conventional |
Scade, controlat |
Chei multiple de acces, legaturi între date, protectia (SGBD) |
|
4. Sfârsitul anilor '70 pâna acum |
Baze de date relationale |
Logica, fizica, conceptuala |
Conventional, interactiv |
Mica, controlat |
Limbaje de regasire, protectie,concurenta (SGBD) |
|
5. Sfârsitul anilor '80 pâna acum |
Baze de date orientate obiect |
Logica, fizica, conceptuala |
Interactiv |
Minima, controlat |
Limbaje din programarea OO (SGBD) |
Ca exemplu, înregistrarile corespunzatoare entitatii ANGAJAT, sunt formate din mai multe câmpuri, fiecare valoare a câmpului specifica aceleasi atribute sau relatii ale entitatii angajat cum sunt Nume, Salariu, etc. O colectie a numelor câmpurilor, împreuna cu tipul datelor corespunzatoare formeaza o înregistrare tip, sau format. O data tip asociata fiecarui câmp indica tipul valorilor câmpului respectiv.
Tipul de date pentru un câmp poate fi unul din tipurile standard utilizate în programare. Sunt astfel incluse date de tip numeric (întreg, real, real lung), caracter sau sir de caractere (de lungime fixa sau variabila), boolean (având valoarea 0 sau 1 logic, respectiv "false" sau "true"), precum si alte tipuri speciale de date, ca data calendaristica, variabile memorate etc. Numarul de bayti pentru fiecare data tip poate fi fixat sau este variabil pentru câmpurile de lungime variabila.
Una dintre schemele clasice de reprezentare a evolutiei organizarii datelor în aplicatiile complexe este cea din figura 1. Cele cinci elemente arhitecturale au fost înglobate, treptat, în "stratul" baza de date, trecând astfel în sarcina programatorilor. Prima etapa este reprezentata de sisteme care utilizeaza modelul file-based (pre-baze de date), a doua - modelul retea, a treia - modelul relational, iar ultima, în curs de maturizare, este etapa SGBD-urilor orientate pe obiecte. Schemei i se poate reprosa absenta unui model important, din care a derivat cel de retea, si anume modelul ierarhic.

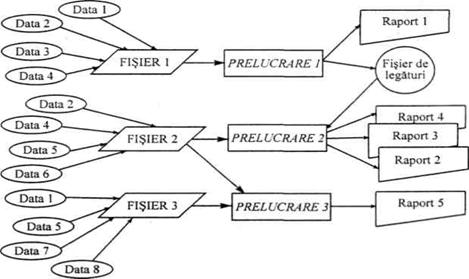
DATE FIsIERE PRELUCRĂRI IEsIRI
Fig.2. 2. Organizarea datelor în fisiere independente
Spre exemplu, Data2 este prezenta în doua fisiere de date, FIsIERl si FIsIER2. Daca, prin program, se modifica formatul sau valoarea acesteia în FIsIERl, modificarea nu se face automat si în FIsIER2; prin urmare, o aceeasi data, Data2, va prezenta doua valori diferite în cele doua fisiere, iar necazurile bat la usa: informatiile furnizate de sistemul informatic sunt redundante si prezinta un mare risc de pierdere a coerentei.
Acestui model de lucru i se pot imputa câteva dezavantaje majore, printre care:
o redundanta si inconsistenta datelor;
o dificultatea accesului;
o izolarea datelor;
o complexitatea deosebita a actualizarilor;
o probleme de securitate;
o probleme legate de integritatea datelor;
o imposibilitatea de a obtine raspunsuri rapide la probleme ad-hoc simple;
o costul ridicat;
o inflexibilitatea fata de schimbarile ulterioare, ce sunt inerente oricarui sistem informational;
o modelarea inadecvata a lumii reale.
Se poate defini un fisier ca o colectie de înregistrari, eventual similare ce tine cont de modul de stocare a datelor în calculator. Daca toate înregistrarile au exact aceeasi marime (în bytes), fisierul se spune ca este cu înregistrari de lungime fixa. Daca înregistrarile aceluiasi fisier au marimi diferite se spune ca fisierul este cu înregistrari de lungime variabila.
Fisierele cu înregistrari de lungime fixa sunt fisiere în care fiecare înregistrare contine aceleasi câmpuri în aceeasi ordine, fiecare câmp fiind identificat dupa pozitia sa fata de primul byte al înregistrarii (fig. 2.3). Desigur ca se pot reprezenta înregistrari de lungime variabila sub forma de înregistrari de lungime fixa daca în câmpurile optionale se va stoca valoarea speciala null, iar la câmpurile cu date de lungime variabila baitii neocupati vor avea valoarea speciala null.
|
Nume |
Ini |
Pren |
Ssn |
Dat_n |
Sex |
Sssn |
Dep_nr |
12 14 30 39 48 52 61 66
Fig. 2.3. Înregistrare de lungime fixa
În fisierele cu înregistrari de lungime variabila fiecare înregistrare are valori pentru fiecare câmp, întrucât tot nu se cunoaste lungimea exacta a câmpurilor. Pentru a se determina pozitia si marimea fiecarui câmp se utilizeaza caracterele speciale de separatie între câmpuri (cum sunt !,%,$ @).
Fisierele cu înregistrari având lungime variabila pot fi formate în diverse moduri. Un mod de formare a unor astfel de înregistrari, este de a se pastra grupul câmpurilor cu aceeasi lungime fara separatori între câmpuri si grupul câmpurilor ce contin date de lungime variabila, fiind separate prin caractere speciale (fig. 2.4.a). Un alt mod este cel care încearca sa rezolve problemele câmpurilor optionale al caror nume variaza de la înregistrare la înregistrare, nume ce este specificat urmat de valoarea asociata acestui câmp în înregistrarea respectiva, asa cum se vede în figura 2.4.b.
Nume SSN Salariu Dat_n Dep_nume a)
I Popescu Ion %I xxxxxxxxx I xxxx Ixx/xx/xx I Cercetare I%I
I NUME=Popescu Ion I%I SSN=123456789 I%I Depart=Cercetare I@I b)
in care s-au folosit simbolurile I%I separator câmpuri
I@I separator înregistrari
Fig. 2.4 Înregistrari de lungime variabila
Fisierele ce contin mai multe tipuri de înregistrari necesita programe de aplicatie mult mai sofisticate. Pentru a facilita prelucrarea fisierelor de date cu mai multe tipuri de înregistrari o buna tehnica este cea de marcare la fiecare înregistrare a tipului sau.
Orice fisier este identificabil prin informatiile continute în eticheta de fisier. Se cunosc doua moduri de organizare a informatiilor în fisier:
organizare definita (fisier logic)
organizare nedefinita (fisier fizic).
Fisierul este tratat de sistemul de gestiune a fisierelor ca o colectie de înregistrari fizice organizate conform unei strategii cunoscute numai utilizatorului. Accesul la un fisier cu organizare nedefinita are ca obiect obtinerea unor înregistrari fizice.
Modul de organizare a datelor reprezinta de fapt modul de dispunere a înregistrarilor pe suportul fizic si presupune reguli de memorare a datelor.
Alegerea metodei de organizare va determina performantele relative ale sistemului. Deci, este necesara evaluarea metodei de organizare corespunzator unor criterii de baza:
stocarea unor cantitati mari de date;
accesul usor la date;
economia de spatiu la stocarea informatiilor;
fiabilitatea si protectia datelor;
capacitatea de reprezentare a structurilor lumii reale.
Se cunosc urmatoarele moduri de organizare
a) Standard, este cel mai vechi mod de organizare si exista pe toate tipurile de calculatoare, înregistrarea este formata dintr-un sir de caractere dispus pe o linie acceptata de periferic si toate limbajele recunosc fisiere standard de intrare si iesire.
b) Clasica (elementara) - organizarea se face pe medii magnetice sau optice.
Tipuri de organizare
![]() SECVENŢIALĂ
SECVENŢIALĂ
1. Înregistrarile sunt dispuse în fisier una dupa alta fara nici o ordine prestabilita.
2. Localizarea unei înregistrari se face prin parcurgerea tuturor înregistrarilor anterioare ei (secvential).
Fisierul secvential (sequential file) este caracterizat de faptul ca înregistrarile de date sunt organizate într-o secventa specifica, iar aceleasi atribute sunt continute la toate înregistrarile în aceiasi ordine. Numele atributelor apar doar în descrierea fisierului. Valorile lor au asociate aceleasi nume, si ar corespunde unor coloane la o organizare tabelara. Înregistrarile în fisier pot fi ordonate dupa atributele cheie. Un atribut determina sortarea primara a fisierului, obtinând un grup de înregistrari ce vor fi sortate dupa un alt atribut, pâna când ordonarea este definitiva. Daca exista un atribut cheie fisierul poate fi ordonat dupa acesta.
Fisierele secventiale prezinta o serie de avantaje privind accesul eficient la înregistrari datorita înregistrarilor deja ordonate, accesul facil la înregistrarea urmatoare, posibilitatea de aplicare a metodelor de cautare binara.
![]() RELATIVĂ
RELATIVĂ
v Înregistrarile sunt dispuse în fisier una dupa alta si numerotate (de catre sistem) de la 0 sau 1 la câte sunt (numar de realizare)
v Localizarea unei înregistrari se poate face secvential sau direct prin numarul de realizare.
![]() INDEXAT-SECVENŢIALĂ
INDEXAT-SECVENŢIALĂ
Înregistrarile sunt dispuse în fisier în ordine strict crescatoare dupa o cheie (face parte din înregistrare).
Cheia este unul sau mai multe câmpuri care identifica în mod unic o înregistrare.
Fisierului îi este atasat o tabela de indecsi care face legatura între valoarea cheii si adresa fizica a înregistrarii.
Localizarea unei înregistrari se poate face secvential dar si direct prin cheie:
se compara cheia înregistrarii cautate cu indecsii din tabela de index si se localizeaza direct partea fizica a fisierului în care se afla înregistrarea cautata;
în partea fizica localizata se face o cautare secventiala a înregistrarii dorite.
c) Speciala (complexa), se bazeaza pe modurile de organizare clasice si sunt utilizate în baze de date si în sisteme de fisiere.
Tipuri (câteva):
PARTIŢIONAREA
Înregistrarile din fisier sunt grupate în partitii sub un nume.
În cadrul unei partitii înregistrarile sunt organizate secvential.
Se utilizeaza în biblioteci de programe
MULTIINDEXAREA
Este o extindere a indexarii prin utilizarea mai multor chei alese de programator.
Spatiul ocupat este mai mare
Se utilizeaza pentru fisiere care necesita regasiri intense multicriteriale.
INVERSĂ
Presupune existenta a doua fisiere: de baza si invers.
Fisierul de baza contine datele propriu-zise si are organizare secventiala. El este fisierul în care se cauta.
Fisierul invers este construit din cel de baza (printr-o tehnica de inversare) si are organizare relativa. El este fisierul prin intermediul caruia se cauta.
Spatiul ocupat necesar este cam de 3,5 ori mai mare fata de cât ocupa fisierul de baza.
Modul de acces este modul în care se determina locul ocupat de o înregistrare într-un fisier si depinde de modul de organizare.
Tipuri de moduri de acces:
![]() SECVENŢIAL =
localizarea unei înregistrari se face prin parcurgerea tuturor
înregistrarilor care o preced.
SECVENŢIAL =
localizarea unei înregistrari se face prin parcurgerea tuturor
înregistrarilor care o preced.
Este permis accesul secvential pentru toate tipurile de fisiere.
Se recomanda pentru fisierele din care sunt necesare, la o prelucrare, peste 50% din numarul total de înregistrari.
Pentru optimizare se recomanda ordonarea fisierului.
![]() DIRECT = localizarea
unei înregistrari se face cu ajutorul unei chei definite de programator.
DIRECT = localizarea
unei înregistrari se face cu ajutorul unei chei definite de programator.
Nota. Accesul direct se poate face dupa numarul de realizare sau dupa o valoare a cheii.
![]() DINAMIC = la o
singura deschidere de fisier se pot localiza, alternativ si
repetat, înregistrari în acces secvential si direct.
DINAMIC = la o
singura deschidere de fisier se pot localiza, alternativ si
repetat, înregistrari în acces secvential si direct.
O alta organizare primara ce asigura un acces rapid la înregistrari dupa criterii specificate este cea utilizând tehnica hash. În anumite situatii se foloseste termenul de acces direct, indicând accesul relativ prin pozitia înregistrarii. Criteriul de cautare este dat de egalitatea conditiei la un singur câmp numit si câmp hash, care este un câmp cheie, numit si cheie hash. Înregistrarile sunt organizate în grupuri ce ocupa unul sau mai multe blocuri. Functia hash aplicata câmpului cheie produce un întreg ce indica adresa blocului în care înregistrarea dorita este stocata, daca aceasta exista. Blocul respectiv este transferat în buffer, cautarea înregistrarii în cadrul blocului transferat în memorie fiind realizata prin metode de cautare liniara.
Trebuie facuta distinctia neta între organizarea fisierului si metoda de acces. Prin organizare fisier (file organization) se întelege organizarea datelor în înregistrari, blocuri si structuri de acces. Prin metoda de acces (acces metod) se întelege grupul de programe ce permite aplicarea operatiilor de mai sus asupra fisierului. În general metodele de acces sunt dependente de organizarea fisierului.
Inserarea într-un fisier este o sarcina mult mai complexa decât citirea datelor din fisierul respectiv. Adaugarea unor noi înregistrari este foarte facila daca aceasta presupune plasarea înregistrarii la sfârsitul fisierului. Daca însa inserarea se face într-o anumita pozitie este necesara localizarea acestei pozitii conform criteriului de ordonare, urmata de deplasarea înregistrarilor pentru a face loc înregistrarii inserate. Operatia presupune citirea mai multor blocuri, urmata de rescrierea lor. În anumite situatii eficienta inserarii poate fi crescuta prin utilizarea blocurilor overflow. Reorganizarea fisierului dupa modificarea unor înregistrari sau ca urmare a inserarii de noi înregistrari este în general o operatie ce se efectueaza off-line. Este mare consumatoare de timp necesitând de multe ori citirea întregului fisier, reorganizarea si scrierea acestuia.
În multe aplicatii este necesara citirea întregului fisier. Este de preferat organizarea sub forma de fisier dens, care fata de fisierele risipite si cele redondante, are avantajul volumului mai mic, implicând astfel si un timp de acces mai mic. Aplicatiile tipice necesitând citirea întregului fisier sunt cele prin care se efectueaza operatii de selectie date dupa anumite criterii sau operatii statistice.
2.1.3. Operatii cu fisiere de date
Operatiile specifice asociate fisierelor de date sunt în general grupate în cele doua categorii "retrieve" si "update". Accesul la una sau mai multe înregistrari se face pe baza unui criteriu de selectie ce specifica care conditii trebuiesc satisfacute de acestea. Daca vom considera fisierul entitatii tip ANGAJAT ce contine câmpurile definite mai sus, un criteriu de selectie poate invoca egalitatea valorii unui câmp cu o valoare constanta, operatii de ordine (>, <), precum si combinatii logice ale acestora. Daca mai multe înregistrari satisfac criteriul prima înregistrare din sirul acestora este localizata, trecerea la alte înregistrari ce satisfac acest criteriu se face invocând operatii aditionale. Ultima înregistrare localizata poarta numele de înregistrare curenta. O operatie de localizare ulterioara începe de la înregistrarea curenta, modul de implementare a operatiei de localizare difera de la un sistem la altul.
Cum asupra fisierelor de date sunt necesare o serie de operatii, se dau mai jos câteva dintre cele mai importante.
Find (Locate) operatie de cautare a primei înregistrari ce satisface criteriul de acces. Pentru aceasta se detecteaza mai întâi blocul în care aceasta se gaseste, dupa care înregistrarea respectiva devine înregistrare curenta. Operatia necesita transferul de blocuri în memoria interna.
Read (Get) operatia de copiere din buffer într-o variabila program sau zona de lucru pentru utilizator a unei înregistrari. Ca urmare a acestei comenzi se poate avansa la înregistrarea urmatoare. Este posibil ca read sa invoce mai întâi o operatie de tip find.
Find next operatie de cautare a urmatoarei înregistrari ce satisface criteriul de selectie. Operatia presupune citirea unui nou bloc daca înregistrarea nu exista în blocul curent. Noua înregistrare devine înregistrare curenta.
Delete stergere a înregistrarii curente sau a grupului de înregistrari ce satisfac criteriul de selectie, si eventual rearanjarea fisierului pe disc pentru a reflecta aceasta modificare. Se remarca faptul ca în multe situatii operatia 'delete' nu face stergerea efectiva, ci doar marcarea acelor înregistrari pentru a fi sterse.
Modify modifica valorile câmpurilor în înregistrarea curenta sau în înregistrarile ce satisfac criteriul de selectie, si eventual se reflecta aceasta în fisierul stocat pe disc.
Insert este operatia de adaugare a noi înregistrari în fisierul de date, localizând blocul unde înregistrarile vor fi inserate, transfera blocul în bufferul intern (daca nu este aici), înscrie înregistrarea în buffer, scrie bufferul pe disc pentru a reflecta aceasta modificare. Operatia poate afecta si alte blocuri ale fisierului de date si ca urmare operatia poate fi mare consumatoare de timp.
Operatiile de mai sus se efectueaza înregistrare cu înregistrare sau în grupuri de înregistrari. O serie de operatii aditionale vizând întregul fisier sunt posibile:
Find all operatie de localizare a tuturor înregistrarilor ce satisfac criteriul de selectie.
Find ordered operatie de prezentare a tuturor înregistrarilor din fisier în ordinea specificata prin criteriul de selectie.
Reorganize este operatia de reorganizare a fisierului ce se executa periodic, operatie ce priveste eliminarea înregistrarilor marcate la stergere, renumerotarea înregistrarilor dupa o operatie de sortare.
Doua operatii foarte importante privind pregatirea accesului la fisier sunt operatiile Open pentru deschiderea fisierului, respectiv Close pentru închiderea fisierului.
2.2. Baze de date
2.2.1. Definire, caracteristici
În prezent, agentii economici manipuleaza un volum foarte mare de informatii. Suportul principal prin care se transmit, se prelucreaza si se memoreaza informatiile îl reprezinta datele. Informatia se obtine din date prin diverse asocieri, prelucrari si interpretari ale acestora. În vederea prelucrarii rapide si eficiente a datelor, acestea trebuie organizate si structurate în colectii de date.
O baza de date este o colectie centralizata de date organizata în scopul optimizarii prelucrarii acestora în contextul unui set dat de aplicatii.
Definirea notiunii de baza de date trebuie sa tina cont de urmatoarele elemente:
gruparea datelor în fisiere de date;
descrierea legaturilor (asocierilor) între fisiere (fisier de descriere globala a datelor);
suportul fizic (hardware) pentru conservarea si prelucrarea interactiva a datelor;
sistemul de programe pentru descrierea structurii datelor astfel încât sa fie posibila actualizarea si securizarea acestora (Sistemul de Gestiune a Bazelor de Date = SGBD);
Utilizatorii bazei de date.
Notiuni (elemente) comparative între organizarea datelor în fisiere si baze de date:
![]()
![]()
![]()
![]()
![]() sistem de
fisiere fisiere înregistrari câmpuri valori
sistem de
fisiere fisiere înregistrari câmpuri valori
lumea reala
![]()
![]()
![]()
![]()
![]() baza de date colectii de date familie de caracteristici domenii
baza de date colectii de date familie de caracteristici domenii
(entitati) caracteristici de valori
Domeniul de valori= multimea valorilor posibile pentru o caracteristica (ex.: culorile posibile pentru un automobil).
Caracteristica= definirea si descrierea unui anumit aspect(proprietati) dintr-o entitate a lumii reale (ex.:marca auto)
Familia de caracteristici=ansamblul caracteristicilor care se refera la aceeasi entitate din lumea reala (ex.: multimea caracteristicilor prin care se poate descrie un automobil ).
Colectia de date(entitatea)=o familie de caracteristici asupra careia se aplica un predicat (care conduce la o relatie de ordine între caracteristici si la obtinerea informatiilor cu un anumit sens) caruia i se afecteaza anumite legaturi.
Conceptul de "baza de date" a aparut în 1969 cu ocazia prezentarii raportului CODASYL în cadrul unei conferinte legate de folosirea limbajelor de gestiune a datelor.
Baza de date poate fi definita ca un ansamblu de date stocate în unul sau mai multe fisiere de date, aflate în interdependenta, împreuna cu descrierea datelor si a relatiilor între ele.
Ideea principala este legata de necesitatea accesului oricarui utilizator la date, ceea ce impune realizarea independentei programelor (aplicatiilor) fata de date si a datelor fata de programe.
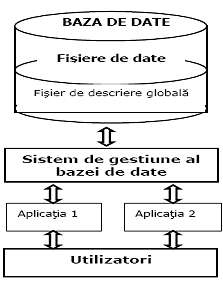
2.5. Reprezentarea bazei de date
Baza de date, astfel definita, trebuie sa îndeplineasca urmatoarele conditii:
. structura bazei de date trebuie sa fie astfel conceputa încât sa asigure informatiile necesare si suficiente de acces;
. sa asigure o redundanta minima si controlata a datelor;
. sa asigure accesul rapid la datele stocate;
. sa asigure independenta datelor fata de programele de prelucrare si invers.
Orice baza de date are urmatoarele proprietati implicite:
o baza de date este o colectie logica coerenta de date ce are cel putin un înteles.
baza de date este destinata, construita, si populata cu date despre un domeniu bine precizat. Ea are un grup inerent de utilizatori si se adreseaza unui anumit grup de aplicatii.
o baza de date reprezinta câteva aspecte ale lumii reale creând orizontul propriu. Schimbarile orizontului sunt reflectate în baza de date.
Fata de modelul file-based, noutatea o constituie existenta unui fisier de descriere globala a bazei, astfel încât sa se poata asigura independenta programelor fata de date, dupa cum o arata si figura 2.6.
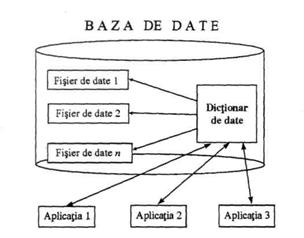
Fig.2.6. Schema de principiu a unei baze de date
Avantajele organizarii informatiilor în baze de date decurg tocmai din existenta acestui fisier de descriere globala a bazei, denumit, în general, dictionar de date (cunoscut si ca repertoar de date sau catalog de sistem). Extragerea si modificarea datelor, altfel spus, lucrul cu fisierele de date, se deruleaza exclusiv prin intermediul dictionarului în care se gasesc informatii privitoare la structura datelor si restrictiile îndeplinite de acestea. Iata câteva dintre avantaje acestui mod de lucru:
un grad redus de redundanta si inconsistenta a datelor;
facilitarea partajarii informatiilor între toti utilizatorii acestora din cadrul organizatiei;
suport pentru standardizarea si securitatea informatiilor;
structurile de date sunt mai aproape de realitate si mai usor de manipulat;
întreprinderea poate fi abordata global, luându-se în considerare si interactiunile dintre compartimente (productie, marketing, personal, finante, contabilitate);
datele fiind separate de programele de consultare si actualizare a lor, procesul de dezvoltare a aplicatiilor-program este sensibil ameliorat, efortul de scriere a programelor (codarea) diminuându-se considerabil;
sistemele informatice ce utilizeaza baze de date sunt mai flexibile, reflecta mai bine specificul firmei, fiind adaptabile la modificarile ulterioare ale mediului economic.
O baza de date (BD) reprezinta un ansamblu structurat de fisiere, care grupeaza datele prelucrate în aplicatiile informatice ale unei persoane, grup de persoane, întreprinderi, institutii etc. Formal, BD poate fi definita ca o colectie de date aflate în interdependenta, împreuna cu descrierea datelor si a relatiilor dintre ele sau o BD reprezinta o colectie de date utilizata într-o organizatie, colectie care este automatizata, partajata, definita riguros (formalizata) si controlata la nivel central.
Bazele de date evolueaza în timp, în functie de volumul si complexitatea proceselor, fenomenelor si operatiunilor pe care le reflecta. Ansamblul informatiilor stocate în baza la un moment dat constituie continutul sau instantierea sau realizarea acesteia.
Organizarea bazei de date se reflecta în schema sau structura sa, ce reprezinta un ansamblu de instrumente pentru descrierea datelor, a relatiilor dintre acestea, a semanticii lor si a restrictiilor la care sunt supuse. în timp ce volumul prezinta o evolutie spectaculoasa în timp, schema unei baze ramâne relativ constanta pe tot parcursul utilizarii acesteia.
O baza de date poate fi de diverse marimi si complexitati. De exemplu, lista numelor, adreselor si numerelor de telefon pastrate de o persoana particulara poate avea sute de înregistrari fiecare cu o structura simpla. Pe de alta parte catalogul cartilor într-o mare biblioteca poate contine pâna la o jumatate de milion de înregistrari stocate în diverse moduri; ordonate dupa numele primului autor, dupa subiect sau dupa titlul cartii.
Definirea bazei de date presupune specificarea tipurilor de date ce vor fi stocate în baza de date, precum si descrierea detaliata a fiecarui tip de data. Prin manipulare se înteleg o serie de functii ce faciliteaza implementarea cererilor pentru gasirea datelor specificate, adaugarea de noi date ce reflecta modificarea contextului, generarea de rapoarte pe baza continutului bazei de date.
O caracteristica importanta a bazelor de date este aceea ca pot contine pe lânga datele propriu-zise si definitii sau descrieri. Definitiile sunt stocate în catalogul sistemului (system catalog) si contine informatii despre structura fiecarui fisier sau tabele, tipul si formatul de stocare a fiecarei date, diverse restrictii referitoare la date. Informatiile stocate în catalog se mai numesc si meta-data, si descriu structura bazei de date primare.
În prelucrarea datelor traditionala structura datelor se reflecta în procedurile asociate programelor de acces, asa ca schimbarea structurii fisierelor de date va determina schimbarea procedurilor de acces. În opozitie, programele DBMS de acces sunt oarecum independente de tipul datelor (se va vedea mai târziu în ce sens), asigurând astfel independenta programelor de date. Daca se modifica atributele unor înregistrari aceasta se reflecta în catalog, nu în programe. Aceasta independenta este totala atunci când tipul de data nu se modifica, dar se modifica formatul. În orice caz si în alte cazuri implicatiile sunt minore.
O baza de date poate avea mai multe utilizari, fiecare utilizator poate privi datele din mai multe unghiuri. Un subset al bazei de date poate fi format din date derivate ce nu sunt explicit stocate în fisiere.
În orice organizatie unde mai multe persoane utilizeaza aceleasi resurse este necesar un manager care administreaza aceste resurse. În mediul bazelor de date resursa primara este formata din datele însasi, resursa secundara este DBMS si programele aferente. Administrarea resurselor este sarcina database administrator (DBA), care este responsabilul autorizarii accesului la baza de date, a coordonarii si monitorizarii utilizatorilor sai.
Constructorii bazei de date (database designers) se ocupa de identificarea datelor ce se stocheaza în baza de date, de alegerea structurii de reprezentare si stocare a datelor. Aceste activitati se desfasoara înainte ca baza de date sa fie implementata. Constructorii bazei de date stabilesc cu potentialii utilizatori modul de acces la date si cererile de prelucrare ale fiecarui grup de utilizatori. În final proiectantii bazei de date sunt capabili sa rezolve cererile tuturor grupurilor interesate în utilizarea bazei de date. Persoanele care cer accesul la baza de date pentru modificare, generare de rapoarte, din baza de date primara apartin mai multor categorii, categorii ce pot fi grupate în:
casual users; utilizatori ocazionali ce pot cere informatii diferite la fiecare acces. Ei formuleaza cereri sofisticate si sunt în general programatori de nivel înalt.
naive or parametric users; acei utilizatori ce formuleaza cererile utilizând formularile standard ce au fost programate si testate. Un exemplu ar putea fi balantele de venituri si cheltuieli, stocuri în depozite. O categorie distincta este cea a cererilor de rezervare a biletelor de avion, spectacole, hotel.
sophisticated users; includ personalul specializat care cu ajutorul DBMS rezolva cereri complexe.
2.2.2. Niveluri de abstractizare a datelor
Una din caracteristicile fundamentale a bazelor de date este data de faptul ca produce câteva niveluri de abstractizare a datelor, prin ascunderea detaliilor legate de stocarea datelor, detalii ce nu sunt utile pentru operatorii cu baza de date. Se defineste modelul datelor ca un set de concepte ce poate fi utilizat in descrierea structurii datelor. Prin structura bazei de date se întelege tipul datelor, legatura dintre ele, restrictiile ce trebuiesc îndeplinite de date. Cele mai multe baze de date includ un set de operatii ce specifica modul de acces la date.
Informatia, care se reprezinta în calculator în memoria interna sau externa, se poate defini structural dupa schema:
are ca are ca are ca
![]()
![]()
![]() INFORMAŢIA ENTITATEA ATRIBUTUL VALOAREA
INFORMAŢIA ENTITATEA ATRIBUTUL VALOAREA
obiect proprietate (CARACTERISTICA) masura
Modelul de structura = descrierea tuturor atributelor unei entitati în interdependenta. Valorile atributelor se materializeaza prin date, care dau o reprezentare simbolica a informatiilor.
Modelul de date = ansamblul de conceptie si instrumente pentru a realiza schema conceptuala a datelor.
Schema conceptuala = descrierea fenomenelor din realitatea înconjuratoare prin entitati si atribute, împreuna cu toate corelatiile (legaturile) dintre ele.
Definirea schemei este o activitate de modelare pentru ca traduce în termeni abstracti entitatile lumii reale.
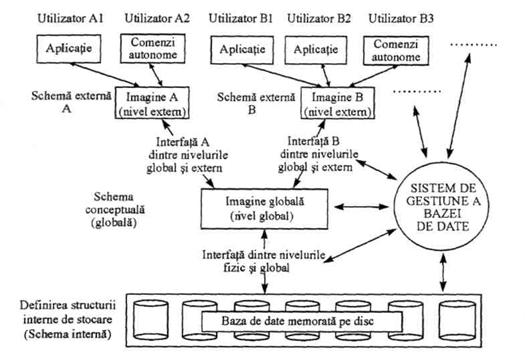
Într-un sistem informatic ce utilizeaza BD, organizarea datelor poate fi analizata din mai multe puncte de vedere si pe diferite paliere. De obicei, abordarea se face pe trei niveluri: fizic sau intern, conceptual sau global si extern (fig.2.7.).
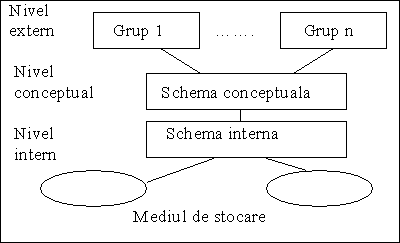
Fig. 2.7. Modele de date
Nivelul fizic (sau intern).
Structura datelor este descrisa foarte detaliat, fiind accesibila numai specialistilor (ingineri de sistem, programatori în limbaje de asamblare sau alte limbaje apropiate de "masina"). Cele doua parti principale ale bazei la acest nivel sunt:
1) un set de programe care interactioneaza cu sistemul de operare pentru îmbunatatirea managementului bazei de date
2) fisierele stocate în memoria externa a calculatorului.
Fisierele ce contin datele propriu-zise sunt alcatuite din articole sau înregistrari cu format comun. La acest nivel, structura BD se concretizeaza în schema interna.
Nivelul conceptual (sau global)
Este nivelul imediat superior celui fizic, datele fiind privite prin prisma semanticii lor; intereseaza continutul lor efectiv, ca si relatiile care le leaga de alte date. Reprezinta primul nivel de abstractizare a lumii reale observate. Obiectivul acestui nivel îl constituie modelarea realitatii considerate, asigurându-se independenta bazei fata de orice restrictie tehnologica sau echipament anume. întreaga baza este descrisa prin intermediul unui numar restrâns de structuri. Toti utilizatorii îsi exprima nevoile de date la nivel conceptual, prezentându-le administratorului bazei de date, acesta fiind cel care are o viziune globala necesara satisfacerii tuturor cerintelor informationale. La acest nivel, structura BD se concretizeaza în schema conceptuala.
Nivelul extern
Este ultimul nivel de abstractizare la care poate fi descrisa o baza de date. Structurile de la nivelul conceptual sunt relativ simple, însa volumul lor poate fi deconcertant. Iar daca la nivel conceptual baza de date este abordata în ansamblul ei, în practica un utilizator sau un grup de utilizatori lucreaza numai cu o portiune specifica a bazei, în functie de departamentul în care îsi desfasoara activitatea si de atributiile sale (lor). Simplificarea interactiunii utilizatori-baza, precum si cresterea securitatii bazei sunt deziderate ale unui nivel superior de abstractizare, care este nivelul extern. Astfel, structura BD se prezinta sub diferite machete, referite uneori si ca sub-scheme, scheme externe sau imagini, în functie de nevoile fiecarui utilizator sau grup de utilizatori.
Luând în considerare cele trei niveluri de abstractizare, schematizarea unui sistem de lucru cu o baza de date se poate face ca în figura 2.8[1].
Este importanta aceasta organizare pe trei niveluri pentru ca explica conceptul de independenta a datelor, prin posibilitatea de modificare a sistemului bazei de date la orice nivel fara a avea influenta la nivelele superioare. Independenta datelor se poate defini în doua moduri, ce sunt aferente nivelelor conceptual si intern.
Prin independenta logica se întelege capacitatea schimbarii schemei conceptuale fara a atrage dupa sine schimbari in schema externa sau în programele de aplicatii. Este posibila schimbarea schemei conceptuale prin expandarea bazei de date ca urmare a adaugarii de noi tipuri de înregistrari sau a datelor însasi, sau prin reducerea bazei de date ca urmare a reducerii înregistrarilor. Schema conceptuala dupa aceste operatii se refera la schema conceptuala a datelor existente.
|
|
Fig.2.8. Schematizarea unui sistem de lucru cu o baza de date
Independenta fizica este reprezentata prin capacitatea de schimbare a schemei interne fara schimbarea schemei conceptuale sau externe. Schimbarea schemei conceptuale poate surveni ca urmare a reorganizarii fizice a unor fisiere, prin crearea de noi structuri de acces menite sa asigure accesul eficient la date.
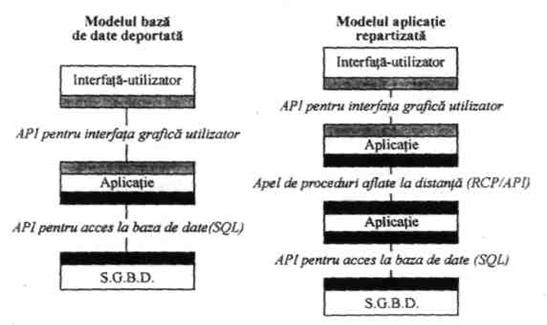
Accesul utilizatorului la informatiile din baza este posibil numai prin intermediul sistemului de gestiune a bazei de date (SGBD). În general, interfata utilizator-SGBD se poate realiza în doua moduri: printr-un mecanism de apel (cuvânt-cheie, ca de exemplu CALL) inserat în programele scrise într-un limbaj "traditional" (C, COBOL etc), acesta fiind cazul SGBD-urilor cu limbaj gazda sau prin comenzi speciale utilizate autonom (în afara aplicatiilor-program), în cazul SGBD-urilor autonome.
Modele de structurare a datelor în BD
2.2.3.1. Legaturi între date
Se defineste modelul datelor ca un mod de abstractizare a datelor ce este utilizat pentru reprezentarea conceptuala. Modelul datelor utilizeaza concepte logice despre obiecte, proprietatile lor, relatiile dintre ele. Deci, modelul datelor ascunde detaliile ce nu sunt interesante pentru cei mai multi utilizatori ai bazei de date. Detaliile de reprezentare sunt neesentiale daca referirea la date se poate face direct prin numele acestora.
Când mai multi utilizatori doresc accesul la o baza de date numai unii pot avea acces la toate datele. DBMS va trebui sa asigure accesul autorizat la date. De exemplu, datele financiare sunt considerate confidentiale, si deci, numai persoanele autorizate pot avea acces la ele. In plus un grup de persoane au acces numai la citirea acestor date, pe când alt grup este autorizat sa modifice datele. Accesul este protejat printr-o parola de acces.
Elementele (componentele) oricarui model de date sunt:
definirea structurii modelului (partea structurala):
definirea entitatilor si a atributelor asociate;
definirea legaturilor (asocierea) dintre entitati.
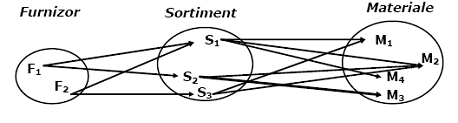
Elementele (numite si realizari) unei colectii de date intra în anumite legaturi (asocieri). Ele pot fi legaturi în cadrul aceleiasi colectii (legaturi interne) sau legaturi între colectii diferite (legaturi externe). De exemplu pentru colectiile de date Produse si Materiale legaturile interne rezulta prin aceea ca mai multe materiale apartin aceluiasi sortiment iar cele externe prin faptul ca mai multe materiale participa la realizarea unui produs, asa cum unul sau mai multe produse se pot obtine pe seama unui singur material.
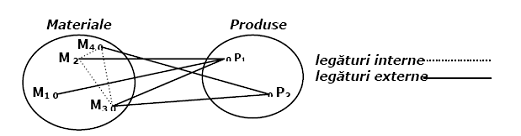
Fig.2.9. Tipuri de legaturi
Legaturile între realizarile diferitelor colectii de date pot fi binare si n-are.
Legaturile binare sunt determinate de existenta a doua colectii de date numite domeniu si codomeniu (legaturile interne sunt relatii binare la care domeniul si codomeniul sunt identice). Se disting urmatoarele tipuri de legaturi:
. legaturi "unu la unu" (1 - 1 sau biunivoce). Unui element din domeniu îi corespunde un singur element din codomeniu si invers. Exemplu: relatia dintre colectiile de date Studenti si Matricole. O matricola este atribuita unui singur student, iar un student poate beneficia de o singura matricola.

2.10. Legaturi binare
. legaturi "unu la multi" (1- n). Unui element din domeniu îi corespund zero una sau mai multe realizari din codomeniu. De exemplu un student face parte dintr-o singura grupa, o grupa poate avea mai multi studenti.
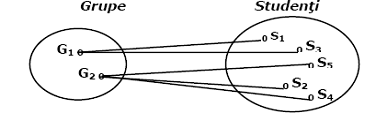
2.11. Legaturi unu-la mai multi (1-n)
. legaturi "multi la multi" (m - n). Unui element din domeniu îi corespund mai multe realizari din codomeniu corespondenta realizându-se si invers. De exemplu un produs este realizat din mai multe materiale, acelasi material folosindu-se la fabricarea mai multor produse.
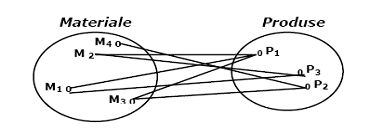
2.12. Legaturi multi-la multi (m-n)
Legaturile n-are sunt legaturile prin care sunt asociate mai multe colectii de date (ele pot fi descompuse în legaturi binare). Aceste tip de legaturi este luat în considerare în algebra relatiilor care constituie baza teoretica pentru tratarea bazelor de date relationale.
2.2.3.2. Tipuri de structuri de date si modelele lor de reprezentare
Principalele tipuri de structuri de date care impun modul de organizare al datelor sunt structura liniara, structura arborescenta, structura retea, si structura relationala. Modelele specifice acestora sunt: modelul de reprezentare liniara, modelul ierarhic, modelul retea, modelul relational,modelul orientat obiect.
2.2.3.2.1. Modelul de reprezentare liniara
Structura liniara este definita printr-o relatie de ordine pe un grup de date sub forma denumita lista.
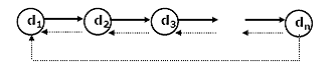
2.13. Structura liniara
Realizarea fizica a modelului este lista, care poate fi asimetrica (când informatia corespunzatoare a fiecarei realizari are asociata adresa urmatoarei realizari sau simetrica (când, la fiecare realizare se asociaza doua adrese: precedenta si urmatoare).
Elementele unei liste sunt înlantuite conform urmatoarelor principii:
a. orice element neterminal al listei are un succesor unic (lista simplu înlantuita);
b. primul element nu are predecesori;
c. ultimul element nu are succesori;
d. daca ultimul element se înlantuie cu primul element lista se numeste lista circulara;
e. daca înlantuirea se defineste si în sens invers (de la fiecare element al listei spre predecesorul sau) lista se numeste lista dublu înlantuita.
Exemplu:
2.14. Structura de tip lista
În scopul optimizarii operatiilor de cautare a informatiilor în lista au fost elaborate structuri de reprezentare liniara specializate: stack (stiva) si queue (coada).
Stiva este o structura asimetrica care permite ca operatiile de adaugare, consultare si stergere sa se poata efectua în capul colectiei de date. Ea este bazata pe principiul LIFO (Last Input First Output), astfel încât ultima realizare adaugata sa fie prima consultata.
Coada este o structura simetrica care permite adaugari la sfârsitul listei si consultari/stergeri la începutul listei. Principiul se numeste FIFO (First Input First Output.
Un fisier de date construit pe baza modelului liniar consta într-o succesiune de înregistrari, de lungime variabila. De exemplu, pentru structura arborescenta prezentata anterior, luând în considerare posibilitatea descompunerii acesteia în structuri liniare, se poate constitui un fisier care contine urmatoarele înregistrari:
(P1,C1) (P1,C2) (P2,M3,Com1) (P2,M3,Com2) (P2,M1,F4) (P2,M1,F3)...
2.2.3.2.2. Modelul ierarhic (arborescent)
Structura arborescenta (ierarhica sau descendenta) este definita printr-o relatie de ordine pe un grup de date astfel:
a. elementele grupului de date se numesc noduri si sunt dispuse pe nivele;
b. exista un singur nod pe primul nivel - nod radacina;
c. orice nod diferit de radacina are un predecesor imediat unic;
d. orice nod neterminal are un numar finit de succesori imediati;
e. legaturile stabilite între noduri sunt de tipul 1 - n (o structura arborescenta definita numai prin legaturi de tip 1 -2 se numeste arbore binar).
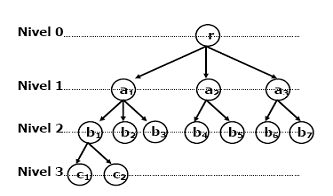
2.15. Structura arborescenta
Caracteristici ale structurii ierarhice (arborescente):
Fiecare nod corespunde unui tip de înregistrare si fiecare drum corespunde unei legaturi (asocieri).
Orice acces la un nod se face prin vârful ierarhiei, numit radacina, pe o singura cale.
Un nod subordonat (copil) nu poate avea decât un singur superior (parinte).
Un superior poate avea unul sau mai multi subordonati.
Legatura copil-parinte este doar de tip 1:1 (la o realizare copil corespunde o singura realizare parinte).
Legatura parinte-copil poate fi de tip 1:1 sau 1:M.
În structura exista un singur nod radacina si unul sau mai multe noduri dependente situate pe unul sau mai multe niveluri.
O ierarhie de tipuri de înregistrari se numeste tip arbore.
O realizare a unui tip arbore este formata dintr-o singura realizare a tipului de înregistrare radacina împreuna cu o multime ordonata formata din una sau mai multe realizari ale fiecarui tip de înregistrare de pe nivelurile inferioare.
Ordonarea realizarilor dintr-un arbore conduce la o secventa ierarhica.

2.16. Modelul arborescent (ierarhic)
Aceasta structura se bazeaza pe existenta unei multimi de colectii de date si o multime de legaturi ierarhice. Fiecarui tip de colectie de date i se atribuie un numar de nivel (exista o singura colectie de date de nivel 1 numita radacina). Colectiile de date pe acelasi nivel formeaza o familie de date.
Exemplu:
Modelul de reprezentare arborescenta se poate realiza fizic cu ajutorul unor adrese care indica adresa primei realizari din cadrul colectiei si adresa urmatoarei realizari din cadrul colectiei (organizare FIU, FRATE).
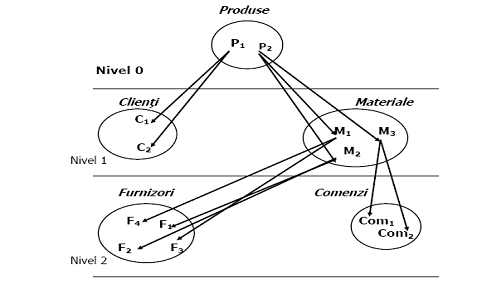
2.17. Exemplu de structura ierarhica
Definirea structurii modelului ierarhic presupune:
Definirea entitatilor se face prin notiune de tip de înregistrare (clasa de entitati), care este formata din caracteristici (câmpuri).
Realizarea (instanta) unui tip de înregistrare este data de ansamblul valorilor pentru câmpurile acesteia (înregistrarea)..
Definirea legaturilor dintre entitati se face fizic si conduce la structura de tip ierarhic (arborescent) reprezentata sub forma unei diagrame (fig. 2.18.).
![]()

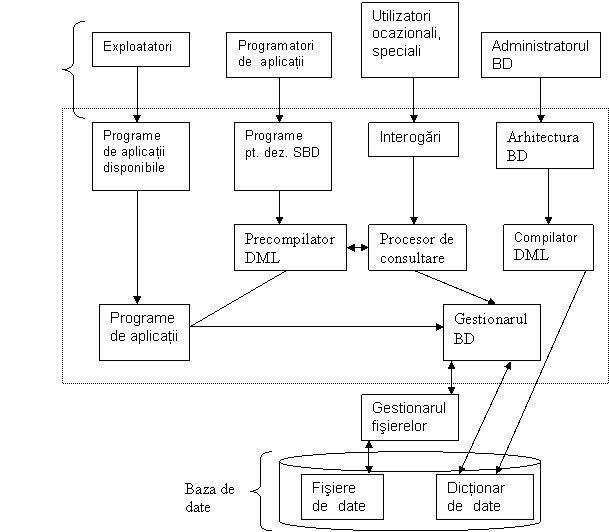
Fig.2.29. Structura generala a unui SBD
SBD face ca utilizatorul sa utilizeze o reprezentare conceptuala a datelor fara sa includa nici un detaliu asupra modului în care acestea sunt stocate. Deci, SBD include si subsistemul programelor de securitate si autorizare putând crea conturi la care se specifica restrictiile. Este remarcabil faptul ca nu toate mediile de baze de date ofera servicii intrinseci pentru securitate. În general aceste functii sunt specifice administratorului bazei de date, dar este necesar sa fie luate în consideratie si în faza de proiectare a aplicatiei.
SBD trebuie sa includa facilitati de refacere a datelor la defectarile hardware si software (backup). Daca sistemul se defecteaza in timpul operatiei de reactualizare date din baza, aceasta trebuie sa ramâna in forma pe care o avea înainte de operatie, prin crearea copiei acestuia. Facilitati suplimentare sunt asigurate pentru DBMS moderne in ceea ce priveste rollback si respectiv rollforward, facilitati care asigura translatarea bazei înainte si înapoi, pentru o serie de operatii de actualizare. O alta caracteristica importanta este cea de asigurare a caracterului tranzactional in interogarea bazei. Trebuie mentionat ca principalele diferente intre mediile comerciale si cele profesionale sunt cladite pe aceste facilitati si bineînteles caracteristicile legate de viteza de prelucrare.
Un SBD tipic ofera facilitati multiple pentru accesul la baza de date. Utilizatorii naivi pot învata foarte repede facilitatile oferite de SBD, deoarece ei utilizeaza in general numai anumite tipuri standard de tranzactii. Utilizatorii ocazionali învata acele facilitati de acces pe care apoi le folosesc de mai multe ori.
Întrucât categorii de utilizatori au cunostinte diferite în utilizarea bazelor de date, SBD faciliteaza aceasta printr-o varietate de interfete utilizator. Aceste tipuri de interfete includ interpretoare de cereri, limbaje de programare pentru programele de aplicatii, interfete sub forma de meniuri pentru utilizatori nespecializati, interfete în limbaje naturale. O baza de date contine o varietate de date ce sunt în diverse tipuri de relatii. SBD trebuie sa ofere capacitatea reprezentarii unei varietati de relatii complexe, precum si accesul la aceste date relationale într-o maniera eficienta. Este esential ca utilizatorul sa identifice si sa prelucreze date în relatii complexe.
Se vor trece in revista mai jos principalele tipuri de interfete oferite de SBD, interfete ce au ca scop sa faciliteze legatura utilizatorilor cu sistemul de baze de date.
Interfetele bazate pe meniuri ofera utilizatorului o lista de optiuni, numite meniuri ce ii ajuta in formularea cererilor. Nu este necesara memorarea unor comenzi deoarece o comanda specifica este formata pas cu pas prin compunerea optiunilor indicate prin meniu.
Interfetele grafice sunt acele interfete ce afiseaza utilizatorului o diagrama. Utilizatorul poate formula cererea prin manipularea acestei diagrame. In cele mai multe cazuri interfetele grafice sunt combinate cu meniuri. Selectia poate fi usurata la interfetele grafice prin utilizarea light pen sau prin mose in sensul ca astfel se poate alege o parte a diagramei.
Interfete bazate pe casete (form based interfece) sunt interfetele prin intermediul carora utilizatorul poate umple acele forme cu noile date pe care doreste sa le insereze, sau foloseste aceste forme pentru a cere DBMS sa obtina datele de interes. Formele sunt destinate utilizatorilor naivi si nu sunt tranzactionale.
Interfetele in limbaj natural (natural language interfece) accepta cereri scrise in limba engleza sau alte limbi de circulatie internationala. O interfata in limbaj natural contine uzual o schema proprie similara cu schema conceptuala a bazelor de date. Interpretarea cererilor se face pe baza unui set standard de cuvinte cheie ce sunt interpretate pe baza schemei interne. Daca interpretarea se realizeaza cu succes programul de interfata genereaza cererea de înalt nivel corespunzatoare celei in limbaj natural, ce va fi transmisa SBD. Altfel, se initiaza un nou dialog cu utilizatorul pentru a se clarifica.
Interfete specializate (interfeces for parametric users) aferente cererilor repetate de acelasi tip. Aceste interfete sunt destinate unei anumite categorii de utilizatori, cum sunt cele referitoare operatiilor dintr-o banca. Uzual un mic set de comenzi prescurtate sunt implementate pentru a scurta timpul necesar introducerii comenzii, sau chiar utilizarea de chei functionale. Aceste interfete implementeaza un limbaj numit si limbaj de comanda.
Interfete pentru DBA utilizate in implementarea comenzilor privilegiate ce sunt folosite numai prin intermediul DBA. Astfel de comenzi includ crearea de conturi, setarea parametrilor sistemului, autorizarea intrarii într-un anumit cont, reorganizarea structurii de stocare a datelor bazei de date, precum si o serie de facilitati legate de administrarea bazei de date cum sunt: accesul la tabele si înregistrari, facilitati de acces la câmpuri ale tabelelor de date.
Datele propriu-zise si catalogul SBD sunt uzual stocate pe disc. Controlul accesului la disc este în sarcina sistemului de operare prin sistemul de gestiune a fisierelor. Un modul de înalt nivel numit Stored Data Manager (SDM), modul component al SBD, controleaza accesul la informatiile stocate pe disc, informatii ce fac parte fie din catalog fie din datele însasi. Modulul SDM va utiliza componente ale sistemului de operare pentru controlul transferului intre disc si memoria interna prin intermediul bufferelor. Numai datele aflate în memoria principala pot fi prelucrate de celelalte module SBD. Compilatorul DDL prelucreaza definitiile schemei, specificate de catre DDL si stocheaza informatiile în catalogul SBD. Catalogul contine detalii despre numele fisierelor, datele însasi, detalii de stocare pentru fiecare fisier, restrictii.
Procesorul bazei de date (run time processor) controleaza accesul la baza de date in timpul rularii. El primeste cereri de reactualizare si adaugare a datelor pe care le implementeaza in baza de date.
Procesorul de cereri (query processor) manipuleaza cererile introduse interactiv de catre utilizator. El analizeaza cererea pe care o transmite sub o forma corespunzatoare procesorului de rulare in timp real.
Precompilatorul extrage din programele de aplicatii comenzile DML scrise in limbaj de nivel înalt. Comenzile sunt trimise compilatorului DML pentru compilare in cod obiect adecvat accesului la baza de date. Codul obiect al comenzilor DML si celelalte programe sunt legate pentru a fi executate de catre sistemul DBMS. Celelalte blocuri cuprinse in figura au fost explicate cu diverse ocazii pâna acum.
Pe lânga modulele descrise pâna acum in bazele de date se utilizeaza o serie de programe ajutatoare ce asigura formarea sistemului de baze de date. Aceste programe utilitare au in general functiile:
Loading utilitar utilizat pentru încarcarea fisierelor de date existente cum sunt fisiere text sau secventiale. Uzual, formatul curent al fisierului sursa si al fisierului de date dorit (destinatia) sunt comunicate utilitarului încarcator. Acesta va reforma automat datele pe care le stocheaza in baza de date.
Backup utilitar care creeaza o copie a datelor asigurând refacerea acestora in cazul unei catastrofe.
File reorganization utilitar ce poate fi utilizat pentru reorganizarea fisierelor bazei de date intr-o forma ce duce la cresterea performantelor.
Report generation utilizat pentru obtinerea rapoartelor referitoare la spatiul ocupat de baza de date, a sumarului calculat pe baza tuturor datelor, etc.
Performance monitoring utilitar ce monitorizeaza utilizarea bazei de date si furnizeaza statistici pentru DBA. Statisticile sunt utilizate de catre DBA pentru a lua decizii in legatura cu necesitatea reorganizarii fisierelor in vederea ameliorarii performantelor.
Sunt posibile si alte utilitare având in general functii de sortare fisiere, compresie de date, monitorizarea utilizatorilor. O facilitate importanta este cea de integrare a DBMS in comunicatii de date formând sistemele DB/DC.
2.3.4. Tipuri de SBD
SBD se pot clasifica dupa mai multe criterii, ce tin cont în general de principalele facilitati oferite.
Un prim criteriu, si poate cel mai important este oferit de modelul datelor pe care se bazeaza SBD. Modelele de date cele mai utilizate în bazele de date actuale sunt cele relationale, retea si ierarhizate. Se pot aminti ca realizari recente SBD bazate pe modele conceptuale sau modele orientate obiect. În conjunctie cu acest criteriu SBD poate fi împartit în relational, în retea, ierarhizat.
Alt criteriu de clasificare este cel al dat de numarul de utilizatori suportati de SBD, la aceeasi tabela de date, criteriu dupa care SBD se clasifica în sistem cu un singur utilizator, în general pentru calculatoare personale si SBD pentru mai multi utilizatori în sistemele multiuser.
Dupa locul în care baza de date este instalata se pot clasifica în baze de date centralizate pe un singur calculator si baze de date distribuite pe mai multe calculatoare conectate în retea, în care gradul de independenta locala a fiecarui SBD este variabil.
Criteriul costului face ca SBD sa se împarta, în general în doua categorii, o categorie pentru care costul este de la 10000 la 100000 $, respectiv de la 100 la 3000 $. În general produsele din a doua categorie sunt utilizate pentru calculatoare personale.
În fine, SBD poate fi cu utilizare generala, fara a implementa caracteristici specifice utilizatorilor particulari, sau cu utilizare particulara pentru un anumit domeniu, cum sunt de exemplu cele de rezervarea biletelor de calatorie, spectacole.
Schema evolutiei arhitecturale a SBD-urilor, este prezentata figura 2.30[5].
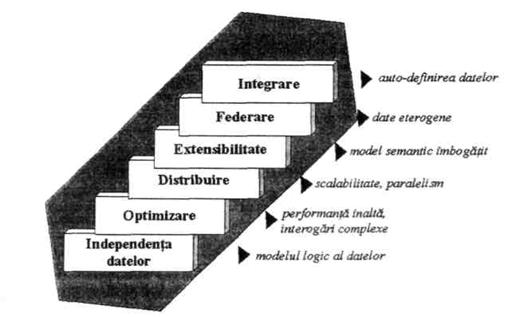
Fig.2.30. Evolutia arhitecturii SGBD-urilor[6]
Primul nivel, cel al independentei datelor, a fost posibil o data cu aparitia modelului relational care a facut posibila independenta logica a datelor fata de reprezentarea lor fizica, pe suportul de stocare. Maturizarea tehnologiilor relationale a însemnat gasirea a noi si rapide metode acces, indexare, scheme de stocare, a unor noi mecanisme de asigurare a securitatii, integritatii datelor si accesului concurent si, nu în ultimul rând, elaborarea unor limbaje neprocedurale dedicate bazelor de date - definind faza de optimizare.
Implementarea unor arhitecturi capabile sa gestioneze datele companiilor dispersate teritorial, uneori în tari si continente diferite, a consacrat sintagma baze de date distribuite.
Extensibilitatea SGBD-urilor marcheaza trecerea de la o arhitectura monolitica, la una flexibila, în care este posibila adaugarea dinamica a unor module speciale, dedicate gestionarii diferitelor tipuri de date - spatiale, video etc. (ex. cartuse de date - Oracle, lame de date -Informix etc). Daca în anii '80 majoritatea arhitecturilor implementate se bazau pe produsele unei singure case de software, începând cu anii '90 practica legarii între ele a modulelor/aplicatiilor/bazelor de date eterogene (diverse platforme si, implicit, diversi producatori) a devenit una curenta, caracterizând faza de federare. A fost atins astfel obiectivul unui acces transparent si o gestionare unitara a unor surse de date dintre cele mai eterogene.
Explozia Internetului si a aplicatiilor dintre cele mai diversificate au pus în fata producatorilor de SGBD-uri si dezvoltatori de aplicatii dezideratul integrarii. Aceasta înseamna nu numai independenta datelor, optimizare, extensibilitate, federare, dar si posibilitatea de a defini noi tipuri de date, în functie de specificul problemei, cât si legarea strânsa a aplicatiilor din categorii dintre cele mai diferite: sisteme pentru gestiunea continutului, depozite de date, sisteme de tip workflow, proiectare asistata de calculator, groupware, în conditiile mobilitatii datelor, accesului din orice punct al planetei la informatiile necesare. Java, XML, extensii ale SQL, comunicatiile mobile si multe altele constituie câtiva dintre catalizatorii integrarii datelor[7].
Toti producatorii de servere de baze de date întreprind eforturi substantiale pe linia unui mariaj al relationalului cu tehnologia obiectuala. Includerea de noi tipuri de date, extensii ale nucleului relational "traditional" al bazelor de date catre obiecte, suportul pentru web si comert electronic sunt doar câteva directii pe care s-au înscris majoritatea SGBDR actuale pentru a-si conserva sau ameliora pozitia de pe piata. Acesta este unul dintre aspectele integrarii.
Dupa Mary Roth si Dan Wolfson[8], o platforma robusta pentru integrarea datelor trebuie sa îndeplineasca urmatoarele cerinte:
integrare transparenta a datelor structurate, semistructurate si nestructurate provenind din multiple surse eterogene;
suport eficace pentru stocarea, schimbul si transformarea documentelor XML;
optiuni pentru cautari si analize ale datelor elementare si integrate;
includerea transparenta a accesului la informatii în cadrul proceselor întreprinderii;
suport pentru standarde si platforme multiple;
usurinta în utilizare si întretinere.
În actuala configuratie a pietei mondiale a software-ului, segmentul SBD-urilor este unul de mare anvergura. Spre exemplu, la nivelul anului 2001 acesta era evaluat la 17,4 miliarde de dolari, iar dupa IDC, în ciuda recesiunii actuale din IT, cifra a ajuns la 20 de miliarde în 2006[9]. Prognoza nu pare exagerata, daca ne gândim ca volumul de date de stocat creste, anual, în ultima perioada, cu procente cuprinse între 75 si 150% .
v SBD-uri de categorie " usoara "
Primele produse de tip SBD vizau sisteme de calcul de mare putere si, fireste, costau enorm. De la mainframe-uri, s-a trecut apoi la minicalculatoare. Dar adevarata "democratizare" a SBD-urilor s-a produs o data cu dezvoltarea exploziva a PC-urilor. Produse precum dBase, RBase, Clipper, FoxPro, Paradox, Access etc. s-au vândut (si copiat ilegal) în milioane de exemplare. Destinate initial utilizatorilor de PC-uri cu un redus bagaj de cunostinte în domeniul bazelor de date, astazi aceste produse sunt dotate cu seturi puternice de instructiuni si functii si prezinta o interfata de lucru deosebit de prietenoasa, atuuri ce confera o mare dinamica acestui segment al pietei, denumit si cel al SBD-urilor micro.
Exploatabile pe platformele de lucru MS-DOS/Windows, reprezinta zona "de jos" care vizeaza deopotriva ne-profesionistii în ale informaticii, dar si dezvoltatorii de aplicatii la scara medie. Totodata, în retelele complexe (de întreprindere), SBD-urile micro pot fi utilizate ca medii de dezvoltare pentru statiile client, prin care se asigura accesul utilizatorilor la BD administrate printr-un SBD "profesional". Lumea SBD-urilor micro a suferit schimbari majore în ultimul deceniu, atât în fizionomie, dar si în modul efectiv de lucru, mai ales pentru cele din clasa XBase. Visual Objects (Computer Associates), Visual FoxPro, Visual dBase seamana putin cu ceea ce a fost altadata un produs XBase, fiind instrumente care înglobeaza tehnologii recente: client/server, replicare, programare orientata pe obiecte, dezvoltarea rapida a aplicatiilor (RAD), web etc.
Este greu de facut o ierarhizare, însa piata a consacrat la aceasta categorie produsul Access al firmei Microsoft., inclus în suita Office: este ieftin, intuitiv si bine integrat cu ceilalti "pilieri", Excel si Word. Astfel încât aria sa de utilizare este superioara oricarui alt produs competitor.
v SBD-uri de categorie " medie "
Urcând la categoria superioara SBD-urilor micro, se cuvinte amintit ca piata a cochetat pe la mijlocul anilor '90 cu sintagma servere de date pentru grupuri de lucru[11]. Acest concept a fost pus în practica de firma Microsoft, prin comercializarea Ia un pret foarte avantajos a produsului SQL Server, un SBD ce permitea initial accesul simultan la baza de date a unui numar de 20-30 utilizatori. Fara a se ridica la pretentiile unui SBD Unix, SBDRurile pentru grupurile de lucru au fost declarate instrumentul ideal pentru firmele mici si mijlocii, acolo unde Paradox, FoxPro, Access îsi aratau limitele în materie de volum de date ce poate fi gestionat, securitate, pastrarea coerentei în caz de avarie etc. Prin lansarea unor produse sub eticheta Workgroup Databases, marii producatori de SBD-uri au creat o anumita confuzie în rândul utilizatorilor si chiar al distribuitorilor.
În ultimul timp, SBD-urile pentru grupuri de lucru au fost asimilate celor de "categoria grea", desi înca multi autori si profesionisti vad un segment de mijloc între SBD-urile pentru microcalculatoare si cele de categorie grea.
v SBD-uri de categorie "grea " - servere de baze de date
În aceasta categorie sunt încadrati "pilierii" bazelor de date: Oracle (Oracle), DB2 (IBM), Sybase (Sybase), Informix (IBM), SQL Server (Microsoft) etc, produse orientate pe gestiunea informatizata a organizatiilor mari si foarte mari, asigurându-se accesul simultan a sute, chiar mii de utilizatori la o aceeasi baza de date. Daca, traditional, piata acestui segment era rezervata Unix-ului, în prezent Windows NT (2000) si mai nou Linux fac fata celor mai multe cerinte.
Cât priveste cota de piata detinuta de fiecare producator, anul 2005 a fost destul de agitat. De o buna bucata de vreme, Oracle era considerat liderul indiscutabil al pietii SBD, însa prin achizitionarea firmei Informix (si a cotei de piata a acesteia), firma IBM a atins procentul 34,6%, devansând Oracle care ar avea doar 32%. Pe locul trei ar urma Microsoft cu 16,3% din piata SBD-urilor. Dupa cum remarca si Craig Mullins, în urma acestui raport, fiecare producator si-a autodeclarat suprematia, Oracle pe piata "SGBD-urilor modeme"'[12], iar Microsoft pe platformele Windows . Toate afirmatiile par a fi, macar partial, adevarate, câta vreme studiul Garner nu se refera numai la serverele de baza de date relationale, ci si la cele de pe mainframe-uri (ierarhice, cum ar fi IMS si retea), precum si la cele de tip "micro" (ex. Access). Pe un segment strategic al SBD-urilor - Unix - Oracle detine 63%, iar IBM 25%.
Interesant este ca, la scurt timp dupa studiul Gartner, IDC a publicat o alta estimare a pietei SBD, în care Oracle are un avantaj de 10 procente fata de principalul concurent -IBM. Craig Mullins explica aceste diferente prin metodologia pe care o utilizeaza fiecare firma de analiza si prospectare a pietei, prin unele detalii ascunse si erori de analiza.
v Servere de date de tip Free-SBD, adica (aproape) gratuite
PostgreSQL a fost elaborat la University of Carolina, Berkeley, principalii promotori ai sai fiind GreatBridge si Reh Hat. MySQL, produs de MySQL AB (Suedia) si distribuit cu o licenta Gnu (Gnu Public License), este, probabil, cel mai folosit SBD open source, desi functionalitatile sale sunt mai slabe decât ale Postgres-ului. Se remarca printr-o viteza mai buna si o functionalitate mai ridicata decât a concurentilor. Firebired/Interbase este un produs Borland devenit public (open source) în iulie 2000. Dintre alte SBD-uri din aceasta categorie, mai pot fi amintite HSQ si SQLLite[14]. De departe, cele mai folosite si cele care au polarizat, oarecum, comunitatea SBD open-source sunt MySQL si PostgreSQL.
Fara îndoiala, serverele de baze de date din categoria Open Source constituie o directie strategica în evolutia pietei bazelor de date, deoarece ofera o functionalitate rezonabila la preturi foarte mici, lucru cu atât mai dezirabil cu cât ne referim la organizatii care încearca sa-si implementeze arhitecturi informationale în conditiile unei situatii financiare cu puternica tenta gri sau rosu.
2.3.4.1. Sisteme de baze de date relationale
Organizatia americana de norme TRG (Realtional Task Group) a definit termenul de "relationalitate". Acesta propune un ansamblu de criterii care sa defineasca notiunea de SBD minimal relational si total relational. Creatorul modelului relational, E.F. Codd a propus 12 criterii de definire a SBD-urilor din punct de vedere al relationalitatii.
![]() SBD minimal relational
SBD minimal relational
1. Structura tabelului de date
Toate datele unei baze de date sunt reprezentate prin valori în tabele.
2. Pointer-i (puncte de intrare) invizibili
Punctele de intrare ale tabelului de date sunt invizibili pentru utilizator.
3. Operatori de baza:
SBD-ul trebuie sa implementeze operatiile de selectie, proiectie si jonctiune (fara nici o restrictie).
![]() SBD total relational
SBD total relational
Un SBD devine total relational daca la cele trei criterii enuntate anterior se adauga urmatoarele doua:
4. Operatori:
SBD-ul suporta toate operatiile algebrei relationale.
5. Restrictii
SBD permite respecta regula de unicitate a cheii si regula de restrictie referentiala.
Regulile lui Codd
1. Regula privind gestionarea unui SBDR
Toate functiile de manipulare a unui SBD au ca unitate de informatie relatia (tabelul).
2. Regula privind garantarea accesului la date
Fiecare element al unui SBD poate fi accesat într-o maniera unica cu ajutorul numelui relatiei, numelui atributului si a valorii cheii.
3. Regula privind valorile "null"
SBD trebuie sa permita declararea si manipularea sistematica a valorilor de null cu semnificatia unor date lipsa sau inaplicabile.
4. Regula privind metadatele (dictionarul)
Descrierea elementelor unei baze de date trebuie sa se faca, la nivel logic, în aceeasi maniera cu descrierea datelor propriu-zise.
Dictionarul este o baza de date specifica (fisier de descriere globala a datelor) care permite descrierea, la nivel general, a tabelelor de date în scopul manipularii si interogarii acestora.
5. Regula privind limbajele de programare utilizate
Un SBDR trebuie sa faca posibila utilizarea mai multor limbaje de programare. dintre care cel putin unul permite:
definirea tabelelor de date si a tabelelor de date virtuale;
manipularea datelor;
definirea restrictiilor de integritate;
definirea regulilor de acces;
precizarea limitelor tranzactiilor.
6. Regula privind actualizarea datelor
Tabelele de date virtuale (acele tabele construite pe baza tabelelor de date existente) trebuie sa fie efectiv actualizabile.
7. Regula privind manipularea datelor (inserari, modificari, stergeri)
SBD-ul trebuie sa mentina o stare coerenta a datelor din punct de vederea al manipularii lor (regasire, modificare, stergere, inserare).
8. Regula privind independenta fizica a datelor
Programele de aplicatie trebuie sa fie independente de modul si de suporturile de stocare a datelor.
9. Regula privind independenta logica a datelor
Programele de aplicatii trebuie sa fie independente de modificarile semantice ale tabelelor bazei de date.
10. Regula privind restrictiile de integritate a datelor
Limbajul de programare utilizat trebuie sa defineasca restrictiile de integritate ale datelor si trebuie sa fie le memoreze în fisierul de descriere globala (catalogul) a datelor.
11. Regula privind distribuirea geografica a datelor
SBDR trebuie sa permite manipularea datelor indiferent ca bazele de date sunt dispuse în acelasi loc (centralizate) sau dispuse în locuri diferite (distribuite).
12. Regula privind prelucrarea datelor la nivel de baza
Daca SBDR poseda un limbaj de programare de nivel scazut, orientat pe prelucrarea de tupluri (înregistrari) si nu pe prelucrarea la nivel de relatie, acesta nu trebuie utilizat pentru a face exprimari relationale.
2.3.4.2. Sisteme de baze de date distribuite
Tehnologia bazelor de date a evoluat pe parcursul timpului de la o paradigma a procesarii datelor conform careia fiecare aplicatie îsi definea si mentinea propriile date la una conform careia datele sunt definite si administrate centralizat. O data cu dezvoltarea rapida a retelelor si tehnologiei comunicatiilor, a Internetului, aplicatiilor mobile si a dispozitivelor inteligente, asistam la proliferarea bazelor de date distribuite ce combina tehnologii pentru a schimba modul de lucru centralizat într-unui descentralizat.
O baza de date distribuita pura este definita de C.J. Date astfel: "sprijinul complet pentru o baza de date distribuita presupune ca o aplicatie sa poata opera în mod transparent asupra datelor care sunt raspândite în baze de date diferite, gestionate de SBD-uri diferite ce ruleaza pe calculatoare diferite cu sisteme de operare diferite, interconectate prin intermediul unor retele de calculatoare diferite - în care notiunea transparent presupune ca din punct de vedere logic aplicatia va opera ca si cum datele ar fi gestionate de un singur SBD si s-ar afla pe un singur calculator[15]. Prin urmare, o baza de date distribuita poate fi definita ca o colectie de date distribuita fizic pe mai multe platforme hardware interconectate printr-o retea de comunicatie si care sunt accesate de aplicatiile locale de o maniera transparenta pentru utilizatorul aplicatiei.
Cu alte cuvinte, o baza de date distribuita e alcatuita dintr-o colectie de noduri interconectate printr-o retea de comunicatie si prezinta urmatoarele caracteristici:
o colectie de date integrate la nivel logic;
datele sunt grupate în fragmente;
fragmentele sunt rezidente pe diferite statii;
statiile sunt legate printr-o retea de comunicatii;
datele de pe fiecare statie sunt gestionate de un SGBD;
SGBD-ul fiecarei statii poate deservi aplicatiile locale în mod autonom si, în acelasi timp, poate participa la cel putin o aplicatie globala.
Exista doua tipuri de sisteme de baze de date distribuite:
sistem omogen - consta într-o retea de doua sau mai multe baze de date rezidente pe doua sau mai multe calculatoare pe care ruleaza local acelasi SGBD. O aplicatie poate accesa si modifica date din mai multe baze de date într-un singur mediu distribuit. Pentru o aplicatie-client, localizarea si platforma pe care se afla baza de date sunt absolut transparente;
sistem eterogen - pe noduri diferite pot sa ruleze SGBD-uri diferite care nu trebuie sa se bazeze pe acelasi model de organizare a datelor, fiind posibil ca sistemul sa fie format din SGBD-uri relationale, ierarhice si orientate-obiect.
Din punct de vedere al utilizatorului o baza de date distribuita (BDD) este o singura baza de date (BD) cu o schema unica. Programele de aplicatii care manipuleaza BDD au acces la date fara ca utilizatorul sa stie pe ce statie se afla fizic datele.
Arhitectura generala a unui sistem de gestiune a bazelor de date distribuite poate fi reprezentata ca în figura 2.31[16].
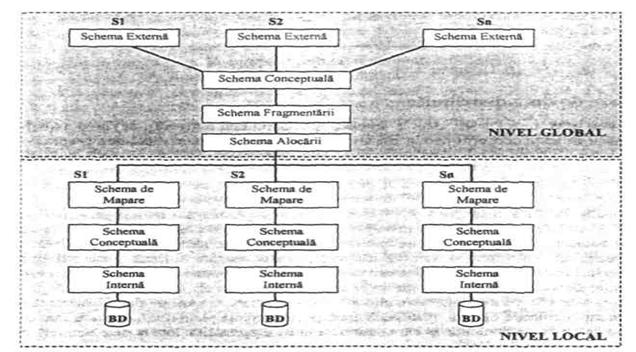 Fig.
2.31. Arhitectura generala a unui
SBDD
Fig.
2.31. Arhitectura generala a unui
SBDD
Asa cum observam si în figura 2.31, un SBDD ar trebui sa furnizeze urmatoarele elemente:
Schema globala conceptuala - o descriere logica a întregii baze de date ca si cum nu ar fi distribuita. Aici trebuie sa regasim definirea entitatilor, relatiilor, constrângerilor, securitatii si integritatii datelor fara a intra în detaliile localizarii fizice a datelor.
Schema alocarii si schema fragmentarii. Fragmentele sunt portiuni logice ale relatiilor globale ce pot fi rezidente pe una sau mai multe statii din retea. Schema fragmentarii este tocmai descrierea partitionarii logice a datelor, iar schema alocarii este descrierea localizarii fizice a datelor.
Scheme locale. Fiecare SBD local dispune de propriile scheme conceptuale si interne. Schema de mapare descrie fragmentele din schema de alocare prin intermediul unor obiecte externe în baza de date locala. Aceasta schema este independenta de SBD si constituie suportul pentru SGBD-uri eterogene.
Conceptele esentiale ce diferentiaza o baza de date distribuita de una centralizata sunt: fragmentarea, alocarea, replicarea, transparenta si tranzactiile distribuite.
Prin fragmentare întelegem ca o relatie poate fi divizata într-un numar de subrelatii, numite fragmente, care apoi sunt distribuite. Exista doua tipuri principale de fragmentare: orizontala (subset de tupluri - fragmente care au aceeasi structura ca si relatia globala dar difera prin înregistrari) si verticala (subset de atribute - fragmentele au acelasi numar de tupluri ca si relatia de baza dar structura diferita). Fragmentarea trebuie sa îndeplineasca trei conditii esentiale:
Completitudine: toate datele din relatia globala trebuie sa se regaseasca în cel putin unul dintre fragmente. Aceasta regula asigura imposibilitatea pierderii datelor.
Reconstructie: relatia de baza trebuie sa poata fi oricând reconstruita din fragmente. Aceasta regula asigura functionalitatea aplicatiilor la nivel global.
Disjunctie: o data ce apartine unui fragment nu poate apartine altora. Fragmentarea verticala este exceptia de la aceasta regula o data ce atributele cheii primare se repeta pentru a asigura reconstructia. Aceasta regula asigura redundanta minima a datelor.
Alocarea înseamna localizarea optima a fragmentelor pe diferite statii.
Termenul de localizare optima se refera la faptul ca proiectarea bazei de date distribuite trebuie sa aiba la baza informatii cantitative (frecventa tranzactiilor, statia de pe care este lansata o tranzactie si criterii de performanta ale tranzactiilor) si informatii calitative (atributele si tuplurile accesate de o tranzactie, tipul de acces - scriere sau citire - efectuat de tranzactie si predicatele operatiilor de citire).
Termenul replicare se refera la faptul ca exista copii ale datelor si ale obiectelor în mai multe baze de date locale apartinând sistemului distribuit. Astfel, într-un sistem pur distribuit exista o singura copie a datelor si a tuturor obiectelor din baza de date. Asemenea sisteme lucreaza în mod curent prin tranzactii distribuite atât pentru a accesa datele rezidente local si cele rezidente pe un alt nod din retea cât si pentru a modifica datele la nivel global în timp real. Exista doua mari tipuri de replicare: asincrona si sincrona.
Replicarea asincrona, adeseori numita si replicare de tip acumuleaza-si-transmite, preia modificarile locale, le asaza într-o coada de asteptare si, la intervale regulate, le propaga catre alte statii. Ca urmare, va exista întotdeauna o anumita perioada de timp pâna când toate statiile de replicare vor asigura convergenta datelor.
Replicarea sincrona, cunoscuta si sub numele de replicare în timp real, aplica modificarile atât local cât si pe toate celelalte statii pe parcursul unei singure tranzactii. Daca actualizarea esueaza la nivelul unui nod, întreaga tranzactie este anulata. Ca urmare, spre deosebire
de replicarea asincrona, în acest caz nu exista perioade de timp în care datele din diverse locatii sa nu se potriveasca.
Prin transparenta întelegem ascunderea detaliilor de implementare fata de utilizator. Pornind de la principiul fundamental conform caruia "pentru un utilizator, un sistem distribuit trebuie sa apara ca si cum ar fi un sistem ne-distribuit", C.J. Date a formulat obiectivele SBDD-urilor[17]:
![]() Autonomie locala - ceea ce înseamna
ca:
Autonomie locala - ceea ce înseamna
ca:
Datele locale sunt rezidente si gestionate local.
Operatiile de prelucrare locale sunt executate în întregime local.
Toate operatiile unui nod sunt controlate de acel nod.
![]() Nu exista
dependenta fata de un nod central - nu trebuie sa existe
vreun nod cu care sistemul
sa nu poata opera.
Nu exista
dependenta fata de un nod central - nu trebuie sa existe
vreun nod cu care sistemul
sa nu poata opera.
![]() Functionare
permanenta - în mod ideal, nu este necesara luarea în considerare a unor disfunctionalitati
ale sistemului, a operatiilor de adaugare sau eliminare a unui nod sau pentru crearea sau stergerea fragmentelor
de date.
Functionare
permanenta - în mod ideal, nu este necesara luarea în considerare a unor disfunctionalitati
ale sistemului, a operatiilor de adaugare sau eliminare a unui nod sau pentru crearea sau stergerea fragmentelor
de date.
![]() Transparenta
fragmentarii - utilizatorul trebuie sa poata accesa datele, indiferent de modul de fragmentare a lor.
Transparenta
fragmentarii - utilizatorul trebuie sa poata accesa datele, indiferent de modul de fragmentare a lor.
![]() Transparenta
localizarii - utilizatorul trebuie sa poata accesa datele, indiferent de nodul pe care sunt localizate.
Transparenta
localizarii - utilizatorul trebuie sa poata accesa datele, indiferent de nodul pe care sunt localizate.
![]() Transparenta
replicarii - utilizatorul trebuie sa poata accesa în mod direct o anumita copie a
datelor, fara sa fie preocupat de actualizarea tuturor copiilor.
Transparenta
replicarii - utilizatorul trebuie sa poata accesa în mod direct o anumita copie a
datelor, fara sa fie preocupat de actualizarea tuturor copiilor.
![]() Prelucrarea
interogarilor distribuite - sistemul trebuie sa trateze
tranzactiile ca unitate de
prelucrare si restaurare.
Prelucrarea
interogarilor distribuite - sistemul trebuie sa trateze
tranzactiile ca unitate de
prelucrare si restaurare.
![]() Transparenta
platformei hardware - trebuie sa fie posibila rularea SGBDD pe platforme hardware diferite.
Transparenta
platformei hardware - trebuie sa fie posibila rularea SGBDD pe platforme hardware diferite.
![]() Transparenta
sistemului de operare - trebuie sa fie posibila rularea SGBDD într-o
varietate de sisteme de operare.
Transparenta
sistemului de operare - trebuie sa fie posibila rularea SGBDD într-o
varietate de sisteme de operare.
![]() Transparenta
retelei de comunicatie - SGBDD trebuie sa functioneze indiferent
de tipul retelei de
comunicatie.
Transparenta
retelei de comunicatie - SGBDD trebuie sa functioneze indiferent
de tipul retelei de
comunicatie.
![]() Transparenta
sistemului de gestiune a bazelor de date - trebuie sa fie
posibila existenta
unui SGBDD format din SGBD locale diferite.
Transparenta
sistemului de gestiune a bazelor de date - trebuie sa fie
posibila existenta
unui SGBDD format din SGBD locale diferite.
Într-o baza de date distribuita, un rol deosebit în privinta performantelor îl constituie tipul tranzactiei, care se poate încadra în una dintre urmatoarele categorii posibile: cereri la distanta, tranzactii la distanta, tranzactii distribuite, cereri distribuite. Cererile la distanta se refera la fraze SQL trimise catre o alta locatie din retea. Aceasta cerere se executa în totalitate pe statia destinatie si are acces numai Ia date locale. Tranzactiile la distanta presupun trimiterea întregului pachet de fraze SQL ce constituie o tranzactie catre un alt nod în retea. Comiterea tranzactiei va ramâne totusi în grija clientului. Tranzactiile distribuite înseamna trimiterea frazelor SQL ce definesc tranzactia catre mai multe statii din retea pentru a se executa la distanta. si în acest caz statia-client este responsabila de comiterea tranzactiei la nivel global. Cererile distribuite presupun ca o aceeasi fraza SQL va accesa date aflate în locatii diferite.
Pentru ca am vorbit ceva mai devreme de localizare optima a datelor, vom prezenta patru strategii alternative de alocare:
Centralizare - o singura baza de date si SBD central. Costurile de comunicatie sunt foarte mari.
Fragmentare - consta în partitionarea bazei de date în fragmente disjuncte, fiecare fragment fiind rezident pe o statie distincta acolo unde datele sunt utilizate foarte frecvent. Daca se realizeaza o proiectare corespunzatoare a fragmentelor, se pot obtine performante ridicate si costuri de comunicatii reduse.
Replicare completa - consta în mentinerea unei copii complete a bazei de date pe fiecare statie. Bineînteles ca în acest caz costurile de comunicatie (pentru asigurarea sincronizarii datelor) si de stocare sunt foarte mari. Pentru reducerea acestor costuri se poate recurge la replicarea asincrona si la snapshot-uri. Un snapshot este o oapie a bazei de date la un moment dat în timp, copiile fiind actualizate periodic.
Replicarea selectiva - este o combinatie a fragmentarii, replicarii si centralizarii. în aceasta arhitectura anumite date sunt fragmentate, altele sunt rezidente numai la nivel central, iar altele sunt replicate. Prin aceasta strategie, de altfel si cea mai utilizata în practica, se încearca eliminarea tuturor dezavantajelor celorlalte strategii.
Un aspect esential al bazelor de date distribuite se refera la atomicitatea tranzactiilor atât la nivel local cât si la nivel global. Prin atomicitate întelegem faptul ca o tranzactie globala nu va fi comisa ori anulata decât atunci când toate subtranzactiile au fost comise ori anulate cu succes. în acest sens au fost dezvoltate doua protocoale de comitere pentru bazele de date distribuite: comiterea în doua faze (2PC) si comiterea în trei faze (3PC).
Asa cum sugereaza si numele, protocolul de comitere în doua faze functioneaza în doua etape: etapa de votare si etapa de decizie. Ideea de baza consta în aceea ca initiatorul tranzactiei (numit coordonator) lanseaza o cerere catre participanti pentru a afla daca sunt gata sa comita tranzactia. Daca macar unul dintre participanti voteaza pentru anulare sau nu raspunde, coordonatorul va trimite un mesaj de anulare tuturor subtranzactiilor. în caz ca toti participantii voteaza pentru comitere, coordonatorul va trimite tuturor un mesaj de comitere a tranzactiilor locale. Decizia globala trebuie adoptata de toti participantii, fiecare dintre acestia având însa libertatea de a anula imediat subtranzactia locala atât timp cât nu voteaza pentru comiterea ei (anulare unilaterala). Daca votul este favorabil comiterii atunci trebuie asteptat mesajul coordonatorului de comitere sau anulare globala. Protocolul 2PC implica asadar existenta unor procese care asteapta mesaje de la alte locatii din retea. Pentru a se evita blocajele exista si un timp maxim de asteptare dupa expirarea caruia se considera implicit vot de anulare. Problema principala a acestui protocol decurge din faptul ca în eventualitatea blocarii coordonatorului, participantii care au trimis votul de comitere si asteapta mesajul global vor fi la rândul lor blocati.
Protocolul de comitere în trei faze încearca sa elimine perioada de incertitudine pentru participantii care au votat COMMIT si asteapta mesajul global, prin introducerea unei faze intermediare (între votare si mesajul global), numita pre-commit. Pe masura ce coordonatorul primeste voturile de comitere de la participanti, trimite un mesaj global de pre-comitere pentru a înstiinta nodurile care au votat ca sunt pe cale de a comite tranzactia. O data ce au fost adunate toate voturile, coordonatorul va initia mesajul de comitere global. Anularea tranzactiei este gestionata ca si în cazul protocolului 2PC.
În 1999, cercetarile efectuate de Standish Group reliefau ca 6% din toate disfunctionalitatile aplicatiilor au fost cauzate de bazele de date. Aceasta ar fi însemnat 30 milioane USD pierderi pe an. Conform datelor studiului efectuat la nivel international, gradul de utilizare a bazelor de date distribuite vor fi utilizate în aplicatiile economice se prezinta astfel: ERP (100%), aplicatiile e-commerce (71%), iar aplicatiile pentru managementul lantului de distributie
Acelasi studiu aprecia ca trebuie luate în considerare cinci obiective pentru a câstiga o cât mai mare disponibilitate a datelor: toleranta la erori, toleranta la restaurare, toleranta de întretinere, toleranta la utilizatori, toleranta la dezastre geografice.
Toleranta la erori. O tehnica rezonabila de prevenire a erorilor cere ca utilizatorul final sa nu fie constient de erorile aparute în acelasi timp cu mentinerea calitatii la un nivel acceptabil ceea ce necesita planificarea atenta a activitatilor, astfel: (1) întotdeauna trebuie sa existe macar doua copii ale fiecarei resurse; (2) fiecare dintre acestea trebuie sa fie capabila sa suporte un nivel maxim de încarcare a traficului; (3) resursele trebuie sa fie sincronizate continuu.
Exista trei caracteristici de baza ale unei aplicatii de baze de date care concura la prevenirea erorilor:
sistemul trebuie sa poata redirectiona "din zbor" tranzactiile catre alt server sau baza de date;
sistemul trebuie sa permita balansarea dinamica a nivelului de încarcare între resurse multiple;
sistemul trebuie sa previna efectele unor false erori.
Toleranta la restaurare. Timpul de restaurare a unei baze de date în cazul aparitiei unor disfunctionalitati este considerat a fi critic în multe aplicatii în timp real. Ca rezultat, o planificare atenta trebuie sa ia în considerare urmatorii factori:
trebuie sa existe macar o copie a fiecarei resurse cu aceleasi capacitati de stocare si prelucrare ca si originalul;
baza de date trebuie sa fie complet replicata;
trebuie sa existe personal înalt calificat pentru a restaura rapid defectiunile.
De asemenea, baza de date trebuie sa furnizeze urmatoarele facilitati:
aplicatia trebuie sa poata "sari" la alta baza de date în cel mai scurt timp posibil;
abilitatea bazei de date de a trimite rapid modificarile si de a le anula la fel de rapid;
posibilitatea restaurarilor on-line (fara ca baza de date sa fie oprita).
Toleranta la întretinere. Asa cum spuneam si mai devreme, majoritatea operatiunilor de întretinere si management al bazei de date trebuie sa poata fi executate on-line. Aici includem încarcarea cu date si distribuirea acestora, crearea indecsilor, inserarea si eliminarea de tabele.
Toleranta fata de utilizatori. Utilizatorii sunt supusi prin natura lor erorii, iar erorile duc la timpi de inactivitate. De aceea este necesar un mediu grafic usor de utilizat pentru administratori.
Toleranta la dezastre geografice. Unele dezastre naturale pot afecta sever operatiunile curente ale unei companii. Timp de multi ani, un sistem informatic complet redundant era considerat mult prea scump si greu de întretinut. Oricum însa, în circumstantele actuale acest deziderat devine rezonabil datorita faptului ca: 1) Intemetul furnizeaza un schelet comun pentru o retea globala; 2) preturile echipamentelor sunt în scadere.
2.3.4.3. Sisteme de baze de date obiectuale
Tendintei actuale de extindere a bazelor de date relationale spre serverele universale îi stau în cale limitele modelului relational al datelor si cele ale SQL-ului clasic, mai ales în comparatie (inevitabila) cu forta tehnologiei obiectelor distribuite. Acest decalaj, asociat cu cresterea rapida a popularitatii Internet-ului si a conceptului Java, impune cautarea de directii noi si pentru domeniul bazelor de date, iar solutia momentului si a viitorului apropiat (incertitudinii îi putem asocia doua descrieri: suntem în perioada de tranzitie sau avem o evolutie cu panta abrupta - fiecare cititor va alege alternativa dupa gusturi) consta în bazele de date orientate obiect. Iar un efect al acestor tendinte se pare ca va consta în pierderea importantei conceptului de universal server în fata celui de baza de data obiectuala.
Tehnologia bazelor de date relationale îsi are suportul pe tranzactii bazate pe tabele (o forma destul de simpla, cu limitari din ce în ce mai evidente într-o lume interconectata si "macinând" date din ce în ce mai complexe), pe când bazele de date obiectuale sunt destinate sa suporte modele de obiecte complexe care permit functionalitati si performante superioare.
Se poate afirma fara nici un fel de riscuri ca bazele de date obiectuale sunt fundamental diferite de bazele de date relationale sau de serverele universale, datorita largii cuprinderi de facilitati tehnice destinate sa furnizeze suport pentru utilizarea distribuita a obiectelor. Însa noul concept nu înseamna neaparat un mars triumfal: nici una dintre bazele de date orientate obiect actuale nu implementeaza absolut toate functionalitatile specifice tehnologiei orientate obiect, putându-se totusi distinge mai multe niveluri pe scala completitudinii.
Cea mai evidenta facilitate a unei baze de date orientate obiect este viteza de acces la date în comparatie cu cea a sistemelor relationale sau relational extinse (servere universale sau chiar baze de date obiectual-relationale).
Bazele de date obiectuale stocheaza o harta a ierarhiilor si relatiilor claselor de obiecte, structura ce permite o accesare directa. Aceasta navigare nemijlocita prin date conduce la cea mai performanta abordare privind stocarea si consultarea informatiilor orientate obiect.
Ca efect al organizarii tabelare a datelor, un server universal trebuie sa dezasambleze obiectele pentru a le înmagazina în tabele, pentru ca mai apoi sa fie nevoit sa reuneasca componentele obtinute la faza de stocare pentru a permite accesul la obiecte în forma lor naturala, ceea ce înseamna complicatii deosebite si la nivelul programarii aplicatiilor. Este adevarat ca pentru sisteme orientate obiect de complexitate redusa serverul universal îsi face treaba fara probleme. Cum însa obiectele sunt deocamdata cele mai potrivite si expresive forme de organizare a datelor pentru modelarea evenimentelor lumii reale, tendinta de a se crea sisteme orientate obiect din ce în ce mai complexe este clara. Ceea ce duce la concluzia ca strategia serverelor universale va trebui regândita.
Un alt aspect care "înghesuie" serverul universal este dat de maparea relatiilor complexe dintre obiectele bazei de date, pentru care bazele de date orientate obiect nu trebuie sa se straduiasca, fiind un adeziv natural la ierarhiile de mostenire.
Clustering (grupare sau portionare a datelor):
Abilitatea bazei de date obiectuala de a realiza portionarea fizica de obiecte pentru a ridica performanta sistemului este legata de abilitatea sa nativa de a naviga. Astfel, obiectele - necesare la un moment dat unei cereri client sau altui server - sunt aduse integral în memoria locala. Deoarece acestea pot fi manevrate la un mult mai fin nivel de granularitate decât tabelele mapate ale serverului universal, baza de date obiectuala câstiga avantaj prin strategia acordului fin, ceea ce are ca efect practic si minimizarea traficului prin retea. Tot clustering-ul este cel care permite unei baze de date obiectuale sa acceseze eficient toate obiectele, astfel încât sa permita simultan mai multor utilizatori si aplicatii sa aiba fiecare o imagine a modelului obiect original.
Bazele de date orientate obiect ofera functionalitati unice când se pune problema datelor distribuite. Cheia acestui avantaj consta în existenta unui identificator unic care izoleaza numele logic al obiectului de locatia fizica a acestuia, de unde rezulta si posibilitatea ca o baza de date singulara sa fie separata pentru a rula pe sisteme cu mai multe procesoare, respectiv pe o aceeasi masina (de exemplu, prin SMP - Symmetric MultiProcessing) sau într-o retea de calculatoare. Granularitatea fina permisa de tehnologia bazelor de date orientate obiect ajuta la replicarea eficienta a datelor.
Distribuirea datelor astfel încât mai multe calculatoare sa aiba parti distincte ale unei aceleiasi baze de date logice este destul de dificil de implementat pe serverele universale întrucât acestea trebuie sa mentina constrângerile specifice definitiei tabelare a datelor pentru întreaga retea, iar când manevreaza date orientate obiect, acest lucru devine un handicap.
Replicarea datelor (solutie prin care baza de date este segmentata în componente discrete ce sunt mentinute legate prin sincronizare) este obtinuta mult mai eficient în cadrul bazei de date orientate obiect datorita aceluiasi transfer de informatie mult mai granular. În cazul bazelor de date relationale, nivelul replicarii este substantial mai ridicat pentru ca se tranzactioneaza cu tabele, aceasta însemnând si costuri mai ridicate pentru serverele care trebuie sa suporte un trafic intens.
În mod firesc, majoritatea bazelor de date orientate obiect destinate mediilor critice trebuie sa permita modificari asupra structurii datelor, ceea ce presupune reorganizarea ierarhiilor de mostenire sau a relatiilor dintre obiecte. Sistemele performante de baze de date orientate obiect contin functii prin care se poate modifica schema fara a scoate din functiune baza de date. Actualizarea on-line a schemei bazei de date prin algoritmi incrementali permite introducerea fara socuri a schimbarilor ce apar pe parcurs asupra organizarii sistemului. Exista chiar posibilitatea de a memora diferitele versiuni ale modelului obiectual pentru a facilita adaptarea aplicatiilor la cel mai potrivit dintre acestea.
Sistemele de gestionare a bazelor de date relationale folosesc uzual o strategie statica pentru modificarea bazei de date, ceea ce presupune oprirea aplicatiei pentru recompilarea schemei si pentru refacerea relatiilor si a dependentelor SQL.
Arhitectura client/server: este considerata una dintre cele mai subtile caracteristici ale bazelor de date obiectuale.
În mod frecvent, un server central se ocupa de accesul concurent si de integritatea bazei de date în timp ce clientul asigura alte functii. În cazul bazei de date obiectuale, functionalitatii clientului i se adauga capacitatea de a accesa date multiple si de a asambla obiectele servite pentru a crea o imagine locala unificata. Suportul pentru multithreading permite clientilor sa implementeze simultan mai multe task-uri specifice.
Natura distribuita a bazelor de date orientate obiect este evidentiata de capacitatea de a mentine copii locale ale obiectelor fara a suprasolicita serverul central sau reteaua. Accesarea obiectelor printr-o memorie cache locala s-a dovedit de câteva sute de ori mai rapida decât accesarea datelor organizate relational în cadrul aceleiasi configuratii de retea. În cazul serverelor universale, procesarile bazei de date au loc central. De fiecare data când o aplicatie client/server necesita date, ea trebuie sa le ceara de la server, existând doar posibilitatea de a oglindi la client tabele. Este foarte dificil sa se programeze o aplicatie care sa mapeze de partea clientului date sub forma de obiecte, atât timp cât tehnologia de nucleu nu opereaza decât cu tabele.
Arhitectura N-Tier: Luând in considerare perspectivele sistemelor orientate obiect si expansiunea Internet-ului si a intranet-urilor, specialistii prevad ca arhitectura sistemelor de aplicatii va evolua catre o structura N-Tier (serie-n). Unei astfel de organizari îi este caracteristic traficul intens de mesaj dintre numeroasele subsisteme componente: clientii unei aplicatii server solicita date pe care aceasta le cere serverului de Web sau de baze de date, iar acesta le colecteaza de la multe alte servere back-end pentru a completa raspunsul la cererea initiala. Prin chiar esenta ei, baza de date obiectuala are abilitatea de a lucra cu vederi logice ale obiectelor distribuite, constituindu-se într-o solutie naturala pentru aplicatii N-Tier, unde integritatea tranzactiilor si scalabilitatea aplicatiilor cântaresc mult.
De cealalta parte, pentru a deservi fluent un astfel de model distribuit ar fi necesare mai multe servere universale centralizate, cu performante si capacitati deosebite. De ceva timp suntem martorii efortului de armonizare dintre serverele universale si mediul distribuit prin Network Computer Architecture promovata de Oracle, al carui succes pe termen lung înca nu este foarte sigur.
Abilitatea de a rula o aplicatie a bazei de date constituie o cerinta importanta pentru multe sisteme. În lumea serverelor universale executia programelor se refera la procedurile si declansatoarele bazei de date relationale, ambele lucrând cu tabele de date. Aceste coduri executabile sunt solutii particulare, nesuportând o executie generalizata, de preferat într-un mediu deschis. Chiar folosind extensiile promovate de SQL3, aceste programe nu sunt ideale pentru aplicatii orientate obiect. Contrastul este banal, bazele de date obiectuale lucreaza cu limbaje de programare orientate obiect recunoscute ca standarde internationale: C++, Java si chiar Smalltalk.
Toata lumea a observat ca limbajul Java este promovat - atât la nivel înalt, cât si la nivel de masa - ca solutie ideala pentru dezvoltarea de software bazat pe componente (faptul ca sistemul este asamblat din blocuri de construire predefinite reduce timpul de dezvoltare si complexitatea abordarii) si de sisteme de comunicatii orientate obiect. Având ca premisa adoptarea universala a protocoalelor de comunicatii performante (TCP/IP si altele) devine posibil sa se creeze aplicatii orientate obiect dispersate, ale caror componente sa fie plasate în puncte cheie din perspectiva performantei, a flexibilitatii sau a altor cerinte tehnice.
Pentru ca penetrarea tehnologiei obiectuale este tot mai evidenta, comitetul de standarde care guverneaza limbajul SQL si-a propus sa ia în considerare asigurarea suportului pentru conceptele orientate obiect. Însa mentinerea compatibilitatii cu bazele de date existente si minimizarea efortului de tranzitie au determinat acest comitet sa recomande doar o extindere a lui SQL si pastrarea contextului orientat pe tabele.
2.4. Modelarea conceptuala a datelor
2.4.1. Aspecte generale privind modelarea conceptuala a datelor
Un model conceptual este format dintr-un set de concepte care alcatuiesc modelul formal, la care se adauga o anumita viziune a analistului asupra realitatii investigate referitoare la sistemul modelat.
Modelele conceptuale reprezinta de fapt un limbaj specializat, cu ajutorul caruia, sunt descrise aspectele calitative esentiale ale sistemelor reale, indiferent de gradul lor de complexitate. Ele pot sa preceada alte tipuri de modele si sunt utilizate pentru probleme slab sau prost structurate, sau chiar nestructurate (instabile, cu multe modificari) pentru care este dificil sau imposibil de elaborat alte tipuri de modele.
În afara acestui avantaj, modelele conceptuale sunt utile în analiza de sistem deoarece:
clarifica (precizeaza) viziunea analistului asupra sistemului analizat;
defineste structura si logica sistemului prin ilustrarea conceptuala, simbolica pe care o ofera;
constituie o premisa pe baza careia se poate realiza activitatea de proiectare a noului sistem.
Limbajul utilizat în cadrul metodelor conceptuale face apel la o serie de concepte fundamentale din teoria generala a sistemelor sau derivate din acestea, din care mentionam:
a) Procesul de transformare, care este reprezentat de multimea activitatilor necesare pentru transformarea intrarilor sistemului în iesirile dorite. Din acest punct de vedere, orice model conceptual trebuie sa contina cel putin un proces de transformare.
b) Gradul de conectivitate, reflecta dependenta logica, surprinsa de model, între activitatile sistemului în procesul de transformare.
De exemplu, activitatea de transformare a materiilor prime în produse finite trebuie precedata de activitati ca: stabilirea sortimentului si a cantitatii de produse finite, pregatirea fortei de munca, aprovizionarea cu materii prime si materiale etc., care sa asigure desfasurarea normala a fluxului tehnologic care defineste procesul studiat.
Dependenta sau conectivitatea activitatilor poate fi relevata pe baza unor premise teoretice, pornind de la fluxul tehnologic, sau apelând la cunostintele unor experti, consilieri etc. Una dintre cele mai importante conectivitati în analiza de sistem este cea informational-decizional.
d) Obiectivul sistemului modelat se afla într-o legatura directa cu rezultatele dorite ale proceselor de transformare pe care le include sistemul real si, din punct de vedere practic, reprezinta însasi ratiunea acestuia de a exista, finalitatea sa.
Astfel, asigurarea ritmica cu resursele necesare desfasurarii continue a procesului de productie, urmarirea operativa a stocurilor, reducerea stocurilor supranormative, urmarirea consumurilor specifice etc., reprezinta obiective specifice modelarii subsistemului de aprovizionare.
d) Performanta modelului/sistemului este un indicator care cuantifica gradul de îndeplinire a obiectivelor propuse ale sistemului. Informatiile obtinute pe baza indicatorilor de performanta sunt folosite pentru efectuarea unor actiuni de control în cadrul unor proceduri de luare a deciziilor (verificarea efectelor deciziilor luate), în vederea stabilirii corectiilor necesare pentru îmbunatatirea modelului. Totalitatea acestor proceduri formeaza mecanismul de decizie/control pentru îmbunatatirea performantelor sistemului.
De exemplu, daca obiectivul sistemului îl constituie satisfacerea unei cereri exprimate pe piata, atunci performanta sistemului poate fi data de nivelul de satisfacere a segmentului de piata, cuantificabil prin determinarea ponderii detinute de sistem pe aceea piata. Pe baza acestui indicator se pot adopta deciziile pentru îmbunatatirea calitatii produsului, a activitatilor de promovare si de vânzare a produsului (reclama, studii de piata) etc.
e) Granitele sistemului delimiteaza un cadru mai mult sau mai putin restrâns, în functie de scopul analizei, în care se iau actiunile de decizie-control si sunt definite de limitele pâna la care activitatile si elementele sistemului raspund mecanismului decizional propriu sistemului analizat.
f) Nivelul/gradul de rezolutie al modelului, reflecta gradul necesar de detaliere a sistemului conform procedurii de analiza structurala (descompunere) si depinde de obiectivele urmarite si de resursele disponibile.
g) Resursele (materiale, financiare, umane, de timp) sunt necesare atingerii obiectivelor sistemului si se afla sub controlul procedurilor decizionale.
h) Viziunea observatorului asupra realitatii. Multimea conceptelor enumerate si exemplificate, prezinta modelul formal al sistemului. Acelasi sistem poate fi descris în mod distinct de observatori diferiti, perceptia fiecaruia fiind influentata mai mult sau mai putin de factori obiectivi, subiectivi si de incertitudine
Obiectivul sistemului poate fi înlocuit printr-o asa numita definitie-radacina (de baza), care este mai mult decât o simpla reformulare a obiectivului, ea înglobând si viziunea analistului în raport cu care se face descrierea sistemului.
Modelele conceptuale apar ca o constructie logica asociata unei multimi de interactiuni specifice sistemelor cu activitate umana, care ofera un mijloc de analiza a oricarei probleme (situatii) indiferent de contextul organizational. Activitatile specifice fiecarui subsistem, implica o actiune efectiva, si de aceea, în limbajul de modelare conceptuala sistemele si subsistemele analizate sunt reprezentate prin verbe.
Modelul este o descriere a unei situatii problema prin care se evidentiaza varietatea fizica structurala (folosind chiar un limbaj matematic) si multimea interactiunilor care determina comportamentul sistemului.
Procesul de modelare conceptuala a unui sistem real se desfasoara în mod iterativ pâna la atingerea nivelului de rezolutie dorit si urmareste parcurgerea etapelor ilustrate sugestiv în fig.2.32.
Dupa n iteratii se obtine varianta finala a modelului conceptual, în conformitate cu nivelul de rezolutie dorit si cu setul de ipoteze si de criterii utilizate.
Fiecare model conceptual va fi derivat si dezvoltat de la o definitie de baza, care arata ce este sistemul respectiv si va desemna multimea de activitati pe care sistemul trebuie sa le desfasoare pentru atingerea obiectivelor sale. Apoi, fiecare activitate va fi detaliata la rândul ei, într-un numar de nivele, pornind de la propria sa definitie, si în functie de o viziune-sinteza a analistului si a fiecaruia din managerii compartimentelor implicate în analiza sistemului.

Fig.2.32. Procesul de modelare conceptuala
Procesele modelate prin analiza de sistem se preteaza mai greu abordarilor în sensul optimizarii, de aceea modelarea conceptuala are în vedere determinarea acelui rang al viziunii asupra sistemului, pe baza unui numar cât mai mare de modele echivalente, care sa ofere cea mai relevanta imagine asupra situatiei existente.
2.4.2. Modelul conceptual al datelor (diagramele entitate-relatie)
Modelul conceptual al datelor înseamna o modalitate de reprezentare a datelor organizatiei, având rolul de a scoate în relief toate regulile privind identitatea si legaturile existente între date.
Cea mai cunoscuta forma utilizata pentru modelarea datelor este diagrama entitate-relatie (DER). O modalitate aproape identica este folosita si în analiza si proiectarea orientata-obiect.
O grupare "traditionala" a modelelor utilizate în bazele de date delimiteaza trei categorii: modele logice bazate pe obiect, modele logice bazate pe înregistrare si modele fizice.
Modelele logice bazate pe obiect permit descrierea datelor la nivelurile conceptual si extern. Se caracterizeaza prin flexibilitate si explicitate în reprezentarea structurilor de date] si a restrictiilor pe care trebuie sa le îndeplineasca acestea. Cele mai raspândite structuri aceasta grupa sunt:
entitati-asociatii (E-A), referita si ca entitati-relatii (E-R);
semantica;
functionala;
orientata pe obiecte.
Dintre acestea, o importanta deosebita o prezinta structura entitate-asociatie, considerata un instrument foarte util în analiza si proiectarea bazelor de date, precum si cea orientata pe obiecte, de mare actualitate, dar mai ales de mare viitor în ceea ce priveste evolutia BD.
Modelul E-R are la baza perceptia lumii reale sub forma unei colectii de obiecte denumite entitati, unite prin asociatii. O entitate este un obiect ce poate fi diferentiat de alte obiecte printr-un ansamblu de atribute care permit descrierea precisa a acestuia. De exemplu, atributele Numar si Disponibil pot defini un cont deschis la o banca de catre o persoana fizica. O asociatie reuneste doua sau mai multe entitati. O asociatie "leaga" un client de fiecare din conturile pe care acesta le are deschise la banca respectiva. Ansamblul entitatilor de acelasi tip formeaza o clasa de entitati iar ansamblul asociatiilor de acelasi gen reprezinta o clasa de asociatii.
Structura de ansamblu a unei baze de date poate fi descrisa printr-o diagrama E-R care contine: dreptunghiuri, utilizate pentru reprezentarea claselor de entitati; elipse, pentru reprezentarea atributelor; romburi, pentru clasele de asociatii; linii, ce pun în legatura, pe de o parte, atributele si clasele de entitati si, pe de alta parte, clasele de entitati si clasele de asociatii.
Modelarea datelor prin DER prezinta caracteristicile si structura datelor independent de modul în care acestea sunt memorate în calculator. Modelul se creeaza iterativ. De cele mai multe ori, operatiunea are loc la nivel de întreprindere, prin apelarea la o categorie foarte larga de date, neglijându-se detaliile exagerate.
Doar în etapele urmatoare, în speta când se trece la definirea proiectului, are loc construirea unui model anume entitate-relatie, prin care sa fie scoasa în evidenta aria de întindere a proiectului.
|
Sistem/subsistem informational Proceduri Informatii |

![]()
![]()
![]()
![]()

![]()

![]()
![]()
Fig. 2.33. Procesul de modelare a datelor si prelucrarilor
Modelul E-R asigura perceperea de catre utilizatori fara sa prezinte detaliile de stocare a datelor pastrate în calculator. A fost definit modelul datelor întrucât este compus dintr-un grup de concepte ce specifica structura bazei de date împreuna cu un set de operatii necesare manipularii lor. Modelul ER este o forma simpla de prezentare a structurii datelor, utilizat în procesul constructiei bazei de date, dar si în alte aplicatii în care apare entitati si relatii între acestea.
Modelul entitate-relatie urmareste obtinerea unei reprezentari fidele, utilizând concepte specifice, a realitatii (problemei de rezolvat ce urmeaza a fi informatizata). Aceasta reprezentare a lumii reale se va realiza facându-se abstractie de orice restrictie fie ea informatica sau organizatorica. Pornind de la semantica obiectelor lumii reale si a legaturilor stabilite între acestea modelul entitate-relatie serveste în egala masura ca un mijloc de comunicare între modelator (informatician) si viitorul utilizator al sistemului (beneficiarul), care descrie realitatea supusa modelarii în conformitate cu propria lui perceptie.
Concepte de baza utilizate de catre modelul entitate-relatie
În continuare, vom prezenta conceptele de baza utilizate de catre modelul entitate-relatie.
ENTITATEA reprezinta un obiect al realitatii modelate caracterizat printr-o existenta proprie, cu o identitate proprie (care-l face identificabil în raport cu celelalte obiecte de acelasi tip) si o multime de caracteristici care exprima proprietatile acestuia.
Pentru exemplificare, vom lua ca domeniu de studiu gestiunea produselor finite. Entitatile pe care le putem defini sunt: un produs, un bon de predare, o comanda (pentru lansarea în fabricatie a produselor etc.).
Entitatea comanda nr.1113 se defineste prin urmatoarele caracteristici: 20/09/03 (data lansarii), costum dama model A (denumirea produsului finit), 200 (numarul de bucati de fabricat), 2 (sectia de productie în care s-a lansat comanda) etc. Entitatea comanda 1113 are propria identitate, distingându-se clar de celelalte entitati de acelasi tip (celelalte comenzi lansate în executie) prin numarul sau si are o existenta de sine statatoare. (fig.2.34).


![]()
Fig.2.34. Entitati apartinând tipului Comanda
Fiecare comanda de productie reprezinta o entitate distincta si independenta în raport cu toate celelalte comenzi lansate.
În activitatea de modelare interesul se focalizeaza pe definirea tipurilor de entitati apartinând problemei de rezolvat si nu pe entitati care reprezinta realizarile tipurilor de entitati. Modelul abstract pe care ni-l ofera modelul entitate-relatie se bazeaza tocmai pe aceste tipuri generice de entitati si a legaturilor stabilite între acestea.
TIP DE ENTITATE reprezinta un concept generic desemnând multimea tuturor entitatilor prezentând aceleasi caracteristici constructive.
Tipul entitatii cunoscut si sub numele de clasa entitatii, este o colectie de entitati care au proprietati sau caracteristici comune. Fiecarui tip de entitate i se atribuie un nume, cât timp numele reprezinta o clasa sau un set de cazuri, el este singular. Cum referirea generala la elementele ce pot fi catalogate ca entitati se face prin notiunea de obiect (desi sensul lui poate fi altul în contextul analizei si proiectarii orientate-obiect), referirea la aceasta se va realiza printr-un substantiv la singular. Se vor folosi litere majuscule, plasate în interiorul dreptunghiului corespunzator entitatii.
![]()
![]()


![]()


![]()



Fig.2.35. Entitati si tip de entitate
O instantiere a entitatii sau instanta, numita caz al entitatii sau caz, este o manifestare singulara a unui tip de entitate. Un tip de entitate se descrie o singura data prin modelul datelor, în timp ce mai multe cazuri ale aceluiasi tip de entitate pot fi reprezentate prin datele stocate în bazele de date.
Exemple: produs, comanda, angajat, student, contract etc.
De aceasta data tipul de entitate produs desemneaza ansamblul produselor aflate în catalogul firmei, produse descrise plecând de la aceleasi caracteristici comune: codul produsului, denumirea, unitatea de masura, data omologarii, procent TVA.
Tipurile de entitate student desemneaza ansamblul studentilor caracterizati prin aceleasi trasaturi comune: numar matricol, nume, data nasterii, localitatea, facultatea, specializarea etc.
O entitate poate apartine mai multor tipuri de entitati diferite. De exemplu entitatea Popescu poate apartine si tipului de entitate contribuabil si tipului de entitate angajat si tipului de entitate student.
Fiecare tip de entitate se defineste prin multimea caracteristicilor comune apartinând entitatilor tipului.
ATRIBUTUL defineste o proprietate distincta a unei entitati. Fiecare atribut prezinta un domeniu, adica o multime de valori admise. Într-o entitate se regasesc realizari corespunzatoare caracteristicilor definitorii pentru tipul de entitate.
Prin intermediul atributelor entitatea poate fi descrisa din punct de vedere informational ca o componenta a structurii bazei informationale. În aceasta viziune atributul poate fi considerat ca o variabila careia i se pot asocia o multime de valori, cu mentiunea ca acestea pot fi grupate sub un identificator comun.
Atributele sunt reflectate printr-un continut concret denumit valoare, care reda nivelul real al fenomenelor si proceselor economice cuantificate prin intermediul entitatii.
Atributele pot fi clasificate în functie de mai multe criterii:
a) Din punct de vedere structural, al complexitatii, acestea pot fi elementare si compuse.
Atributele elementare sunt componente informationale ireductibile ce nu mai pot fi descompuse în alte atribute
(COD-MAT, DEN-MAT, UM, PREŢ etc.).
Atributele compuse sunt componente informationale reductibile ce pot fi descompuse în atribute elementare (DATA poate fi descompusa în atributele elementare ZI, LUNĂ, AN).
b) Din punct de vedere al stabilitatii în timp atributele pot fi constante, variabile si de stare.
Atributele constante îsi mentin valoarea neschimbata pe toata existenta bazei informationale fiind invariabile în timp în functie de semantica atributului (COD-MAT, DEN-MAT, UM etc.).
Atributele variabile îsi schimba valoarea pe parcursul existentei bazei informationale, fiind variabile în timp în functie de semantica atributului (NR.DOC, DATA-DOC, VALOARE etc.).
Atributele de stare îsi schimba valoarea numai la anumite intervale de timp ale existentei bazei informationale prin modificarea efectuata de atributele constante, variabile sau chiar de stare (STOC-INIT, STOC-FINAL, SOLD-DEBITOR, SOLD-CREDITOR etc
c) Dupa realizarile pe care le pot prezenta atributele pot fi: obligatorii, optionale, monovaloare si multivaloare.
Atributele obligatorii (trebuie sa prezinte obligatoriu o realizare, ceea ce corespunde sintagmei NOT NULL - orice realizare), exemplu: atributul data nasterii, nume student.
Atributele optionale (sunt atribute care pot sa nu prezinte nici o valoare (realizare) în cadrul unei entitati (de exemplu atributele numar telefon, fax, e-mail - nu toate persoanele au telefon, fax, e-mail).
Atributele monovaloare prezinta o singura valoare în cadrul unei entitati (nume student, nr.matricol, data nasterii, codul numeric personal)
Atributele multivaloare prezinta mai multe realizari în cadrul aceleiasi entitati (ANGAJAT, entitatea Ionescu Dan poate prezenta pentru atributul STUDII mai multe valori: Facultatea de Electrotehnica, facultatea de Drept).
Problema de modelat este adesea deosebit de complexa în cadrul ei putându-se identifica obiecte simple, compozite si/sau complexe.
În modelul entitate-relatie obiectelor lumii reale le corespund entitati, iar entitatile definite prin aceleasi caracteristici formeaza un tip de entitate, ceea ce înseamna ca obiectelor simple, le va corespunde în modelul conceptual al datelor câte un tip de entitate.
Exemplu: pentru conturile cuprinse în planul de conturi se poate defini în cadrul modelului conceptual al datelor tipul de entitate cont.
Obiectele compozite se caracterizeaza prin faptul ca ele contin una sau mai multe caracteristici multivaloare (carora în modelul entitate-relatie le vor corespunde atribute multivaloare). Aceasta va determina ca în modelul conceptual optimizat al datelor acestui obiect compozit sa-i corespunda mai multe tipuri de entitati (atributele multivaloare se vor regasi într-un tip de entitate distinct).
Obiectele compuse sunt decompozabile ele regrupând în structura lor obiecte simple între care exista o anumita legatura. Chiar daca în modelul entitate-relatie initial pentru un obiect compus s-a definit un singur tip de entitate, ulterior acesta se va descompune în tipuri de entitati de sine statatoare corespunzatoare obiectelor elementare care intra în structura obiectului compus.
Fiecare tip de entitate prezinta un IDENTIFICATOR reprezentat de un atribut sau un grup minimal de atribute al caror rol este de a permite identificarea în mod unic, fara echivoc, a entitatilor.
De multe ori identificatorul este reprezentat de un atribut de tip "numar de ordine" (incrementat cu 1 pentru fiecare noua valoare atribuita) sau de un cod (constructie artificiala având o anumita semnificatie).

![]()
![]()






![]()
![]()
![]()
![]()
Fig.2.36. Reprezentarea obiectelor compozite sub forma de tipuri de entitati
Exemple, pentru tipul de entitate PRODUS (descriind caracteristicile produselor din nomenclatorul de fabricatie) identificatorul va fi COD PRODUS (element codificat), în cazul entitatii BON CONSUM identificatorul va fi atributul numar (atribut de tip numar de ordine).
În reprezentarea grafica a tipului de entitate identificatorul este marcat distinct prin subliniere.
![]()

Fig.2.37. Reprezentarea grafica a tipului de entitate PRODUS
ASOCIEREA dintre entitati exprima legatura stabilita între acestea si rolul pe care îl joaca fiecare entitate participanta la legatura. O relatie este o asociere între cazurile/instantele uneia sau mai multor tipuri de entitati care prezinta interes pentru organizatie. Ele se pot simboliza printr-un romb. Relatiile sunt redate prin verbe. Exprimând o legatura între entitati ea nu are o existenta de sine statatoare.
O relatie poate prezenta unul sau mai multe atribute proprii cu rol de a caracteriza legatura stabilita între entitatile participante la asociere.
O clasa, este reprezentata printr-un dreptunghi divizat în trei parti: portiunea superioara reprezinta numele clasei, cea din mijloc atributele sale si cea inferioara operatiile asociate clasei. Atributele, trebuie sa fie date de tipuri simple (numerice, siruri de caractere etc.).


lucreaza
![]() pentru
pentru
![]()
![]()
Fig.2.39. Asocierea multi-la-unu
Asocierea lucreaza pentru, este de ordinul multi-la-unu deoarece o companie poate angaja o multime de persoane în timp ce un angajat poate activa, în acelasi interval de timp, la o singura companie (cu carte de munca). Pot exista însa, si cazuri în care aceasta asociere sa fie de tipul multi-la-multi.
Multiplicitatea depinde de modul de abordare al problemei, deci de definire a frontierelor acesteia, fiind dependenta de context. Abordarea cea mai frecvent întâlnita, este reducerea multiplicitatii unei asocieri la una de tip unu-la-mai multi sau chiar unu-la-unu. Este important sa nu se piarda prea mult timp cu stabilirea exacta a ordinelor de multiplicitate în timpul analizei, deoarece aceasta se poate modifica în timpul proiectarii sistemului sau chiar implemetarii sale. O solutie sigura, este de a utiliza multiplicitatea de ordinul multi-la-multi.
O relatie care se poate întâlni din când în când este relatia unu la unu (one-to-one). Doua tabele unite printr-o relatie unu la unu sunt similare în practica, cu un tabel care cuprinde câmpurile din ambele tabele, dar cu toate acestea, devine oportuna utilizarea unei astfel de relatii, în conditiile utilizarii unor structuri foarte mari care au nevoie de peste 255 de câmpuri, când este necesara stocarea locala a unor date suplimentare (în cazul în care tabelul principal este un tabel asociat de pe un server, asigurarea unei securitati a datelor când câmpurile celui de-al doilea tabel vor fi facute disponibile pentru persoanele care supervizeaza.
Relatia de unu la mai multi (one-to-may), este cea mai cunoscuta si cea mai utila relatie. Tabelul din partea "unu" a relatiei trebuie sa aiba o cheie primara, iar tabelul din partea "mai multi" trebuie sa contina un câmp similar, indicând înregistrarea la care este legat. În mod normal, cheia straina trebuie sa fie de acelasi tip si sa aiba aceeasi dimensiune ca si cheia primara.
O factura poate avea mai multe rânduri de elemente, fiind nevoie de doua tabele denumite Facturi si Pozitii din Factura. În plus un client poate avea mai multe facturi, în consecinta va mai exista o relatie de unu la mai multi între tabelele Clienti si Facturi.
Unele situatii nu se potrivesc cu o relatie simpla de la unu la mai multi. De exemplu, considerând actualul sistem de credite de la Facultatea de stiinte Economice, sarcina administratorului acestei facultati este sa tina evidenta tuturor studentilor înscrisi la facultate, precum si a tuturor cursurilor pe care aceasta le ofera. Se pune întrebarea care este relatia dintre studenti si cursuri, deoarece un student este înscris la mai multe cursuri, dar de asemenea un curs este tinut pentru mai multi studenti. Deci putem spune ca aceasta relatie este de la mai multi la mai multi (many-to-many).
Pentru rezolvarea acestei relatii solutia consta în crearea unui tabel intermediar care "sparge" relatia de mai multi la mai multi într-o pereche de relatii de la unu la mai multi. În cazul exemplului anterior, tabelul intermediar ar putea fi denumit Înscrieri. Tabelul Înscrieri cuprinde numai doua câmpuri: IdentificatorStudent si IdentificatorCurs. De fiecare data când un student se înscrie la un curs, apare câte o înregistrare în tabelul Înscrieri, ceea ce determina existenta unei relatii de la unu la mai multi între tabelele Studenti si Înscrieri si tot a unei relatii de la unu la mai multi între tabelele Cursuri si Înscrieri.
Figura urmatoare prezinta acest tip de relatii sub forma unei diagrame:
TabelulStudenti IdentificatorStudent NumeDeFamilie Prenume TabelInscrieri IdentificatorStudent IdentificatorCurs

![]()
![]()

![]()
![]()
![]()
![]()
Fig.2.41. Exemplu de diagrama pentru relatiile alternative
Citirea diagramei este:
o marfa se poate asocia sau cu un producator din afara, sau cu productia unitatii;
un producator din afara poate livra mai multe marfuri;
o linie proprie de productie poate livra mai multe marfuri.
Modelarea conceptuala a datelor este un proces pas-cu-pas pentru documentarea cerintelor informationale, concretizata în preocuparea de regasire a structurii datelor, dar si a regulilor prin care se ofera încredere în integritatea acestora.
Regulile economice constituie specificatii/descrieri care ofera integritatea modelului logic datelor. Exista patru tipuri de baza ale regulilor economice.
Restrictii de integritate
Restrictiile de integritate definesc cerintele pe care datele trebuie sa le respecte pentru a fi corecte si coerente în raport cu realitatea pe care o reflecta.
Restrictiile de integritate reprezinta o modalitate de integrarea a semanticii datelor în mod indirect în modelul entitate-asociere pe care astfel îl îmbogatesc.

|
CUPRINDE CANTITATE |


![]()
![]()
![]()
![]()
![]()
|
DEPOZITAT STOC DATA STOC |

![]()
![]()
Fig.2.42. Model entitate-relatie
Restrictiile de integritate privesc:
q valorile pe care le pot lua atributele entitatilor si asocierilor;
q valorile identificatorilor entitatilor;
q rolurile jucate de entitati în asocierile la care participa;
q asocierile stabilite între entitati
Pentru modelul prezentat în figura de mai sus, pot fi definite urmatoarele restrictii de integritate privitoare la realizarile atributelor: data documentului sa fie anterioara datei curente sau egala cu aceasta, cota de TVA poate fi 0% sau 19%, produsul cel mai vechi din nomenclatorul de fabricatie a fost omologat în 12.12. 2005, codul gestiunii poate lua valori în multimea M=, iar unitatile de masura sunt kg si BUC.
Restrictiile de integritate pot fi statice (se verifica permanent) sau dinamice (privesc evolutia în timp a datelor). De exemplu restrictiile referitoare la gestiune si unitatile de masura sunt statice. Restrictia privind cota de TVA este dinamica ea putându-se modifica în timp, în conformitate cu prevederile fiscale în vigoare.
În cazul entitatii STUDENT, alaturi de atributele numar matricol si nume poate fi definit si atributul fel student (bursier/nebursier). Atributul felul studentului este dinamic el modificându-si valoarea în timp.
Restrictii de domeniu
Un domeniu este un set al tuturor tipurilor de date si al intervalelor de valori în care trebuie sa se încadreze atributele.
Restrictiile de domeniu reprezinta conditii (reguli) care privesc ansamblul de valori admise pentru un atribut în cadrul tipului sau domeniului sau. Restrictiile pot viza realizarile unui/unor atribute apartinând unei aceleiasi entitati sau asocieri, caz în care se numesc restrictii intraentitate sau a unui/unor atribute apartinând unor entitati si/sau asocieri diferite, caz în care se numesc restrictii interentitati.
Restrictiile de domeniu se pot exprima cu privire la:
q Continutul unui singur atribut al unei entitati sau asocieri
Unitate Masura = ;
TVA=;
Cantitate>0(cantitatea este un atribut definit pentru relatia din fig.2.39. (&&&Entitate)
DATA DOC apartine intervalului [01/01/05, 12/31/06]
q Corelatiile ce trebuie sa se respecte între valorile mai multor atribute sau asocieri
De exemplu, daca GESTIUNE=1 atunci COD PRODUS =. În gestiunea 1 se stocheaza doar produsele având codurile în multimea .
Produsul având codul 17 se masoara în kg: cod produs = 17, UM = kg.
q Corelatiile ce trebuie sa existe între atributele apartinând mai multor entitati sau relatii diferite
Data-stoc>Data omologarii
Cantitate<=Stoc
q Corelatii realizate pe baza unor valori obtinute prin operatii de sintetizare (însumare, calculul mediei, valorile minime/maxime etc.) a unui ansamblu de entitati.
Valoarea medie a pretului<=1.000.000
Restrictii structurale
Identificarea entitatilor
Fiecare entitate va trebui sa poata fi identificata fara echivoc. Acest lucru impune ca identificatorul entitatii sa ia valori unice diferite de NULL (NULL înseamna ca nu s-a atribuit nici o valoare).
În definirea modelului entitate-relatie se pot întâlni cazuri mai speciale legate de identificarea entitatilor:
nu se poate defini un identificator sub forma unui atribut/grup de atribute pentru un anumit tip de entitate;
Tipul de entitate Prezenta are rolul de a retine informatia privitoare la prezenta fiecarui angajat. Daca analizam multimea atributelor apartinând acestui tip de entitate constatam ca nu exista nici un atribut/grup de atribute care sa poata juca rol de identificator. Identificarea se realizeaza prin rolul Realizeaza pe care îl joaca tipul de entitate ANGAJAT în tipul de asociere înregistreaza.
![]()
![]()


|
Înregistreaza Luna |

![]()
![]()
![]()
![]()
![]()
Fig.2.43.
Identificarea prin rol a entitatilor se poate realiza doar daca asocierea în cauza nu este ciclica (unara) iar cardinalitatea cuplului entitate identificata-asociere este 1,1 iar cardinalitatea cuplului entitate identificator-asociere este 1,1 sau 0,1.
Identificarea unei entitati se poate realiza prin atributele proprii împreuna cu rolurile jucate de alte tipuri de entitati.
3. Restrictii de integritate pe roluri
Un rol, reprezinta o extremitate a unei asocieri. Asocierile binare au doua roluri, câte unul pentru fiecare clasa. Vom considera, clasele Personal si Companie. Exista o multime de asocieri posibile între aceste doua clase, în care instantele pot juca diferite roluri.
pentru Personal
angajat, manager, ofiter de securitate, programator, director
pentru Companie
angajeaza, membrul în consortiu, producator
![]()
![]()
![]() 1Angajati n 1
Compania
1Angajati n 1
Compania
![]()
n
![]() management functie nume asociat
management functie nume asociat
performanta salariu
Fig.2.44.
Plecând de la rolurile jucate de entitati în cadrul relatiilor putem defini o serie de restrictii de integritate si anume: de egalitate, incluziune si excluziune de roluri.
Restrictia de incluziune de roluri statueaza faptul ca daca o entitate joaca rolul R1 în relatia A1 atunci va trebui sa joace si rolul R2 în asocierea A2. Rezulta ca rolul R1 include (implica prin incluziune) rolul R2.
Restrictia de egalitate pe roluri - egalitatea presupune ca restrictia de incluziune între roluri sa fie reciproca.
Restrictia de excluziune de roluri - excluziunea de roluri specifica faptul ca un rol R1 jucat de o entitate E1 în relatia A1 exclude existenta rolului R2 jucat în relatia A2.
În ceea ce priveste modelul obiectual de organizare a datelor, desi importanta acestuia pentru viitorul bazelor de date este indiscutabila, nu exista un model unic, unanim recunoscut si utilizat, de baza de date obiectuala. Prin comparatie cu modelul relational, care este foarte bine fundamentat teoretic, se considera ca, de fapt, în ceea ce priveste "tehnologia" obiectuala, practica a luat-o înaintea teoriei. Este si neajunsul cel mai des invocat de catre partizanii "relationalului".
În fapt, modelele de baze de date obiectuale deriva din limbajele-obiect si modelele de date semantice. Acestea din urma, inspirate din retelele semantice specifice inteligentei artificiale, sunt rezultanta evolutiei modelelor de organizare a datelor, de la relational si "trecând" prin modelul entitati-asociatii. Obiectivul comun al acestor modele este de a îngloba întreaga semantica a datelor, inclusiv concepte ca entitate, identitatea entitatii, asociatie, agregare si generalizare. Bazele de date orientate pe obiecte trebuie sa permita manipularea de obiecte persistente, plecând de la un limbaj obiectual. O BDO reprezinta o organizare coerenta de obiecte persistente care sunt partajate simultan de mai multi utilizatori. Comparativ cu ceea ce, în mod clasic, reprezinta schema unei BD, schema unei BDO contine definitiile structurale (atribute si tipuri sau clase) si comportamentul (metodele) fiecarui obiect.
Modelele orientate pe înregistrari permit descrierea datelor la nivel logic si extern. Spre deosebire de cele obiectuale, sunt utilizate pentru reprezentarea atât a structurii logice a bazei, cât si a continutului (sau realizarii) acesteia. Din pacate, cea mai mare parte a modelelor din aceasta clasa nu permit specificarea tuturor restrictiilor pe care trebuie sa le îndeplineasca datele aflate în baza.
2.4.3. Modele conceptuale de nivel înalt
Se prezinta în figura 2.45. o descriere simplificata a procesului de constructie a unei baze de date. Asa cum se observa în figura un prim pas este cel al colectarii si analizei cererilor, etapa prin care proiectantul bazei de date prospecteaza utilizatorii în vederea stabilirii necesitatilor si documentarii asupra cererilor acestora. Rezultatul acestei etape este marcat de un set de cerinte clar formulate, într-o maniera concisa.
O data cererile formulate precis si concis se poate trece la elaborarea schemei conceptuale utilizând un model de nivel înalt. Schema conceptuala reprezinta o descriere concisa a datelor utilizatorului incluzând descrierea detaliata a tipurilor de date, a relatiilor si restrictiilor acestora. Deoarece pâna la acest moment nu se includ detalii de implementare, rezultatele pot fi comunicate utilizatorilor chiar daca sunt nespecializati în domeniu, si analizate de catre acestia, având ca obiectiv eliminarea eventualelor conflicte ce pot aparea.
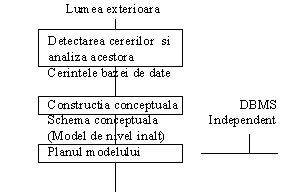
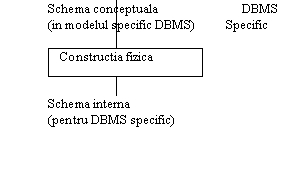
Fig. 2.45. Structura procesului de modelarea datelor
Urmatoarea etapa, cea de constructie a bazei de date tinând cont de detaliile actuale, cu ajutorul unui SBD comercial. Astfel se transforma modelul de nivel înalt într-un model de implementare. În final, prin constructia efectiva a bazei de date se specifica structura de stocare interna si organizarea fisierelor în baza de date.
Se dau mai jos cerintele pentru constructia unei baze de date aferenta unei companii, baza de date numita COMPANIE, ce are ca scop ilustrarea procesului descris. Pe parcursul acestui capitol aceasta va fi rafinata ajungându-se in final la modelul ER. În faza preliminara se cunoaste faptul ca Compania are un numar de angajati organizati pe departamente, si urmareste realizarea unor proiecte. Pentru simplitate, se presupune ca dupa analiza cerintelor s-a decis urmatoarea descriere, ca elemente primare, pentru baza de date:
Compania este organizata în departamente, fiecare departament are un nume, un numar de cod, un numar de angajati, putând avea mai multe sedii.
Un departament este implicat în mai multe proiecte, fiecare din ele are un nume, un numar de cod, si o singura locatie.
Se pastreaza pentru fiecare angajat numele, numarul de cod (social security number - ssn), adresa, salariul, sex, data de nastere. Orice angajat este afiliat la un departament, însa poate lucra la mai multe proiecte ce nu sunt neaparat coordonate de acelasi departament. Trebuie deci stocat si numarul de ore alocate saptamânal pentru fiecare proiect. De asemenea, fiecare angajat are un sef direct, numit si supervizor.
Lista persoanelor în întretinerea fiecarui angajat este importanta întrucât este utilizata la calculul impozitului, lista contine numele, sex, data nasterii.
Se remarca faptul ca o astfel de organizare este specifica pentru multe societati comerciale, însa acest model este utilizat doar pentru ilustrarea principiilor generale în utilizarea modelului entitate relatie cât si pentru operatii cu tabele de date.
În figura 2.46. se arata o entitate cu atributele ei.
e1=
e2=
Fig. 2.46. Exemple de entitati
Entitatea e1 reprezinta un angajat, o persoana fizica cu patru atribute, Nume, Adresa, Vârsta, Telefon.
Fiecare angajat este caracterizat de aceleasi atribute, dar fiecare entitate angajat va avea un set propriu de valori ce îl caracterizeaza. Entitatile ce sunt caracterizate de aceleasi atribute se numesc entitati tip. Pentru entitatea tip ANGAJAT având atributele Nume, Vârsta, Salariu, se dau mai jos ca exemplu doua entitati particulare.
e1(Popescu Vasile, 43, 3880)
e2(Dumitriu Petre, 32, 3240)
Descrierea atributelor entitatii tip este numita schema entitatii tip si specifica o structura comuna fixata a entitatilor de acelasi tip. Setul instantelor entitatilor individuale la un anumit moment este numita extensie a entitatii tip.
O entitate tip DEPARTAMENT având atributele Nume, Numar, Locatie (Sediu), Manager, Data de la care are aceasta functie. Pentru aceasta entitate atributele cheie pot fi fie Nume, fie Numar.
Entitatea tip PROIECT cu atributele Nume, Numar, Locatie, Departamentul ce coordoneaza proiectul, cu atribut cheie oricare dintre Nume sau Numar.
Entitatea tip ANGAJAT cu atributele Nume, SSN, Sex, Data nasterii, Adresa, Salariu, Departament si Supervizor. Atributele Nume si Adresa pot fi atribute compuse.
O entitate tip ÎNTRETINUT cu atributele Angajat, Nume, Sex, Data de nastere, Tip relatie (referitor la relatia dintre angajat si persoana aflata in întretinere).
În aceasta încercare de definire nu s-a tinut cont de faptul ca un angajat poate sa lucreze la mai multe proiecte, nu apare în acest caz indicat numarul de ore pe saptamâna alocate unui anumit proiect. Poate fi avut în vedere în cadrul entitatii ANGAJAT prin atributul compus Lucreaza_la ce ar avea componentele (Proiect,Ore). O alta alternativa poate fi introducerea unui atribut compus cu mai multe valori la entitatea PROIECT, atribut ce are componentele (Angajat, Ore). Se obtine astfel structura:
DEPARTAMENT
Nume, Numar, , Manager, Data_de_început
PROIECT
Nume, Numar, Locatie, Departament_coordonator
ANGAJAT
Nume(Nume, Initiala, Prenume), SSN, Sex, Adresa, Salariu, Data_nasterii, Departament, Supervizor,
INTRETINUT
Angajat, Nume_departament, Sex, Data_nasterii, Tip_relatie
În entitatile de mai sus atributele compuse s-au reprezentat Între paranteze rotunde, atributele ce pot lua mai multe valori între paranteze acolade. Este important sa existe un singur atribut cheie pentru fiecare entitate tip. În acest caz, formarea unui atribut cheie complex, este o indicatie ca entitatea poate fi sparta în mai multe entitati tip cu numar mai mic de atribute. Ori de câte ori un atribut al unei entitati indica o alta entitate se spune ca între cele doua entitati exista o relatie.
De exemplu relatia LUCREAZA_PENTRU între entitatile tip ANGAJAT si DEPARTAMENT asociaza fiecare angajat cu departamentul pentru care acesta lucreaza. În fig. 2.47. se ilustreaza un exemplu prin care se arata ca angajatii e1,e3 si e6 lucreaza pentru departamentul d1 si angajatii e2 si e4 lucreaza pentru departamentul d2.

Fig. 2.47. Relatii binare intre entitati
Se defineste rangul sau gradul unei relatii tip ca numarul entitatilor tip participante. Relatia din fig. 2.48. are rangul doi motiv pentru care se spune ca este o relatie binara. O relatie de rangul trei se zice ternara. O astfel de relatie ternara este cea din fig. 2.45. unde fiecare relatie instanta ri asociaza trei entitati s,p,j.

Fig. 2.48. Relatie de rang trei
Relatiile pot avea orice rang, si pot fi considerate ca fiind formate din mai multe relatii binare. Ca exemplu sa consideram relatia ternara din fig. 2.47. ce include instantele (s,p), (j,p) si (s,j). Cele trei relatii binare între proiectantii si partile unui proiect (instanta (s,p)), între proiect si parte (instanta (j,p)) si între proiectantii unei parti si proiect (instanta (s,j)) au fost reprezentate sub forma unei relatii ternare.
De multe ori este convenabil sa se considere relatia tip în termenii atributelor. Pentru relatia din fig. 2.47. se poate considera un atribut numit Departament al entitatii tip ANGAJAT ale carui valori pentru fiecare entitate angajat este entitatea departament la care angajatul lucreaza. Daca se considera o relatie binara ca un atribut, în particular pentru cea din fig. 2.47. se poate considera fie atributul multinivel Angajat al entitatii DEPARTAMENT, unde valorile pentru fiecare entitate departament contin setul de valori al entitatilor angajat care lucreaza pentru departamentul respectiv, fie un atribut multinivel Departament al entitatii ANGAJAT, unde valorile pentru fiecare entitate angajat contine setul de valori al entitatilor departament la care angajatul lucreaza.
Fiecare entitate tip ce participa într-o relatie tip joaca un rol particular în acea relatie. De exemplu în relatia LUCREAZA_LA entitatea ANGAJAT detine rolul angajatilor pe când entitatea DEPARTAMENT are rolul locului în care angajatii desfasoara activitatea. Este recomandabil ca numele relatiilor sa fie relevante, aceste nume sa indice pe cât posibil rolul jucat de entitati în relatie.
Daca relatia se stabileste între elementele aceleiasi entitati se spune ca s-a stabilit o relatie recursiva. Ca exemplu, relatia SUPERVIZOR se stabileste între angajati si supervizor, relatie în care ambii sunt membrii aceleiasi entitati. Ca exemplu în fig. 2.49. ce exemplifica relatia SUPERVIZOR liniile punctate reprezinta rolul de supervizor, pe când liniile pline reprezinta rolul de supervizat. Angajatul a1 supervizeaza angajatii a2 si a3, angajatul a4 supervizeaza angajatii a6 si a7 si angajatul a5 supervizeaza angajatii a1 si a4.

Fig. 2.49. Relatii între elementele aceleiasi entitati
Restrictiile limiteaza combinatiile posibile ale entitatilor participante intr-o relatie instanta. Pentru baza de date COMPANIE un angajat lucreaza la un singur departament. Se pot distinge doua tipuri de restrictii în relatii si anume restrictia de cardinalitate si cea de participare.
Restrictia de cardinalitate este marcata de numarul relatiilor instanta la care o entitate poate sa participe. Relatia binara LUCREAZA_PENTRU între entitatile DEPARTAMENT si ANGAJAT poseda o cardinalitate de 1:N aratând ca fiecare entitate departament poate fi în relatie cu mai multe entitati angajat fiindca mai multi angajati lucreaza la acelasi departament, pe când un angajat lucreaza într-un singur departament. Obisnuitele cardinalitati sunt 1:1, 1:N, M:N. Un exemplu de cardinalitate 1:1 este relatia binara intre DEPARTAMENT si ANGAJAT stabilita de MANAGER, pentru ca un departament are un singur manager si un manager conduce un singur departament.
Restrictia de participare specifica conditia de existenta a unei entitati în relatie cu o alta entitate cu care este în relatie. Pot exista restrictii de participare partiala sau totala. Daca într-o companie este statuat faptul ca fiecare angajat trebuie sa lucreze la un proiect, atunci acea entitate angajat poate sa existe numai daca este participanta la relatia LUCREAZA_PENTRU. Participarea este numita totala pentru ca fiecare entitate a entitatii tip ANGAJAT este în relatie cu entitatea DEPARTAMENT. Nu acelasi lucru se poate spune despre relatia MANAGER ca implica o participare partiala pentru ca nu toti angajatii unui departament sunt manageri.
Constructia modelului ER pentru baza de date COMPANIE
Se poate la acest moment rafina modelul datelor pentru baza de date COMPANIE, tinând cont de relatiile între entitati tip. Procesul este iterativ in sensul ca daca nu se pot stabili restrictiile structurale se poate relua iterativ procesul pâna la stabilirea completa. La acest exemplu au fost stabilite urmatoarele relatii:
MANAGER - o relatie 1:1 între entitatile tip ANGAJAT si DEPARTAMENT, cu o participare partiala a angajatilor. Participarea departament nu este clar stabilita. Utilizatorul a stabilit ca orice departament are la orice moment un manager ceea ce implica participare totala. Atributul Data de început este asignat la aceasta relatie tip.
LUCREAZA_PENTRU - este o relatie 1:N intre DEPARTAMENT si ANGAJAT, cu participare totala.
CONTROL - o relatie între DEPARTAMENT si PROIECT în care participarea entitatii PROIECT este totala, pe când cea a entitatii DEPARTAMENT este partiala.
SUPERVIZARE - o relatie 1:N între entitatea tip ANGAJAT si aceeasi entitate tip ANGAJAT. În aceasta relatie entitatile particulare joaca rol de supervizor, respectiv supervizat. Ambele participari sunt partiale întrucât nu toti angajatii pot fi supervizori, precum si faptul ca nu toti angajatii sunt supervizati.
LUCREAZA_LA - relatie M:N între entitatile ANGAJAT si PROIECT având atributul Ore, cu participare totala. La un proiect pot lucra mai multi angajati, însa un angajat poate lucra la mai multe proiecte.
INTRETINUT_ANGAJAT - relatie 1:N intre entitatile ANGAJAT si INTRETINUT având ca scop identificarea entitatii slabe INTRETINUT. Participarea este totala pentru întretinuti si partiala pentru angajati.
Odata specificate cele sase relatii se pot elimina atributele redondante, cum sunt pentru baza de date specificata Manager si Data_de_început în entitatea DEPARTAMENT, Departament_coordonator în entitatea PROIECT, Departament, Supervizor si Lucreaza_la de la ANGAJAT, respectiv Angajat de la INTRETINUT. Este foarte important ca redondanta sa fie foarte redusa la momentul constructiei schemei conceptuale. Proiectantul bazei de date trebuie sa se concentreze asupra specificarii structurilor de date si respectarii restrictiilor impuse de utilizatorii bazei de date, asigurând în aceste conditii un optim.
În figura 2.50. este reprezentata diagrama entitate relatie a bazei de date COMPANIE. Entitatile tip sunt reprezentate în dreptunghiuri, relatiile sunt reprezentate prin romburi legate de entitati. Pentru reprezentarea atributelor s-a folosit elipsa indiferent daca atributul este simplu sau compus. Pentru atributele cu mai multe valori s-a utilizat elipsa dublata. Atributele cheie au fost marcate prin subliniere, atributele derivate sunt marcate prin linie întrerupta. Entitatile slabe sunt puse în evidenta prin plasarea în dreptunghiuri cu linii duble, pe când relatia de identificare este plasata în romb cu linii duble. Pe aceeasi diagrama se reprezinta si restrictia de cardinalitate prin atasarea pe fiecare arc de legatura între entitati a cifrelor corespunzatoare.
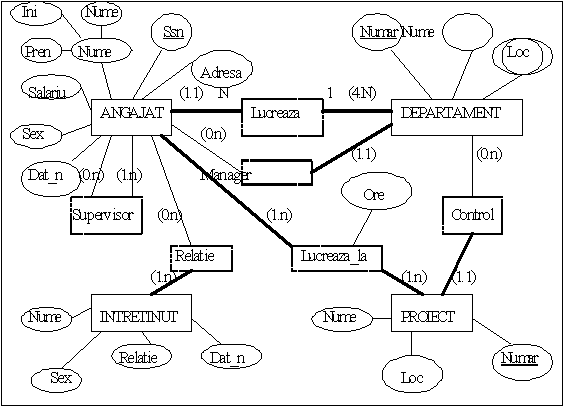
Fig. 2.50. Exemplu de model Entitate - Relatie
Restrictia structurala de participare este marcata prin linia de legatura dubla la participarea totala si cu linie simpla la participarea partiala. Este reprezentata si o relatie recursiva, cea de SUPERVIZOR. Perechile de numere asociate arcelor specifica restrictia de participare.
2.4.4. Dependentele functionale
Legaturile stabilite între entitatile bazei informationale permit continuarea analizei entitatilor în scopul stabilirii asocierilor dintre atributele componente prin intermediul dependentelor functionale care pot fi simple, multiple, izolate, duble, triple etc.
Dependenta functionala simpla dintre doua atribute este realizata daca în intervalul de existenta al bazei informationale o singura realizare a unuia dintre atribute permite o singura realizare a celuilalt. De exemplu, atributul codul materialului (COD-MAT) determina o singura realizare pentru atributul denumirea materialului (DEN-MAT), deoarece un material are un cod si o denumire unica.
Dependenta functionala multipla dintre doua atribute, este realizata daca în intervalul existent al bazei informationale o realizare a unuia dintre atribute determina mai multe realizari ale celuilalt atribut. De exemplu atributul cod sectie (COD-SECT) determina mai multe realizari pentru atributul codul atelierului (COD-ATEL), deoarece o sectie are mai multe ateliere.
În reprezentarea dependentelor functionale simple sau multiple pot fi utilizate combinatii ale acestora pentru evidentierea cât mai veridica a tuturor legaturilor dintre atribute.
Dependenta functionala izolata dintre atribute este realizata, daca în intervalul de existenta al bazei informationale o dependenta simpla sau multipla nu intra în combinatie cu alta dependenta, proprietate reflectata prin lipsa unor legaturi dintre atributele terminale ale dependentei.
Dependenta functionala dubla sau tripla dintre atribute este realizata prin intercombinarea a doua sau mai multe dependente functionale simple sau multiple. Rezulta ca dependenta este dubla daca se folosesc combinari ale altor doua dependente simple sau multiple si este tripla daca se folosesc trei tipuri de dependente.
Matricea dependentelor functionale
Matricea dependentelor functionale poate fi realizata în doua variante: simplificata si matricea completa.
Matricea simplificata reprezinta un tablou în care coloanele cuprind determinantii dependentelor functionale iar fiecare linie un atribut apartinând multimii atributelor supuse modelarii.
Matricea completa reprezinta un tablou asemanator matricei simplificate cu singura deosebire ca numarul de colane este egal cu numarul liniilor, cu alte cuvinte eticheta de coloana va fi orice atribut (regasit si ca o eticheta de linie) si nu doar atributele/grupurile de atribute cu rol de determinant într-o dependenta functionala.
De exemplu, daca luam un sistem informatic pentru calculatia costurilor, însa ne limitam datorita complexitatii problemei, la segmentul referitor la antecalcul si anume la determinarea consumurilor cu materiile prime si materialele pe comenzi. Ne propunem sa elaboram matricea simplificata a dependentelor functionale pentru atributele necesare elaborarii matricei complete privind consumul de materii prime si materiale, conform fisei tehnologice a produselor.
Multimea atributelor corespunzatoare problemei studiate este formata din: cod produs, denumire produs, cod um (cod unitate de masura), pret produs, cod reper, denumire reper, cantitate reper (în realizarea unui produs finit intra mai multe repere de acelasi fel sau diferite), cod material, denumire material, cantitate normata pe reper, denumire unitate de masura.
|
ATRIBUTE |
DETERMINANŢI |
|||||
|
1. Cod produs | ||||||
|
2. Denumire produs | ||||||
|
3. Cod um | ||||||
|
4. Pret produs | ||||||
|
5. Cod reper | ||||||
|
6. Denumire reper |
| |||||
|
7. Cantitate reper | ||||||
|
8. Cod material | ||||||
|
9. Denumire material | ||||||
|
10. Cantitate normata pe reper | ||||||
|
11. Denumire unitate de masura | ||||||
Fig.2.51. Matricea simplificata a dependentelor functionale
Analizând tabelul de mai sus, constatam ca fiecare coloana din matrice a fost rezervata unui determinant (se poate stabili anterior o lista a dependentelor functionale). Valoarea 1, la intersectia unei coloane cu o linie, marcheaza existenta unei dependente functionale între atributul determinat înscris la nivelul liniei.
Una din regulile modelului entitate-asociere specifica unicitatea atributelor adica, obligativitatea ca un atribut sa apartina unei singure entitati sau asocieri. Plasarea unui atribut într-o entitate sau alta este determinata de dependenta functionala la care participa în legatura cu identificatorul tipului de entitate. Aceasta înseamna ca în matricea dependentelor functionale, la nivelul fiecarei linii, va trebui sa fie înscrisa o singura valoare 1. În mod distinct, prin subliniere, în cadrul matricei au fost marcate câteva valori 1, care exprima proprietatea de reflexivitate a dependentelor functionale si sunt marcate la intersectia coloanei cu linia corespunzatoare acelorasi atribute (în cazul nostru determinantii). Existenta mai multor valori 1 pe o linie poate fi consecinta unor dependente functionale pure tranzitive care pun în evidenta asocieri ierarhice (numite si restrictii de integritate functionala) între entitatile ale caror identificatori sunt în dependenta functionala.
Matricea completa a dependentelor functionale
În cazul matricei complete numarul de coloane corespunde cu numarul liniilor.
|
ATRIBUTE |
DETERMINANŢI |
||||||||||||
|
1. Cod produs | |||||||||||||
|
2. Denumire produs | |||||||||||||
|
3. Cod um | |||||||||||||
|
4. Pret produs | |||||||||||||
|
5. Cod reper | |||||||||||||
|
6. Denumire reper | |||||||||||||
|
7. Cantitate reper | |||||||||||||
|
8. Cod material | |||||||||||||
|
9. Denumire material | |||||||||||||
|
10. Cantitate normata pe reper | |||||||||||||
|
11. Denumire unitate de masura | |||||||||||||
Fig.2.52. Matricea completa a dependentelor functionale
Din analiza matricei complete a dependentelor functionale constatam existenta:
diagonalei de valori 1 care este rezultanta proprietatii de reflexivitate a dependentelor functionale;
dependentelor elementare (prezentând un determinant elementar, un atribut);
dependentelor neelementare al caror determinant este format dintr-un grup de atribute în cazul nostru: cod produs, cod-reper, si cod reper, cod material.
dependentelor tranzitive (cod produs cod material, deoarece cod produs cod reper si cod reper cod material) si multivaloare (cod produs cod reper, cod reper cod material, un produs este format din mai multe repere, iar un reper presupune utilizarea mai multor materiale la realizarea lui) care conduc la aparitia mai multor valori 1 în cadrul liniilor matricei.
Analiza informatiei din matrice (completa sau simplificata) va conduce la definirea unor tipuri de entitati optimizate în cadrul carora sa fie eliminate dependentele functionale complexe. O solutie de definire a tipurilor de entitati, plecând de la identificarea dependentelor functionale, este reprezentata de diagrama dependentelor.
Diagrama dependentelor functionale
Diagrama dependentelor functionale reprezinta un graf construit plecând de la dependentele functionale identificate, pe baza caruia se pot defini tipurile de entitati ale modelului entitate-relatie, astfel încât în cadrul acestora sa nu se mai manifeste dependente functionale complexe.
Cvasidependentele functionale sunt cele pentru care cunoasterea unei valori pentru determinant nu antreneaza sistematic cunoasterea unei valori a determinatului. De multe ori aceste cvasi dependente functionale sunt reciproce (asa cum este cazul dependentei dintre codul produsului si codul reperului).
![]() COD PRODUS COD
REPER
COD PRODUS COD
REPER
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
Fig. 2.53. Graf al dependentelor functionale
Un produs este format din mai multe repere, dar si un anumit reper participa la realizarea mai multor produse.
Un graf al dependentelor functionale pune în evidenta dependente functionale tranzitive, astfel dependenta tranzitiva df3 va trebui eliminata.
Studiul diagramei dependentelor functionale permite identificarea cu usurinta a urmatoarelor:
determinantii dependentelor functionale;
cvasi dependentele functionale
dependentele functionale prezentând determinantul format dintr-un grup de atribute.
Trecerea de la diagrama dependentelor functionale la modelul entitate-asociere se realizeaza pe baza urmatoarelor reguli:
R1. Pentru fiecare dependenta functionala în care determinantul este elementar se creeaza un tip de entitate în care determinantul df joaca rolul de identificator.
Exemplu:
COD-PRODUS PREŢLIVRARE
Rezulta ca se va defini un tip de entitate, numit PRODUS, în care COD PRODUS va avea rol de identificator. Pentru exemplu luat anterior, si aplicând prima regula, vom avea:




![]()
![]()
![]()
![]()
Fig. 2.54.Tipuri de entitati definite
R2. Toate atributele participând la dependentele functionale care prezinta acelasi determinant se vor grupa în cadrul aceluiasi tip de entitate prezentând drept identificator atributul cu rol de determinant în cadrul dependentelor functionale.
În urma aplicarii acestei reguli, obtinem:
![]()
![]()
![]()
![]()




Fig. 2.55.Gruparea atributelor în tipuri de entitati
R3. Fiecarei dependenta functionala între identificatorii tipurilor de entitati îi va corespunde în modelul entitate-relatie un tip de asociere. Aceasta asociere este ierarhica (restrictie de integritate functionala) când cardinalitatea maximala pentru cuplul E1A este 1 si pentru cuplul E2A este n.
Aplicând aceasta regula obtinem fig.2.56.



![]()
![]()
![]()
|
Are |
![]()
![]()
|
Masurat |

|
Prezinta |

![]()
![]()
Fig. 2.56. Definirea tipurilor de asocieri
R4. Pentru fiecare dependenta functionala ne-elementara (cu determinantul format dintr-un grup de atribute, identificatorii în cadrul tipurilor de entitati definite) se creeaza un tip de asociere neierarhic (restrictie de integritate multipla) definita prin atributul cu rol de determinant în dependenta functionala.
Aplicând regula R4 obtinem fig.2.57.

|
Consum Cantitate |

![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
|
Format Cant reper |

![]()
![]()
|
Prezinta |

Fig.2.57. Modelul entitate-asociatie
Reguli de verificare si normalizare a modelarii conceptuale a datelor
A. Reguli de verificare a modelarii conceptuale a datelor
Realizarea modelului conceptual al datelor presupune respectarea anumitor reguli:
Regula de unicitate a numelor se aplica tuturor elementelor care participa la definirea modelarii conceptuale a datelor: tipuri de entitati, tipuri de asocieri, atribute roluri.Aceasta regula impune eliminarea omonimelor si sinonimelor din cadrul modelului. Nu trebuie sa existe elemente diferite care sa poarte acelasi nume sau doua nume diferite sa fie atribuite aceluiasi element.
Regula unicitatii atributelor (neredondantei) impune ca un atribut sa nu participe decât la definirea unui tip de entitate sau a unui tip de asociere.
Matricea dependentelor functionale semnaleaza când aceasta regula este încalcata (în afara determinantilor);
Regula de unicitate a asocierilor: pentru fiecare realizare a asocierii nu poate sa existe decât o singura realizare a fiecarei entitati participante la asociere si invers;
Regula proprietatilor si determinantului unei entitati: daca un atribut depinde de mai multi determinanti, acestia din urma reprezentând identificatorii mai multor tipuri de entitati, atunci el trebuie sa defineasca tipul de asociere dintre aceste tipuri de entitati;
Atributele derivabile se caracterizeaza prin faptul ca realizarile lor s-au obtinut prin algoritmi de calcul pe baza altor atribute. Se recomanda ca în modelarea conceptuala a datelor sa nu se regaseasca atribute calculate.
Atributele decompozabile pot fi mentinute în modelarii conceptuale a datelor daca prelucrarile nu impun descompunerea lor pe componente elementare. (adresa)
Minimizarea identificatorilor tipurilor de entitati este o regula aplicabila în cazul identificatorilor compusi (formati dintr-un grup de atribute) si urmareste eliminarea dependentelor partiale (un atribut al tipului de entitate este determinat de o parte a identificatorului).
Valoarea NULL prezentata de atribute care nu au un rol de identificator în cadrul entitatii (atribute cu realizari optionale) conduc la ideea rafinarii modelarii conceptuale a datelor prin definirea unor subtipuri de entitati care sa cuprinda doar atribute specifice acestuia. Atributele cu rol de identificator al entitatilor trebuie sa prezinte valori unice si nenule.
Reguli de normalizare
Normalizarea vizeaza atributele apartinând entitatilor pe care le analizeaza cu scopul eliminarii anomaliilor, reducerii redundantelor si definirii unor tipuri de entitati libere de dependentele functionale tranzitive si multivaloare. Prin analiza la nivelul entitatilor definite de modelul entitate-asociatie, procesul normalizarii conduce la definirea de tipuri de entitati suplimentare sau la modificarea unora deja definite.
Teoria normalizarii este fundamentata pe conceptul de forma normala definita drept stadiu de optimizare a tipurilor de entitati definite. Normalizarea se realizeaza prin parcurgerea succesiva a mai multor forme normale (FN) fiecare FN conservând cerintele formulate de FN precedenta.
Procesul normalizarii se poate desfasura în doua abordari:
Varianta top-down, caracterizata prin urmarirea respectarii formelor normale la nivelul entitatilor;
Varianta bottom-up caracterizata prin definirea unui tip de entitate unic înglobând toate atributele modelului entitate-relatie la nivelul caruia sa se identifice multimea dependentelor functionale existente între atribute - este mai putin aplicata în practica, fiind mult mai laborioasa.
Nu vom aborda aici, în detaliu, metodologia de normalizare a unei baze de date relationale (tehnica normalizarii tabelelor), ci o vom prezenta doar la nivel principial. Vom folosi pentru exemplificare o baza de date în care se doreste memorarea facturilor emise si primite de o unitate economica.
O factura însoteste actul de vânzare-cumparare a unuia sau mai multor articole (produse sau servicii), si este compusa dintr-un antet, care contine date referitoare la actul de vânzare în ansamblul sau (date despre vânzator si cumparator, data calendaristica când se face vânzarea, numarul de înregistrare al facturii etc.), si dintr-o sectiune în care sunt descrise articolele (produsele) ce fac obiectul vânzarii (denumirea, cantitatea si pretul unitar, TVA-ul etc.). Numarul de articole vândute printr-o singura factura difera de la caz la caz, fiind variabil de la o factura la alta.
Furnizor........................... Cumparator...........................
.............. (den., forma jurid.)............ (den., forma jurid.)...............
Nr.ord.registru com........... Nr.ord.registru com.............
Localitatea......................... Localitatea...........................
Judetul.......... ..... ...... Judetul.......... ..... ...... ..
Contul.......... ..... ...... . Contul.......... ..... ...... ...
Banca.......... ..... ...... .. Banca.......... ..... ...... ....
FACTURA Seria FE Nr. 408768
Nr.factura.......... ..... ...... ................. Data (zi, luna, an).......... ..... ...... ..... Nr.aviz însotire marfa..............................
|
Nr. Crt. |
Denumirea produselor sau serviciilor |
U/M |
Cantitate |
Pret unitar |
Valoare lei |
Valoare TVA lei |
Valoare factura |
||
|
0 |
2 |
|
4 |
5 |
6 |
7 |
|||
|
Semnatura si stampila Furnizorului |
Date privind expeditia Numele delegatului.......... ..... ...... ..... Mijlocul de transport..................... Nr. ............................. Expedierea s-a facut la Data de............ ora................... Semnaturile.......... |
TOTAL Semnatura de primire |
|||||||
|
|||||||||
Vom propune pentru început o structura a bazei de date FACTURI, formata dintr-o singura tabela, cu urmatoarea structura:
|
FACTURI |
|||||
|
Numar factura |
Data |
Seria |
Vânzator |
Cumparator (denumire,cod fiscal,cont, banca) |
Mijloc de Transport |
Observam ca fiecare factura este identificata printr-un cod numeric (numarul facturii), care pentru a putea fi folosit pe post de cheie primara a tabelei, trebuie sa fie unic în cadrul bazei de date - câmpul a fost subliniat, pentru a pune în evidenta aceasta functie a sa. În structura de mai sus nu a fost detaliata partea referitoare la articolele facturii.
Aducerea bazei de date la prima forma normala (FN1)
Fiecare entitate trebuie sa prezinte un identificator prezentând valori unice nenule.
Pentru a trece o baza de date la prima forma normala - FN1 trebuie eliminate câmpurile compuse (sau neatomice) si cele repetitive. Primul tip de câmpuri, cele compuse, este format din acele câmpuri care reprezinta o concatenare a mai multor valori. În exemplul de mai sus câmpul Vânzator (la fel ca si Cumparator) reprezinta de fapt o concatenare a mai multor câmpuri simple: codul vânzatorului, denumirea, codul sau fiscal, contul si banca.
Câmpul vânzator, fiind unul compus, se va sparge în mai multe câmpuri elementare, astfel:
FACTURI |
|||||||||
|
Numar factura |
Data |
Seria |
Cod Vânza-tor |
DenumireVânzator |
Cod fiscal vânza-tor |
Cont vânza-tor |
Banca vânzator |
Cod cumpa-rator | |
|
.... |
.... |
....... |
|
...... |
...... |
....... | |||
Cel de-al doilea tip de câmpuri care trebuie prelucrate în aceasta etapa (cea de trecere la prima forma normala) este cel al câmpurilor repetitive. Acestea descriu acelasi tip de entitati, numarul fiind însa variabil. Pentru a pune în evidenta câmpurile repetitive sa detaliem structura tabelei FACTURI, în sectiunea referitoare la articolele facturilor:
|
FACTURI |
||||||||||
|
Numar factura |
Articol 1 |
Articol 2 |
Articol 3 |
|||||||
|
Cod |
Denumire |
Unitate masura |
Cantitate |
Cod |
Cod | |||||
|
.. | ||||||||||
Se observa în structura de mai sus cum într-o înregistrare a tabelei FACTURI (în care este memorata complet o singura factura) sunt memorate date referitoare la trei articole. Prin urmare o factura memorata în aceasta baza de date poate contine maxim trei articole, ceea ce reprezinta pentru utilizator o serioasa limitare. Am putea mari acest numar la, sa zicem 20. Acum numarul de articole poate satisface un contabil nepretentios, dar ce se întâmpla daca majoritatea facturilor contin unul sau doua articole, în acest caz, majoritatea înregistrarilor bazei de date vor contine 18 sau 19 articole necompletate, ceea ce constituie o mare risipa de spatiu de memorare.
Câmpurile Articol 1, Articol 2, Articol 3 puse în evidenta în exemplul ales, reprezinta câmpuri repetitive. Ele trebuie eliminate din baza de date, operatie care se face astfel: se introduce în baza de date un singur asemenea câmp, o factura urmând a se întinde acum pe mai multe înregistrari ale tabelei (atâtea înregistrari câte articole are factura). Pentru a tine evidenta articolelor din cadrul unei facturi vom introduce în tabela un nou câmp, pe care îl vom denumi: Numar articol.
Noua structura a bazei de date Facturi va fi urmatoarea:
|
FACTURI | |||||||||
|
Numar factura |
Data |
Seria |
Cod vânzator |
Denumire vânzator |
Nr articol |
Cod art |
Denumire articol | ||
|
........ |
..... |
...... |
....... |
|
...... |
| |||
Observam în structura de mai sus, ca, pentru identificarea unei înregistrari din tabela, se folosesc doua câmpuri: numarul facturii si numarul articolului din cadrul acesteia. Prin urmare, noua cheie a tabelei va fi construita prin concatenarea celor doua câmpuri (subliniate în structura de mai sus).
Aducerea bazei de date la a doua forma normala (FN2)- toate atributele entitatii, altele decât identificatorul, trebuie sa fie în dependenta functionala completa si directa cu identificatorul entitatii.
Odata baza de date adusa la prima forma normala, se trece la urmatoarea etapa de optimizare (normalizare), cea de aducere la a doua forma normala FN2. Aceasta a doua forma a bazei de date se caracterizeaza prin faptul ca nu contine dependente functionale partiale, ceea ce înseamna ca toate câmpurile tabelei depind doar de cheia primara a acesteia (nu de parti ale ei).
Odata operate schimbarile anterioare, în tabela FACTURI se obtin o serie de anomalii, ce trebuie eliminate. Sa observam câmpul Data (si alte câmpuri din antetul facturii), care nu depind biunivoc de noua cheie primara a tabelei, formata din câmpurile Numar factura si Numar articol, ci doar de o parte a acesteia, adica de câmpul Numar factura. Acesta este un exemplu de dependenta functionala partiala, ce trebuie eliminata din tabela, pentru ca aceasta sa fie în FN2.
Solutia este mutarea câmpurilor care formeaza antetul facturii (care depind doar de Numar factura). Noile tabele le vom numi ANTET si ARTICOLE, pastrând numele de FACTURI pentru întreaga baza de date.
|
ANTET |
||||
|
|
Data |
Seria |
Cod vânzator | |
|
ARTICOLE |
|||
|
|
Numar articol |
Cod articol | |
|
..... | |||
Fiecare factura va fi memorata în baza de date (care acum este compusa din tabele) printr-o singura înregistrare în tabela ANTET si una sau mai multe înregistrari în tabela ARTICOLE (atâtea înregistrari câte articole contine factura). Legatura dintre cele doua tabele este realizata printr-un câmp comun, Numar factura.
Observam de asemenea, cheile celor doua tabele: Numar factura în tabela ANTET si combinatia Numar factura-Numar articol în tabela ARTICOLE.
Aducerea bazei de date la a treia forma normala (FN3) - toate atributele trebuie sa depinda complet de identificatorul asocierii (identificatorii entitatilor participante la asociere) iar fiecare atribut trebuie sa depinda de întregul identificator si nu de o parte a acestuia.
Forma normala trei, a unei baze de date se caracterizeaza prin aceea ca nu contine dependente functionale tranzitive. Aceste dependente se obtin atunci când un câmp X depinde de un alt câmp Y, care la rândul lui depinde de un altul Z. Aceste dependente din cadrul unei tabele trebuie eliminate, în caz contrar putând aparea o serie de anomalii nedorite.
Sa luam, de exemplu, câmpul Denumire vânzator, care depinde biunivoc de câmpul Cod vânzator (fiecare vânzator, identificat printr-un cod unic, are o denumire unica). La rândul lui câmpul Cod vânzator depinde biunivoc de câmpul cheie primara a tabelei ANTET, adica de câmpul Numar factura. Dar câmpul Denumire vânzator depinde direct si de câmpul Numar factura, deoarece fiecare factura are o singura denumire de vânzator.
Eliminarea acestei dependente se realizeaza prin construirea unei noi tabele folosita la memorarea datelor despre vânzatorii înscrisi pe facturi. Dar cum aceeasi situatie se întâlneste si în cazul datelor despre cumparatori, vom construi o tabela mai generala, în care vom introduce toti vânzatorii si cumparatorii, tabela pe care o vom denumi CLIENŢI. În aceasta tabela vom introduce toate câmpurile continând date despre clienti, împreuna cu codul acestora si cu cheia primara a tabelei din care au fost extrase aceste câmpuri (adica numar factura din tabele ANTET). În tabela ANTET ramâne Cod vânzator (si Cod cumparator), pentru a face astfel legatura dintre cele doua tabele.
Prin urmare vom avea urmatoarea structura a tabelei:
|
CLIENŢI |
||||||||
|
|
Denumire |
Cod fiscal | ||||||
| |
|
||||||||
|
|
Data |
Seria |
Cod vânz. |
Cod cump |
|
||||
|
|||||||||
|
ARTICOLE |
|||
|
Numar factura |
Numar articol |
Cod articol | |
Aceeasi problema apare si în cazul produselor din componenta articolelor, care sunt caracterizate de Cod, denumire si Unitate de masura. Câmpul Denumire (la fel si Unitate de masura) depinde de Cod articol, care la rândul lui depinde de cheia primara a tabelei ARTICOLE (combinatia dintre Numar factura si Numar articol). Prin urmare vom construi o noua tabela, numita PRODUSE, cu urmatoarea structura:
|
|
|
||||||||||||
|
|
|||||||||||||
|
|
|||||||||||||
|
ANTET |
|
|||||||||||||
|
|
|
|||||||||||||
|
||||||||||||||
|
PRODUSE |
|||||||||||||
|
|
Denumire |
U/M |
|||||||||||
| ||||||||||||||
|
ARTICOLE |
|
||||||||||||
|
Cod produs |
|
||||||||||||
|
|
|||||||||||||
În continuare, baza de date în FN3 mai poate fi optimizata, aducând-o în FN4 si FN5. Pentru aducerea unei tabele în FN4 este necesara eliminarea dependentelor multivaloare suplimentare (pentru o tabela este permisa numai una singura), iar FN5 implica lipsa dependentelor jonctiune. Nu vom intra aici în detaliile legate de aceste forme normale.
Concluzionând, putem spune ca am stabilit urmatoarea structura a bazei de date FACTURI:
tabela ANTET
Numar factura
Data
Seria
Cod vânzator
Cod cumparator
tabela ARTICOLE
Numar factura
Numar înregistrare
Cod produs
Cantitatea
tabela CLIENŢI
Cod client
Denumirea
Cod fiscal
Cont
Banca
Adresa
tabela PRODUSE
Cod produs
Denumire
Unitate de masura
![]()
|
EMIT Cant_cda |


MATERIAL COD_MAT DEN_MAT UM

![]()
![]()
![]()
![]()

|
CUPRINDE CANT-FACT PRET_FACT |


|
DETERMINĂ |

![]()



![]()
|
STINSĂ |

![]()
![]()
![]()
Fig.2.58. Modelul conceptual al datelor
Pentru un material se pot emite mai multe comenzi de aprovizionare. unei comenzi trimise furnizorului, îi pot corespunde 0 (comanda s-a trimis, dar furnizorul nu a livrat marfa), 1 (furnizorul a onorat comanda printr-o singura livrare) sau mai multe facturi (livrarea s-a realizat în transe). O factura este platita printr-un singur document (cec, ordin de plata, etc).
Regula 1. Fiecarei entitati îi este asociata schema unei relatii formata din toate atributele entitatii. Identificatorul entitatii devine cheie primara a relatiei.
Din analiza modelului entitate-relatie prezentat în figura de mai sus, rezulta ca vom defini patru relatii: MATERIAL, COMANDĂ, FACTURA, DOCUMENT.
MATERIAL = (COD_MAT, DEN_MAT, UM)
COMANDA = (NR_COMANDA, DATA_CDA, FURNIZOR)
FACTURA = (NR_FACT, DATA_FACT)
DOCUMENT = (NR_DOC, DATA_DOC, TIP_DOC, SUMA)
Regula2. Daca într-o asociere binara A, fiecarei entitati, prezentând cuplul entitate-relatie, îi este asociata o cardinalitate (0,1) sau (1,1), se adauga în schema relatiei R1 corespunzând entitatii E1 cheia primara a celeilalte relatii, R2 corespunzatoare entitatii E2 participante la asociere.
Vom analiza urmatorul exemplu:
![]()
![]()

|
A |
![]()
![]()
![]()
![]()
Fig.2.59. Asociere binara A
Prin aplicarea regulilor 1 si 2 putem obtine:
R1=(a,b,c,d)
unde atributul d reprezinta o cheie externa în relatia R1
R2=(d,e,f,g)
sau
R1= (a,b,c)
R2=(d,e,f,g,a)
unde a reprezinta o cheie externa în relatia R2
Cheia externa va trebui sa respecte restrictia de integritate referentiala, care cere ca o cheie externa apartinând unei relatii R sa prezinte aceleasi valori pe care acelasi atribut le are în relatia S unde are rolul de cheie primara.
În exemplul de mai sus, a doua regula vizeaza schemele relatiilor DOCUMENT si FACTURA care vor prezenta urmatoare forma:
FACTURA = (NR_FACT, DATA_FACT)
DOCUMENT = (NR_DOC, DATA_DOC, TIP_DOC, SUMA, NR_FACT)
Unde NR_FACT joaca în relatia DOCUMENT rol de cheie externa si va trebui sa respecte restrictia de integritate referentiala (valorile sale trebuie sa corespunda realizarilor pe care le prezinta în relatia FACTURA).
Regula 3. Daca într-o asociere A exista o singura entitate E pentru care cardinalitatea cuplului entitate asociere este egala cu (0,1) sau (1,1) se adauga în schema relatiei R1, ce corespunde entitatii E1 cheia primara a relatiei R2, care corespunde entitatii E2 participante la asociere.
Exemplu:
![]()
![]()
![]()
![]()
![]()
|
A |
![]()
![]()
Fig.2.60.
Prin aplicarea regulii 1 si 3 obtinem, relatiile:
R1 = (a,b,c,d)
R2 = (d,e,f,g)
Acest transport al cheii relatiei R2 în schema relatiei R1 (unde va juca rolul de cheie externa) este impus de rolul dominant al primei relatii asupra celei de a doua. Întotdeauna când între doua entitati se stabileste o asociere 1:n înseamna ca entitatea care prezinta pentru cuplul entitate-relatie cardinalitatea (1,n) este dominanta, iar cea de-a doua va fi considerata entitate "fiu" si va primi drept cheie externa cheia primara a entitatii "parinte", iar daca sunt definite atribute pentru asocierea A ele vor fi cuprinse în schema relatiei fiu.
În cazul concret pe care-l analizam regula trei priveste entitatile COMANDA si FACTURA dominanta fiind entitatea COMANDA deoarece prezinta cardinalitatea (0,n) pentru cuplul entitate relatie. Vom obtine astfel:
COMANDA = (NR_COMANDA, DATA_CDA, FURNIZOR)
FACTURA = (NR_FACT, DATA_FACT, NR_COMANDA)
Regula 4. Daca într-o asociere A nu exista nici o entitate E pentru care cardinalitatea cuplului entitate-relatie sa fie egala cu (0,1) sau (1,1) se va defini o a treia relatie cuprinzând în schema sa cheile primare ale celorlalte doua relatii (corespunzatoare entitatilor participante la asociere) împreuna cu toate atributele definite pentru asocierea A.
Exemplu:

|
A n,i |

![]()
![]()
Fig.2.61.
R1=(a,b,c)
R2=(d,e,f,g)
R3= (a,d,h,i)
În cazul aplicatiei considerate, regula patru se aplica entitatilor MATERIAL si COMANDA, pe de o parte, si MATERIAL si FACTURA, pe de alta parte. Vom obtine:
MATERIAL = (COD_MAT, DEN_MAT,UM)
COMANDA = (NR_COMANDA, DATA_CDA, FURNIZOR)
MATCOMANDAT = (COD_MAT, NR_COMANDA, CANT_CDA)
FACTURA = (NR_FACT, DATA_FACT, NR_COMANDA)
MATFACTURAT=(COD_MAT,NR_FACT, CANT_FACT, PRET_FACT)
Schema conceptuala a bazei de date relationale obtinute este în figura 2.62.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Fig.2.62. Schema conceptuala a bazei de date relationale
Probabil parcurgând regulile de trecere de la modelul conceptual al datelor la modelul logic (relational) al BDR se pune întrebarea cum se va rezolva problema unei entitati ciclice.

![]()
![]()
![]()
![]()
![]()
![]()
|
SUBSTITUŢIE CANTIT_SUBT |

![]()
![]()
Fig.2.63.
si în aceasta situatie se aplica tot regula 4 deoarece pentru nici unul din cuplurile entitate-relatie nu exista cardinalitati (1,1) sau (0,1). Rezultatul conversiei este reprezentat de tabele:
MATERIAL = (COD_MAT, DEN_MAT,UM)
MATSUBSTITUITE=(COD_MAT,COD_MAT_SUBSTITUIT, CANT_SUBSIT)
Unde COD_MAT_SUBSTITUIT ia valori în domeniul atributului COD_MAT.
O problema aparte o ridica definirea modelului logic al BDR plecând de la modelul entitate-asociatie care a integrat si conceptele de generalizare/specializare.
2.5. Proiectarea bazelor de date si dezvoltarea aplicatiilor în VisualFoxPro
VISUAL FOXPRO, aspecte generale
Visual PoxPro (VFP) este un SBD relational care detine un limbaj procedural propriu foarte puternic. Acest limbaj contine comenzi si functii care permit:
descrierea si manipularea datelor într-o baza de date relationala;
dezvoltarea procedurala a programelor de aplicatie;
programarea neprocedurala printr-un nucleu extins de SQL pe care-l suporta;
programarea orientata pe obiecte prin facilitatile vizuale.
Visual FoxPro contine, pe lânga facilitatile de programare, si o serie de generatoare, tot mai bune de la o versiune la alta, care ajuta la dezvoltarea rapida si eficienta a aplicatiilor cu baze de date.
O parte dintre comenzile si functiile din limbajul din Visual FoxPro vor fi prezentate în continuare, grupate dupa criteriul functional.
Limbajul contine putine reguli de sintaxa:
nu exista comenzi de început/sfârsit de program, iar programul nu este structurat pe sectiuni;
o comanda se poate scrie din orice coloana, singura pe o linie;
o comanda se poate continua pe linia urmatoare, utilizând caracterul punct si virgula (;) la sfârsitul liniei de continuat;
delimitator este spatiul (unul sau mai multe);
din numele unei comenzi, primele patru litere sunt obligatorii;
procedurile sunt de tip PROCEDURE sau FUNCTION si pot aparea în orice ordine, în acelasi fisier cu programul apelant sau în fisier separat.
Expresiile folosite în Visual FoxPro depind de natura operatorilor care apar: aritmetici (+, -, logici (AND, OR, NOT), de comparatie (<, >, <=, >=, <>, #, =), siruri de caractere (+, -, $).
Comentariul se introduce prin comanda NOTE sau caracterul * scris primul pe o linie de program, începând cu orice coloana sau doua caractere && pe o linie, dupa o comanda.
Reprezentarea datelor în memoria interna se face prin variabile simple (definite si declarate când apar într-o comanda de atribuire), tablouri cu maxim doua dimensiuni (declarate prin comanda DIMENSION sau DECLARE), constante (numerice, nenumerice, logice), clase de obiecte.
Reprezentarea datelor în memoria externa se face prin tabele relationale create de utilizator sau rezultate din aplicarea operatiilor relationale.
Încarcarea/actualizarea unui program se face cu editorul de texte Visual FoxPro apelat cu MODIFY COMMAND (sau cu orice alt editor de texte care produce fisier ASCII).
Executia unui program se face prin comanda DO care genereaza fisierul obiect tip FXP. Pentru generarea fisierului executabil (EXE) si apelul programului de sub sistemul de operare, fara a fi nevoie de produsul VFP, trebuie sa se utilizeze componenta de RUNTIME (cu optiunea STANDALONE) din Visual FoxPro.
Pentru informatii privind toate comenzile si functiile Visual FoxPro, precum si sintaxa, semantica si exemple referitoare la ele se va folosi comanda HELP.
Contextul curent de lucru în Visual FoxPro este dat de: calea (zona) de lucru curenta (ultima activata printr-o comanda SELECT), tabela curenta (ultima deschisa pe o cale prin comanda USE), înregistrarea curenta (ultima accesata într-o tabela).
2.5.2. Descrierea datelor
Prezentam acele comenzi din limbajul din Visual FoxPro care se folosesc pentru descrierea si definirea datelor (LDD - limbajul de descriere a datelor). Acestea, sunt comenzi cu un înalt grad de automatizare, usor de utilizat:
CREATE - creeaza structura de date a unei tabele. Rezulta un fisier tip DBF(DataBase File), în care se stocheaza structura si apoi datele. Se lucreaza într-o fereastra specifica.
CREATE TABLE - este o comanda din SQL cu aproximativ acelasi efect ca comanda CREATE. Se lucreaza însa prin linii de comanda si permite în plus specificarea restrictiilor de integritate din modelul relational, la momentul descrierii datelor.
CREATE DATABASE - creeaza o baza de date, care va contine mai multe tabele. Se poate astfel lucra explicit cu notiunea de baza de date. Rezulta un fisier tip DBC (DataBse Container).
MODIFY STRUCTURE - actualizeaza structura de date a unei tabele prin operatii de: adaugare, modificare, stergere de câmpuri.
ALTER TABLE - este o comanda din SQL cu aproximativ acelasi efect cu MODISTRU. Se lucreaza însa prin linii de comanda.
LIST/DISP STRUCTURE - afiseaza structura de date a unei tabele.
DBF () - furnizeaza numele tabelei deschise pe calea curenta.
2.5.3. Manipularea datelor
Principalele operatii de manipulare implementate în LMD (Limbajul de Manipulare a Datelor) sunt: accesul la date, actualizarea datelor, tehnicile de programare.
v Accesul la date - este una dintre operatiile cele mai utilizate ale unui SBD, vom grupa comenzile pe tipurile de acces suportate de Visual FoxPro.
Pregatirea accesului
USE - deschide o tabela, pregatita pentru orice tip de acces.
OPEN DATABASE - deschide o baza de date
CLOSE - închide tabele si alte fisiere Visual FoxPro, conform optiunilor specificate.
SELECT - activeaza o cale (zona) de lucru. Acestea sunt notate cu 1,2,. sau cu A, B,. Pe o cale, la un moment dat, poate fi deschisa o singura tabela.
INDEX - indexeaza o tabela dupa o singura cheie -fisier tip IDX (simpla - formata din unul sau multe câmpuri) sau dupa mai multe chei - fisier tip CDX (multiindexata). Rolul indexarii este de a permite ordonarea datelor si accesul direct la date.
REINDEX - reindexeaza o tabela dupa un criteriu stabilit la o indexare anterioara.
SET INDEX TO - activeaza unul din fisierele de index tip IDX, create anterior.
SPACE () - genereaza un sir de spatii.
Accesul tip secvential
LOCATE - cauta în acces secvential, prima înregistrare dintr-o tabela care îndeplineste o anumita conditie. Cautarea se face, întotdeauna, de la începutul tabelei.
CONTINUE - reia executia ultimei comenzi LOCATE anterioare, cautarea începând de la înregistrarea curenta.
Accesul prin numar de realizare
GO [TO] - pozitioneaza pointerul de înregistrare, pe înregistrarea cu numarul de ordine (realizare) specificat. Într-o tabela, înregistrarile sunt numerotate automat, de catre sistem, de la 1 (TOP) la câte sunt (BOTTOM).
SKIP - deplaseaza pointerul de înregistrare, începând de la înregistrarea curenta, cu un numar de înregistrari spre stânga (BOF) sau spre dreapta (EOF).
Accesul direct
SEEK - cauta direct prima înregistrare dintr-o tabela care are valoarea cheii de indexare egala cu o valoare specificata în comanda (printr-o expresie de orice tip).
FIND - la fel ca SEEK dar valoarea se poate specifica doar printr-o expresie tip caracter. Daca referirea se face printr-o variabila, aceasta este precedata de caracterul & (metadefinitie - referire indirecta).
v Vizualizarea
LIST - afiseaza înregistrari dintr-o tabela, conform unor criterii specificate. LIST simplu, afiseaza toate tuplurile din tabela curenta.
DISPLAY - la fel ca LIST dar, la afisarea pe ecran, când acesta este umplut se opreste defilarea automat. Reluarea se face apasând orice tasta. DISP simplu, afiseaza tuplul curent din tabela curenta.
v Functii utilizate la acces
STR () - transforma o valoare numerica într-un sir de caractere.
VAL () - transforma un sir de caractere într-o valoare numerica.
SUBSTR () - extrage dintr-un sir dat un numar de caractere.
RECCOUNT () - furnizeaza numarul de înregistrari dintr-o tabela.
RECNO () - furnizeaza numarul de ordine (realizare) al înregistrarii curente.
BOF () - începutul de fisier.
EOF () - sfârsitul de fisier.
FOUND () - indica daca în urma unui acces a fost gasita sau nu o înregistrare.
LOWER () - transforma literele mari în litere mici.
UPPER () - transforma literele mici în litere mari.
CHR () - furnizeaza caracterul al carui cod ASCII este indicat.
v Actualizarea datelor
Actualizarea presupune realizarea celor trei operatii: adaugare, modificare, stergere asupra înregistrarilor dintr-o tabela.
APPEND - adauga înregistrari la sfârsitul tabelei curente (ordinea înregistrarilor într-o tabela nu conteaza). Se lucreaza într-o fereastra specifica.
INSERT - insereaza o înregistrare între alte doua existente deja. Este mare consumatoare de resurse calculator.
INSERT SQL - comanda din SQL. Adauga la sfârsitul tabelei o înregistrare indicata prin comanda.
REPLACE - modifica înregistrari existente dintr-o tabela.
DELETE - sterge logic (marcheaza prin caracterul ) înregistrari dintr-o tabela.
RECALL - reface înregistrari sterse logic anterior.
PACK - sterge fizic toate înregistrarile sterse logic anterior.
ZAP - sterge fizic toate înregistrarile dintr-o tabela.
DELETED () - specifica daca înregistrarea curenta este stearsa logic.
SET DELETED - specifica daca înregistrarile sterse logic sunt disponibile sau nu pentru alte comenzi.
2.5.4. Tehnicile de programare
Limbajele din VFP implementeaza atât tehnicile de programare structurata (structurile fundamentale, modularizarea etc.) cât si programarea orientata obiect.
2.5.4.1. Structurile fundamentale de program
În Visual FoxPro exista comenzi specifice care permit implementarea celor trei structuri fundamentale de program din programarea structurata (procedurala): secventiala, alternativa, repetitiva.
![]() Structura secventiala
Structura secventiala
STORE
- comenzi de atribuire
? - scrie o linie pe ecran si trece cursorul pe linia urmatoare.
?? - scrie pe linia curenta.
@ . SAY / GET - scrie /citeste date pe/de la o coordonata a ecranului (comanda de
intrare/iesire standard)
READ - finalizeaza o comanda de citire @ . GET.
WAIT - suspenda executia cu posibilitatea de reluare.
Nota. Toate comenzile care nu fac parte din structurile alternative si repetitive, fac parte din structura secventiala.
![]() Structura alternativa
Structura alternativa
IF . ENDIF - structura alternativa simpla (cu doua ramuri).
CASE . ENDCASE - structura alternativa multipla (mai mult de doua ramuri).
![]() Structura repetitiva
Structura repetitiva
DO WHILE . ENDDO - structura repetitiva cu text initial.
FOR . ENDFOR - structura repetitiva cu text initial cu numarator.
SCAN . ENDSCAN - structura repetitiva specifica care permite accesarea automata a tuturor înregistrarilor dintr-o tabela.
2.5.4.2. Alte tehnici de programare structurata
![]() Modularizarea
Modularizarea
PROCEDURE . RETURN - permite construirea unei subrutine tip procedura.
FUNCTION . RETURN - permite construirea unei subrutine tip functie utilizator.
SET PROCEDURE TO - deschide un fisier de proceduri specificat.
![]() Meniuri
Meniuri
@ . PROMPT - defineste optiunile dintr-un meniu programat (cu bara de selectie - cu prompter).
MENU TO - numarul optiunii selectate dintr-un meniu programat (cu bara de selectie - cu prompter) este stocat într-o variabila.
DEFINE MENU - defineste un meniu orizontal prin comenzi specifice.
DEFINE PAD - defineste optiunile dintr-un meniu orizontal prin comenzi specifice.
ACTIVATE MENU - activeaza un meniu orizontal prin comenzi specifice (duce
cursorul pe meniu).
DEACTIVATE MENU - elibereaza cursorul de pe un meniu orizontal.
SHOW MENU - vizualizeaza pe ecran un meniu orizontal.
PAD () - functie alfanumerica ce contine numele optiunii selectate dintr-un meniu
orizontal prin comenzi specifice.
DEFINE POPUP - defineste un meniu vertical prin comenzi specifice.
DEFINE BAR - defineste optiunile dintr-un meniu vertical prin comenzi specifice.
ACTIVATE POPUP - activeaza un meniu vertical (duce cursorul pe meniu).
DEACTIVATE POPUP - elibereaza cursorul de pe meniul vertical.
SHOW POPUP - vizualizeaza pe ecran un meniu vertical.
BAR () - functie numerica ce contine numarul de ordine al optiunii selectate dintr-un
meniu vertical.
ON SELECTION - testeaza daca se lucreaza pe un meniu orizontal (MENU), pe
optiunile acestuia (PAD), pe un meniu vertical (POPUP), pe optiunile acestuia (BAR).
RELEASE - sterge din memorie meniuri sau optiuni.
![]() Ferestre
Ferestre
DEFINE WINDOW - defineste o fereastra în anumite conditii indicate prin clauze.
ACTIVATE WINDOW - activeaza o fereastra (cursorul e activ în fereastra).
DEACTIVATE WINDOW - elibereaza cursorul din fereastra.
SHOW WINDOW - vizualizeaza o fereastra.
RELEASE WINDOW - sterge din memorie o fereastra.
![]() Rapoarte
Rapoarte
SET RELATION - stabileste o legatura între doua sau mai multe tabele deschise pe cai diferite.
COPY TO - implementeaza operatorul relational de proiectie.
SELECT SQL - comanda din SQL care permite formularea cererilor de regasire
complexe. Implementeaza si operatorii relational de bazas selectia, proiectia,
jonctiunea, uniunea, diferenta, intersectia.
JOIN - implementeaza operatorul relational de jonctiune.
BROWSE - comanda complexa ce permite pentru o tabela: vizualizare, rasfoire,
actualizare, etc.
CHANGE - idem ca BROWSE dar aranjarea câmpurilor se face, pe ecran, invers (pe
verticala).
SUM - însumeaza câmpurile specificate dintr-o tabela.
Nota. Toate comenzile de citire/scriere contribuie la construirea rapoartelor, alaturi de multe altele (agregare, setari, etc.).
![]() Setari
Setari
Visual FoxPro contine un numar important de comenzi SET care permit programatorului sa modifice anumiti parametri stabiliti la instalarea sistemului. Prezentam câteva dintre aceste comenzi:
SET ALTERNATE - directioneaza iesirile standard realizate prin comanda ? spre un
fisier text.
SET COLOR - controleaza culorile utilizate sub Visual FoxPro.
SET CONSOLE - controleaza iesirile standard spre ecran.
SET DATE - controleaza formatul de afisare al datei calendaristice.
SET DEVICE - directioneaza iesirile standard realizate prin comenzi @ . SAY spre
un periferic dorit.
SET MESSAGE - directioneaza mesajele care vor fi afisate prin clauze specifice din
diferite comenzi.
SET SAFETY - protejeaza fisierele la suprascriere.
SET STATUS - controleaza afisarea unei linii de stare în partea inferioara a
ecranului.
SET TALK - controleaza afisarea unor mesaje pe ecran la executia unor anumite
comenzi
![]() Alte comenzi/functii
Alte comenzi/functii
AVERAGE - calculeaza media aritmetica.
BOF () - tasteaza începutul de fisier pentru o tabela.
CALCULATE - executa expresii aritmetice.
CLEAR - sterge tot ecranul.
COUNT - numara înregistrarile dintr-o tabela ce îndeplinesc o anumita conditie.
CTOD () - converteste sir de caractere în data calendaristica.
DATE () - furnizeaza data curenta din sistem.
DIMENSION () - declara un tablou cu maxim doua dimensiuni (idem DECLARE).
DO - apeleaza pentru executive un program sau procedura.
DTOC - converteste data calendaristica în sir de caractere.
EOF () - tasteaza sfârsitul de fisier pentru o tabela.
FILE () - tasteaza existenta unui fisier.
HELP - furnizeaza informatii despre comenzi/functii.
MODIFY COMMAND - apeleaza editorul de texte Visual FoxPro.
2.5.5. VFP obiectual
Începând cu versiunile de Visual, FoxPro trateaza obiecte în memoria interna si le salveaza în biblioteci. Facilitatile se refera la programarea vizuala (un caz particular de programare orientata obiect) destinata construirii unor interfete cu utilizatorul în mod rapid, eficient si prietenos. Prezentam, în continuare, câteva dintre comenzile si functiile sistemului.
DEFINE CLASS . ENDDEFINE - defineste o clasa de obiecte utilizator având ca baza (tip) una din clasele standard oferite de sistem (vizuale sau nonvizuale). La definirea clasei se descriu proprietatile aferente.
PROCEDURE/FUNCTION - descrie metode pentru o anumita clasa, care arata comportamentul obiectelor.
ADDOBJECT () - metoda care permite adaugarea unor obiecte la o clasa.
CREATEOBJECT () - metoda care creeaza un obiect pentru o clasa indicata.
CREATE CLASS - creeaza o noua clasa de obiecte cu utilizatorul CLASS
DESIGNER.
CREATE CLASSLIB - creaza o biblioteca de clase vizuale utilizator (. VCX).
MODIFY CLASS - actualizeaza o clasa de obiecte cu utilizatorul CLASS
DESIGNER.
ADD CLASS - adauga o clasa într-o biblioteca de clase (. VCX).
SHOW () - metoda care afiseaza pe ecran un obiect de tip Form.
READ EVENTS - citeste evenimente.
CLEAR EVENTS - sterge evenimente.
RELEASE - metoda care sterge o forma din memorie.
Nota. Sistemul VFP contine, referitor la programarea orientata obiect, o serie de elemente standard: clase, proprietati, metode, evenimente. Toate acestea, alaturi de comenzi si functii, sunt oferite programatorului spre utilizare. Informatii suplimentare se obtin în HELP.
2.5.6. Proiectarea unei baze de date
La organizarea unei BD trebuie urmarite câteva aspecte:
Organizarea intrarilor de date:
sursa datelor (documente primite, fisiere etc.);
actualizarea datelor (moduri, momente, reorganizari etc.);
controlul intrarilor de date (natura, continut, format, periodicitate etc.).
Organizarea memorarii datelor:
principii de memorare (memoria interna/externa, forma de stocare, legaturi între date etc.);
optimizarea memorarii (redundanta, spatiu, alocare, codificare, reorganizare etc.).
Organizarea protectiei datelor:
instrumente oferite de catre SBD (autorizare acces, fisiere jurnal, arhivari etc.);
metode proprii (parole, rutine speciale, antivirus etc.).
Organizarea legaturilor bazei de date cu alte aplicatii: conversii, standarde, compatibilitatii, interfete etc.
În realizarea unei baze de date trebuie realizate urmatoarele obiective:
![]() Partitionarea: aceleasi date
trebuie sa poata fi folosite în moduri diferite de catre
diferiti utilizatori.
Partitionarea: aceleasi date
trebuie sa poata fi folosite în moduri diferite de catre
diferiti utilizatori.
![]() Deschiderea: datele trebuie
sa fie usor adaptabile la schimbari (actualizarea structurii,
tipuri noi de date etc.).
Deschiderea: datele trebuie
sa fie usor adaptabile la schimbari (actualizarea structurii,
tipuri noi de date etc.).
![]() Eficienta: stocarea si
prelucrarea datelor trebuie sa se faca la costuri cât mai
scazute, care sa fie inferioare beneficiilor obtinute.
Eficienta: stocarea si
prelucrarea datelor trebuie sa se faca la costuri cât mai
scazute, care sa fie inferioare beneficiilor obtinute.
![]() Reutilizarea: fondul de date
existent trebuie sa poata fi reutilizat în diferite aplicatii
informatice.
Reutilizarea: fondul de date
existent trebuie sa poata fi reutilizat în diferite aplicatii
informatice.
![]() Regasirea: cererile de
regasire trebuie sa poata fi adresate usor de catre
toate categoriile de utilizatori, dupa diferite criterii,
Regasirea: cererile de
regasire trebuie sa poata fi adresate usor de catre
toate categoriile de utilizatori, dupa diferite criterii,
![]() Accesul: datele trebuie
sa poata fi localizate prin diferite moduri de acces, rapid si
usor.
Accesul: datele trebuie
sa poata fi localizate prin diferite moduri de acces, rapid si
usor.
![]() Modularizarea: realizarea BD
trebuie sa se poata face modular pentru generalitate si
posibilitatea lucrului în echipa.
Modularizarea: realizarea BD
trebuie sa se poata face modular pentru generalitate si
posibilitatea lucrului în echipa.
![]() Protectia: trebuie asigurate
securitatea si integritatea datelor.
Protectia: trebuie asigurate
securitatea si integritatea datelor.
![]() Redundanta: prin implementarea
unui model de date pentru baze de date si prin utilizarea unei tehnici de
proiectare a BD se asigura o redundanta minima si
controlata.
Redundanta: prin implementarea
unui model de date pentru baze de date si prin utilizarea unei tehnici de
proiectare a BD se asigura o redundanta minima si
controlata.
![]() Independenta
datelor fata de programe la nivelurile logic si fizic.
Independenta
datelor fata de programe la nivelurile logic si fizic.
În metodologia de realizare a BD se parcurg, în cea mai mare parte, cam aceleasi etape ca la realizarea unui sistem informatic, cu o serie de aspecte specifice.
Activitatile (etapele) parcurse pentru realizarea unei BD (fig. 2.61.):
A. Analiza de sistem
Scopul acestei activitati este de a evidentia cerintele aplicatiei si resursele utilizate (studiul), precum si de a evalua aceste cerinte prin modelare (analiza).
STUDIUL situatiei existente se realizeaza prin:
definirea caracteristicilor generale ale unitatii;
identificarea activitatilor desfasurate;
identificarea resurselor existente (informationale, umane, echipamente, financiare etc.);
identificarea necesitatilor de prelucrare.
ANALIZA sistemului existent urmeaza investigarii (studiului) si utilizeaza informatiile obtinute de aceasta.
Analiza este o activitate de modelare (conceptuala) si se realizeaza sub trei aspecte: structural, dinamic si functional.
Fig.2.65. O clasificare a limbajelor relationale
Exista o serie de caracteristici comune tuturor limbajelor: operatorii relationali $e aplica relatiilor luate în întregime, adica tuturor cuplurilor care alcatuiesc relatiile respective; rezultatul fiecarui operator (rezultatul consultarii) este o noua relatie ce poate servi ca argument într-o alta consultare s.a.m.d.; logica operatorilor se bazeaza pe valorile atributelor, ceea ce constituie de altminteri suportul singurului mod de acces în BD. întrucât consultarile mono- si multi-relatii sunt efectuate exclusiv prin compararea valorilor atributelor (definite pe domenii compatibile), accesul total independent de limbaj este asigurat.
naintea redactarii unei consultari într-un limbaj relational trebuie parcursa o faza de analka, pentru determinarea atributelor rezultatului, legaturilor dintre tabele si eventualelor conditii (restrictii) ce trebuie respectate.
Limbajul algebric relational cuprinde doua tipuri de operatori: ansamblisti - REUNIUNE, INTERSECŢIE, DIFERENŢĂ, PRODUS CARTEZIAN - si relationali - SELECŢIE, PROIECŢIE, JONCŢIUNE si DIVIZIUNE.
O alta clasificare distinge operatorii fundamentali, ireductibili (reuniunea, diferenta, produsul cartezian, selectia, proiectia) de cei derivati, a caror functionalitate poate fi realizata prin combinarea operatorilor fundamentali (intersectia, jonctiunea, diviziunea).
Algebra, ca si calculul relational, serveste ca punct de referinta în caracterizarea unui limbaj ca fiind complet sau incomplet, din punct de vedere relational. Daca un limbaj permite exprimarea tuturor operatorilor enumerati mai sus si ofera cel putin facilitatile algebrei relationale, se spune ca acesta este un limbaj relational complet.
2.6.2. SQL
Probabil cea mai vehiculata sintagma în lumea celor implicati în aplicatii cu baze de date este SQL. Fundamentat în anii '70, consacrat în anii '80 si celebru în anii '90, astazi SQL (Structured Query Language) constituie axul central al oricarui SGBD. Importanta sa rezulta atât din faptul ca este accesibil profesionistilor si amatorilor, cât si datorita faptului ca este standardizat. Cele mai importante stadarde SQL au fost elaborate în anii 1989, 1992 si 1999, SQL-89 (SQL1), SQL-92 (SQL2) si SQL:1999[19]. Cel mai recent, SQL:1999, publicat în cea mai mare parte în iulie 1999, este de o complexitate superioara fata de precedesori, sugerata si de numarul de pagini, aproape 2.000 (fata de 600 ale SQL-92). Scadenta finalizarii sale a fost repetat amânata.
Desi este referit, în primul rând, ca un limbaj de interogare, SQL este muit mai mult decât un instrument de consultare a bazelor de date, deoarece permite, în egala masura: definirea datelor; consultarea BD; manipularea datelor din baza; controlul accesului; partajarea bazei între mai multi utilizatori ai acesteia; mentinerea intergritatii BD. Principalele comenzi ale SQL care se regasesc, într-o forma sau alta, în multe dintre SGBDR-urile actuale sunt:
Comanda Scop
Pentru manipularea datelor
SELECT Extragerea datelor din baza
INSERT Adaugarea de noi linii într-o tabela
DELETE stergerea de linii dintr-o tabela
UPDATE Modificarea valorilor unor atribute
Comanda Scop
Pentru definirea bazei de date
CREATE TABLE Adaugarea unei noi tabele în baza de date
DROP TABLE stergerea unei tabele din baza
ALTER TABLE Modificarea structurii unei tabele
CREATE VIEW Crearea unei tabele virtuale
DROP VIEW stergerea unei tabele virtuale
Pentru controlul accesului la BD
GRANT Acordarea unor drepturi pentru utilizatori
REVOKE Revocarea unor drepturi pentru utilizatori
Pentru controlul tranzactiilor
COMMIT Marcheaza sfârsitul unei tranzactii
ROLLBACK Abandoneaza tranzactia în curs
Dupa Groff si Weinberg, principalele atuuri ale SQL sunt[20]:
Independenta de producator, nefiind o tehnologie proprietara
Portabilitate între diferite sisteme de operare
Este standardizat
"Filosofia" sa se bazeaza pe modelul relational de organizare a datelor
Este un limbaj de nivel înalt, cu structura ce se apropie de limba engleza
Permite formularea de raspunsuri la numeroase interogari simple, ad-hoc, neprevazute initial
Constituie suportul programatic pentru accesul la BD
Permite multiple imagini asupra datelor bazei
Este un limbaj relational complet
Permite definirea dinamica a datelor, în sensul modificarii structurii bazei chiar în timp ce o parte din utilizatori sunt conectati la BD
Constituie un excelent suport pentru implementarea arhitecturilor client/server.
Ingredientele SQL: 1999 vizeaza transformarea acestuia într-un limbaj complet, în vederea definirii si gestionarii obiectelor complexe si persistente. Aceasta include: generalizare si specializare, mosteniri multiple, polimorfism, încapsulare, tipuri de date definite de utilizator, suport pentru sisteme bazate pe gestiunea cunostintelor, expresii privind interogari recursive si instrumente adecvate de administrare a datelor.
Se poate spune ca, o data cu standardul publicat în 1999, SQL iese din sfera relationalului si a normalizarii relatiilor, asa cum au fost formulate de Codd. în orice caz, SQL continua sa evolueze, iar organismele care-i guverneaza standardizarea sunt preocupate de întâmpinarea cerintelor pietei bazelor de date.
Interesant este ca printre detractorii SQL se numara nu numai aparatorii neînfricati ai tehnologiei obiectuale sau a datelor semistructurate (XML), ci chiar si partizanii relationalul "curat", precum C.J. Date, H. Darwen si Fabian Pascal[21], care îl considera o implementare incompleta a modelului relational.
Object Query Language - OQL (BDOO)
Object Query Language (OQL) este un limbaj de interogare orientat-obiect asemanator cu SQL, dezvoltat de o ramura a bine cunoscutului Object Management Group, si anume ODMG (Object Data Management Group). Acest nou limbaj de interogare poate fi utilizat fie direct, ca o functie într-un limbaj de programare orientat-obiect (C, C++, Smalltalk, Java), fie ca limbaj pentru crearea unor cereri ad-hoc.
Principiile de proiectare ce stau la baza OQL sunt urmatoarele[22]:
OQL este dezvoltat conform modelului obiectual propus de ODMG
OQL este un superset al SQL-ului standard. Ca urmare orice fraza select SQL functioneaza cu aceeasi sintaxa pe colectii de obiecte ODMG. Extensiile au fo vedere notiuni specifice orientate-obiect precum obiecte complexe, identitatea obiectului, polimorfism, invocarea operatiilor, legare întârziata etc.
OQL dispune de de primitive de înalt nivel pentru a gestiona seturile de obiecte si structurile de date complexe (liste, tablouri).
OQL poate fi invocat direct din limbajele de programare si poate la rândul lui invocai operatiuni programate în aceste limbaje.
OQL ofera posibilitatea accesului declarativ la obiecte, fapt pentru care interogarile pot fi usor optimizate.
OQL nu furnizeaza operatori de actualizare explicita a bazelor de date orientate-obiect. În schimb poate accesa în acest scop opearatii definite la nivelul obiectelor, o baza de date orientata obiect fiind prin definitie gestionata de metodele scrise la nivelul obiectelor.
Standardul ODMG-93 introduce urmatoarele elemente:
un set de clase generice predefinite ca suport pentru colectii de obiecte, astfel: Set<T>, Bag<T> (Set de elemente care se repeta), Varray<T> (tablou cu dimensiune variabila), List<T> (Tablou cu dimensiune variabila si posibilitate de inserare de elemente noi);
un obiect face referinta la altul prin Ref, acesta comportându-se ca un pointer C++ persistent ce este utilizat pentru implementarea relatiilor între obiecte si a restrictiilor referentiale. Combinând relatiile si colectiile putem defini destul de usor relatii de tip l:nsau m.n;
orice obiect sau colectie trebuie sa aiba un nume explicit.
Pornind de la aceasta baza de date putem prezenta prin câteva exemple aspectele esentiale ce diferentiaza OQL de SQL. Spre exemplu:
Select c.nume
from c in p.copii
va returna numele copiilor persoanei p.
Observam ca nu putem scrie p. copii.nume (asa cum am putea crede la prima vedere) deoarece atributul copii este o lista de referinte.
Daca am dori setul de adrese ale copiilor fiecarei persoane din baza de date ar trebui sa scriem o interogare OQL de genul:
select c.locuieste_in.cladire.adresa from p in Persoane, c in p.copii
Asa cum se observa, avem de-a face cu doua colectii: Persoane si Persoane:: copii, pe care le tratam la fel ca în SQL, în partea de FROM stiind ca în OQL o colectie poate fi derivata din una anterioara.
Bineînteles ca putem utiliza clauza where pentru a defini un predicat:
select c.locuieste_in.cladire.adresa
from p in Persoane, c in p.copii
where p.locuieste_in.cladire.adresa.strada= "BD. Carol 1" and count (p.copii) >= 2 and c. locuieste_in \-p.locuieste_in
Ca rezultat vom obtine adresele copiilor persoanelor de pe strada "Bd. Carol 1", care au cel putin doi copii care nu locuiesc în acelasi apartament ca si parintii lor. De asemenea putem construi subinterogari: daca dorim toate persoanele ce au acelasi nume cu al strazii, unde locuiesc:
select p
from p in Persoane, b in
(select distinct a.cladire from a in Apartmente)
where p.nume = b.adresa.strada
O diferenta majora între OQL si SQL consta în aceea ca un limbaj de interogare obiectual trebuie sa poata manipula valori complexe sau tipuri abstracte de date definite ad-hoc. în acest sens OQL utilizeaza constructorii struct, set, bag, list si array. Spre exemplu pentru a obtine adresele copiilor tuturor persoanelor alaturi de adresa fiecarei persoane, vom utiliza urmatoarea fraza OQL:
select struct (eu: p.nume,
adresa_mea: p.locuieste_in.cladire.adresa, copiii_mei
(select struct(
nume: c.nume,
adresa:c.locuieste_in.cladire.adresa)
from c in p.copii))
from p in Persoane
În OQL putem invoca metodele în acelasi mod în care invocam atributele obiectelor, iar acestea pot returna tipuri complexe de date.
Limbajul de interogare obiectual furnizeaza acces declarativ la baza de date obiect folosind o sintaxa asemanatoare SQL. însa nu asigura operatori de actualizare expliciti, lasând acest lucru în seama operatiilor definite asupra tipurilor de obiecte.
OQL se bazeaza atât pe accesul asociativ cât si pe cel navigational:
o interogare asociativa întoarce o colectie de obiecte. Modul cum aceste obiecte sunt localizate este responsabilitatea SGBO mai mult decât a aplicatiei;
o interogare navigationala acceseaza obiectele individuale, iar relatiile dintre obiecte sunt folosite pentru a naviga de la un obiect Ia un altul. Este responsabilitatea pro-gramului-aplicatie de a specifica procedura pentru accesul obiectelor cerute.
Evolutia dezvoltarii de aplicatii cu baze de date
Arhitectura Client/Server
În prezent, s-ar parea ca asistam la schimbarea paradigmei în dezvoltarea aplicatiilor, modelul client/server pare depasit, iar marile companii din industria software-ului ne ureaza "bun venit" în lumea aplicatiilor web. Adevarul (cel putin pentru aplicatiile cu baze de date) este probabil undeva la mijloc {middleware)...
"Client/Server a fost o imensa greseala. Ne pare rau ca v-am vândut asa ceva. În loc de aplicatii rulând pe statii si date stocate pe server, totul va fi bazat pe Internet. Tot ce va rula pe statii va fi un browser si un procesor de text. Oamenii vor un echipament simplu sii ieftin care sa functioneze ca o fereastra spre Net. PC-ul a fost de o complexitate absurda, cu rafturi de manuale si necesitând suport tehnic ca sa functioneze. S-a crezut ca tehnologia Client/Server va evita aceasta problema, dar a fost un pas într-o directie gresita. Acum ne platim din greu ignoranta", afirma Larry Ellison, CEO, Oracle Corp"[23].
Cu toata aciditatea unei asemenea declaratii, client/server este o tehnologie care a schimbat fundamental modul de abordare a aplicatiilor cu baze de date, fara sa mai vorbim de faptul ca tot ea sta la baza Internetului însusi. Termenul a fost utilizat pentru prima data în anii '80 cu referinta la PC-urile dintr-o retea, iar modelul actual a început sa câstige interesul specialistilor TI spre sfârsitul anilor '80.
Arhitectura client/server se constituie ca o infrastructura versatila, bazata pe mesaje si modulara, ce s-a nascut din intentia îmbunatatirii utilizabilitatii, flexibilitatii, interoperabiIitatii si scalabilitatii aplicatiilor software. Clientul este definit ca un solicitant de servicii, iar server-ul este definit ca un furnizor de servicii tinând seama de faptul ca una si aceeasi statie poate fi si client, si server în functie de configuratia software. Clientul si server-ul comunica prin schimb de mesaje.
Istoric vorbind, evolutia tehnologica de la sisteme centralizate spre client/server a trecut printr-o etapa intermediara numita arhitectura file/server. La originea lor, retelele de PC-uri se bazau pe descarcarea pe statia de lucru a fisierelor de pe server si efectuarea tuturor prelucrarilor locale. Problema de baza a unei asemenea arhitecturi era incapacitatea deservirii simultane a mai mult de 12 utilizatori.
Ca raspuns la limitarile conceptului file/server a aparut arhitectura client/server iar server-ul de fisiere a fost înlocuit de un server de baze de date ce are Ia baza un SBD dotat cu un proces suplimentar care "asculta" cererile clientilor si le raspunde în mod direct.
În general, clientii sunt calculatoare personale (PC-uri) utilizate pentru activitati de gestionare a datelor. Dupa Sinha[24], un post client se caracterizeaza prin faptul ca:
prezinta o interfata utilizator, care e, de obicei, grafica (GUI);
"formuleaza" interogari (cereri, consultari) sau comenzi pe care le "înainteaza" server-ului;
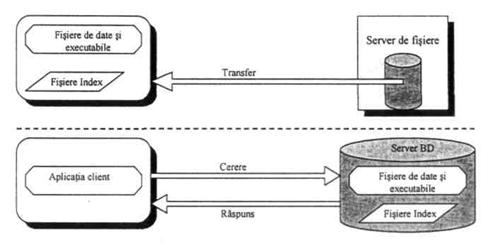
Fig.2.66. Arhitectura file/server si client/server
transmite interogarile/comenzile respective server-ului prin intermediul unei tehnologii de comunicatie;
analizeaza datele din rezultatele interogarilor/comenzilor primite de la server,
iar un server prin faptul ca:
furnizeaza un serviciu clientului;
raspunde la interogarile/comenzile clientului;
ascunde detaliile sistemului cls, facând transparent dialogul dintre client si server.
Serverele pot fi calculatoare personale sau sisteme de calcul specializate (minicalcula-toare, mainframe-uri) în vederea asigurarii legaturii dintre clienti si bazele de date din care se extrag informatiile dorite. Scopul principal este autonomia informatica a fiecarui angajat, în limita unor atributii delegate, angajat care poate astfel consulta si prelucra datele din orice loc aflat în interiorul sau în exteriorul întreprinderii. Prin accesul la toata gama serviciilor disponibile în retea se poate reactiona mai rapid si mai eficace la evenimentele care apar si deci se pot exercita mai eficient responsabilitatile încredintate.
Modelul client/server prezinta o natura cooperativa, aceasta însemnând ca parti semnificative din procesarea tranzactiilor au loc atât pe server, cât si pe client. Comunicarea între cele doua procese se realizeaza de obicei prin asa-numitele apeluri la distanta (Remote Procedure Caii - RPC) care opresc procesul client pâna ce se primeste un raspuns de la server pentru cererea respectiva. Server-ul începe sa proceseze numai la primirea unui apel din partea clientului si se opreste dupa satisfacerea respectivei cereri. Exista însa si mecanisme prin care executia clientului nu se opreste la trimiterea unei cereri catre server.
Arhitectura client/server are la baza patru elemente[25]:
O serie de lucrari în domeniu propun delimitarea în cadrul modelului client/server a trei categorii de prelucrare: client/server propriu-zisa, prelucrare cooperativa si prelucrare distribuita . Ceea ce am prezentat pâna acum ar privi prelucrarea client/server propriu-zisa. Prelucrarea cooperativa presupune ca datele unei aplicatii sa fie "împrastiate" pe diferite sisteme, astfel încât sa se asigure utilizarea optima a retelei si disponibilitatea datelor pentru orice utilizator care se conecteaza la retea. In sistemele de prelucrare distribuita, aplicatia este "împrastiata" pe mai multe sisteme care ruleaza simultan.
Orice sistem client/server este alcatuit din minimum trei componente principale:
![]() interfata cu utilizatorul (sistem de
operare/mediu grafic)
interfata cu utilizatorul (sistem de
operare/mediu grafic)
![]() aplicatia (prelucrarile sau
procesele) si
aplicatia (prelucrarile sau
procesele) si
![]() sistemul de gestiune a bazelor de date.
sistemul de gestiune a bazelor de date.
În practica, exista mai multe modalitati de repartizare a functiilor între client si server, asa cum rezulta si din figura 2.67[27].
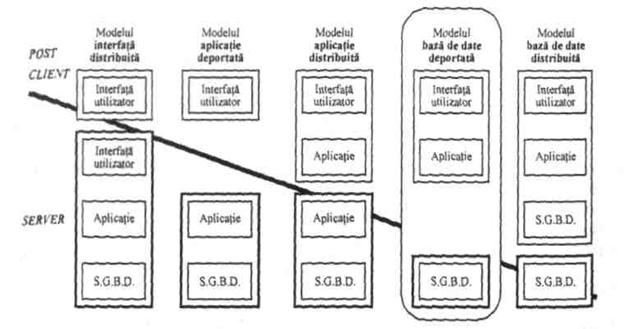
Fig.2.67. Cinci moduri de repartizare a functiilor între client si server
Modelul interfata distribuita. Codul aferent interfetei utilizator este împartit între platformele client si server, iar aplicatia si SBD-ul sunt, ambele, rezidente pe server. Este modelul unei arhitecturi clasice cu un calculator central gazda la care sunt cuplate terminale pasive (sistemele de minicalculatoare românesti INDEPENDENT, CORAL, mini-sistemele PDP ale firmei DEC etc).
Modelul aplicatie deportata. Codul aferent interfetei este plasat pe platforma client, în timp ce aplicatia si SBD sunt situate pe server (XWindows rulate sub Unix).
Modelul aplicatie distribuita. Presupune localizarea interfetei pe calculatorul-client, a SBD-ului pe calculatorul-server, în timp ce o parte a aplicatiei este rezidenta pe statie si cealalta parte pe server.
Modelul baza de date deportata. Interfata si aplicatia sunt rezidente pe platforma-client, în timp ce SBD-uI este plasat pe server. Este modelul arhitecturii client/server "clasice", pe logica caruia sunt realizate majoritatea sistemelor comercializate sub titulatura "client/server".
Modelul baza de date distribuita. Interfata, aplicatia si o prima parte a SGBD-ului se gasesc pe sistemul-client, în timp ce o a doua parte a SGBD este rezidenta pe server.
În general, daca baza de date este voluminoasa si dificil de întretinut, întreprinderile tind a se focaliza pe arhitecturi ce corespund modelelor aflate în partea stânga a figurii 67, iar în cazul în care activitatile desfasurate de utilizator sunt mai complexe (CAD, CAM etc.) tendinta este de a se focaliza pe modelele aflate în dreapta figurii.
Multe întreprinderi au aplicat solutii mixte, pe baza combinarii facilitatilor a doua sau mai multe modele, în functie de specificul unitatii, stadiul informatizarii (echipamente, programe, specialisti), resursele si cultura întreprinderii în materie de sisteme informationale.
Una din principalele probleme legate de sistemele client/server o reprezinta faptul ca activitatile trebuie repartizate de o maniera flexibila, astfel încât orice client sa poata deveni client. într-o astfel de situatie server-ul emite o cerere care este adresata fie unui alt server, fie unui post client.
O alta cerinta este legata de necesitatea adaptarii la evolutia ulterioara a retelei informatice. In faza proiectarii sistemului, abordarea trebuie sa fie globala si flexibila, pentru a putea ulterior adauga/suprima posturi client si server oriunde în retea. Aceasta sarcina este cu atât mai dificila cu cât mediile sunt, de obicei, eterogene (platforme mini cuplate cu mainframe-uri si PC-uri sau statii grafice, ce ruleaza sub diferite sisteme de operare si aflate uneori la distanta unele de altele).
În figura 2.67 sunt prezentate principalele modele privind repartizarea sarcinilor între clienti si server. Dialogul propriu-zis dintre cele doua noduri cade sub incidenta unei componente esentiala a oricarui sistem construit pe tipologia client/server: middleware-ul. Luând în calcul aceasta componenta, doua dintre modelele figurii 2.67, si anume aplicatie distribuita si baza de date deportata se prezinta ca în figura 2.68.
|
|
Fig. 2.68. Rolul middleware-ului în sistemele client/server
API pentru interfata grafica utilizator (GUI), API pentru apelul procedurilor aflate la distanta si API pentru accesul la bazele de date, toate sunt produse program de tip middleware. Middleware-ul reprezinta coloana vertebrala a arhitecturii client-server, fiind alcatuit dintr-o serie de programe care gestioneaza dialogul dintre servere si clienti, produse care se încadreaza în trei categorii:
o limbaj de interogare (de obicei SQL);
o interfata de programare (API-uri);
o doua servicii de comunicare - unul aflat pe platforma-client, celalalt pe platforma-server.
Tehnologia Network Computer, ai carei corifei sunt Oracle si Sun, se bazeaza pe aplicatii rezidente exclusiv pe servere care se încarca dinamic pe calculatorul-client (în functie de operatiile ce trebuie executate, de pe servere sunt transferate fragmente de cod - applet-uri - ale aplicatiei). Marele avantaj tine de eliminarea cheltuielilor privind administrarea sistemelor-client, cheltuieli care în timp s-au dovedit a fi foarte importante. Dezavantajul este legat de dependenta totala de server, spre deosebire de PC-uri, care si legate în retea, prezinta o considerabila independenta. Pentru multe dintre aplicatiile economice, tehnologia NC se anunta ca fiind un substitut deloc de neglijat al PC-ului traditional.
În noile conditii tehnologice, sistemele client/server înglobeaza atât aplicatiile ce au la baza "clasica" arhitectura bazata pe interfata grafica utilizator (GUI), ca parte de prezentare, cât si aplicatiile "web+centrice". Schema unui asemenea sistem client/server este prezentata în figura 2.69 .
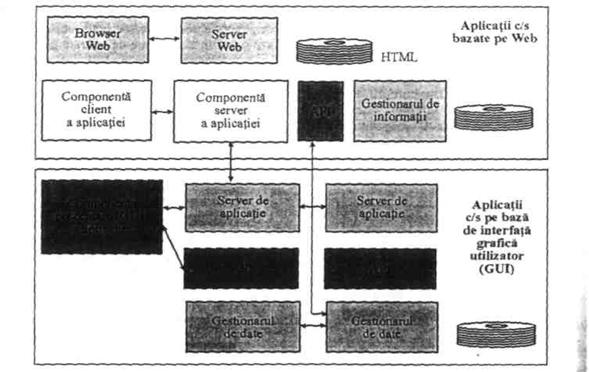
Fig. 2.69. Cadrul general al unui sistem client/server actual
Ca urmare a sporirii rolului middleware-ului în sistemele client/server, se disting doua mari tendinte în ceea ce priveste arhitectura acestora: arhitectura pe doua straturi si pe trei straturi (tendinta actuala fiind de arhitecturi pe n straturi).
Într-o arhitectura pe doua straturi interfata cu utilizatorul este de obicei localizata pe statia client în timp ce srviciile de management ale bazei de date sunt rezidente pe server. Managementul tranzactiilor este împartit între client (validari si prelucrari locale) si server (proceduri stocate si triggere). Desi suporta un numar destul de mare de utilizatori concurenti (aproximativ 100 în conditii de performanta satisfacatoare), aceasta arhitectura are un numar de limitari:
scaderea performantelor o data cu sporirea numarului de utilizatori datorita mentinerii unei conexiuni (de tip "keep-alive") la nivel de server cu fiecare utilizator conectat chiar daca nu sunt cereri de acces din partea acestuia;
implementarea serviciilor de management al tranzactiilor prin intermediul procedurilor proprietare ale SBD-ului limiteaza flexibilitatea si portabilitatea logicii aplicatiilor de pe un sistem pe altul.
Într-o arhitectura pe trei straturi intervine un nivel intermediar între interfata cu utilizatorul (nivelul client) si serverul de baze de date. Acest strat de mijloc se poate ocupa de gestiunea cozilor de cereri de acces la server, executia logicii aplicatiei precum si planificarea si gestionarea prioritatilor proceselor în progres. Ca urmare, numarul posibil de utilizatori concurenti creste semnificativ si, în acelasi timp, executia logicii aplicatiei pe o statie separata de serverul de baze de date duce la îmbunatatirea performantelor.
Exista mai multe posibilitati de implementare a acestei arhitecturi, fiecare utilizând tehnologii diferite la nivelul stratului de mijloc:
Tehnologia
monitorizarii procesarii tranzactiilor - furnizeaza suport pentru
înlantuirea si
formarea cozilor de mesaje, planificarea tranzactiilor si servicii de
gestionare a
prioritatilor. Tranzactia este preluata de catre
procesul monitor care va
avea grija sa o rezolve în totalitate si sa trimita
rezultatul înapoi clientului, acesta din
urma fiind astfel absolvit de
aceasta sarcina. Avantajele acestei tehnologii pot fi
rezumate astfel:
posibilitatea actualizarii mai multor SGBD-uri diferite într-o singura tranzactie;
posibilitatea atasarii unui ordin de prioritate tranzactiei;
securitate robusta.
Server de aplicatii. într-o asemenea arhirectura logica aplicatiei va rula pe un server separat în loc sa fie împartita în diverse proportii între server-ul de baze de date si client. Avantajele decurg, pe de o parte, din sporul de securitate obtinut prin faptul ca doar interfata va fi livrata clientului, iar pe de alta parte din sporul de flexibilitate, scalabilitate si performanta obtinut prin independenta codului aplicatiei de furnizorul SGBD-ului.
Tehnologia obiectelor distribuite. Dezvoltarea unor sisteme client/server utilizând tehnologii care suporta interoperabilitate între limbaje si platforme diferite are drept rezultat direct un spor ridicat de adaptabilitate si mentenabilitate. Actual, exista cel putin doua asemenea tehnologii:
CORBA (Common Object Request Broker Architecture);
COM / DCOM(Component Object Model).
Analizând, în numerele din iunie si iulie 1997 ale revistei DBMS Magazine[30] SBD-urile relationale extinse, Judy Davis identifica trei abordari majore în realizarea unei arhitecturi extensibile pentru gestiunea datelor: server universal, middleware si object layer (strat-obiect). Diferentele dintre acestea tin de doua aspecte: (1) cum si unde sunt gestionate datele: din acest punct de vedere, integrarea poate fi strânsa, stricta, realizata de un singur server, sau mai slaba, realizata pe mai multe servere; (2) unde are loc optimizarea interogarilor si actualizarilor bazei de date si care sunt performantele optimizarii: optimizarea interogarilor presupune realizarea legaturii dintre imaginea logica a datelor si cea fizica, alegându-se cea mai buna solutie de executie a interogarii. într-o prima tipologie de arhitecturi, de interogare se ocupa server-ul universal, în timp ce la o a doua middleware-ul.
Ideea de baza a serverelor universale este de a Ie înzestra cu facilitati privind stocarea, gestiunea si "întelegerea" datelor complexe în mod direct, "nativ". Informix utilizeaza termenul server universal, iar IBM - cel de baza de date universala. Spre deosebire de acestea, serverele universale extinse permit stocarea, accesul si gestiunea datelor aflate nu numai în baza, dar chiar si în fisiere externe baze care sunt legate strâns de baza. Spre exemplu, o coloana a unei tabele rationale poate sa contina un pointer catre o imagine stocata într-un fisier de imagini, imagine care prezinta caracteristici ce pot fi incluse în diverse interogari. Dintre marile firme, la mijlocul anului 1997 numai IBM îsi declarase explicit intentia de a realiza un asemenea produs.
Abordarea bazata pe middleware porneste de la premisa ca datele sunt rezidente si gestionate pe diferite servere, în functie de tipul lor: baze de date relationale, motoare de cautare de text, sisteme de gestiune a imaginilor, fisiere independente. Middleware-ul este cel care asigura imaginea unica asupra tuturor datelor, optimizeaza interogarile utilizatorilor si gestioneaza global tranzactiile. în cadrul acestuia se delimiteaza: middleware pentru baze de date (de exemplu DataJoiner - IBM, OmniConnect - Sybase), care asigura accesul integrat la date eterogene si middleware de aplicatie care cuprinde OLE DB, DCOM -Microsoft si alte produse de tip negociator de obiecte (ORB - Object Request Broker).
Abordarea object layer (bazata pe strat-obiect) integreaza imaginile si functionalitatea obiectelor Ia nivelul aplicatiei, asigurând pointere pentru navigare între obiecte, executii locale ale functiilor, optimizarea locala a interogarilor etc. SGBD-urile orientate pe obiecte sunt centrate, firesc, pe aceste elemente, avându-se în vedere asigurarea persistentei obiectelor create de aplicatie. în cazul SGBD-urilor, stratul obiect poate include posibilitatea de a lega obiectele din aplicatie cu obiectele din baza de date, astfel încât datele relationale pot fi materializate sub forma unor obiecte native C++, Java etc. Avantajul principal ar fi integrarea mai strânsa între gestionarul de date si mediul de dezvoltare al aplicatiei pentru a asigura o mai buna performanta.
Într-o arhitectura extensibila pentru gestiunea datelor, cele trei abordari pot fi combinate, dupa cum rezulta si din figura 2.70[31].
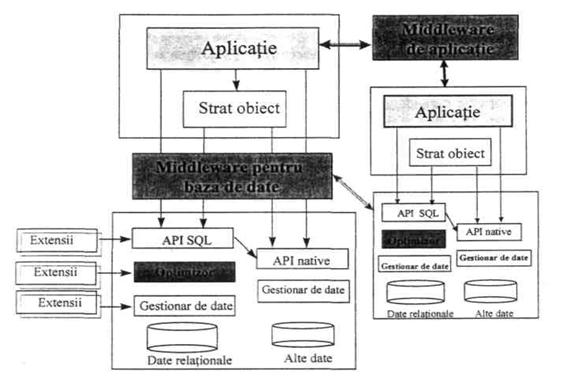
Fig. 2.70. Componentele unei arhitecturi extensibile de gestiune a datelor
2.8. Integrarea aplicatiilor web cu bazele de date
Software-ul care formeaza aplicatiile de întreprindere este destul de complex depinzând de variatele functii ale organizatiei pe care le deserveste si de contextul tehnologic în care este implementat, astfel încât aceste aplicatii constau în fapt de cele mai multe ori dintr-o multitudine de piese distincte. în timp, organizatiile încep sa înteleaga importanta integrarii aplicatiilor disparate pentru a spori beneficiile din exploatarea lor. Tehnologiile web au deschis noi oportunitati în acest sens, iar pentru a exemplifica câteva dintre caile potentiale prin care acestea îsi pot dovedi utilitatea putem aminti: noi sevicii îmbunatatite destinate clientilor prin integrarea suportului pentru cumparator cu planificarea interna a productiei, integrarea marketingului on-line via web între politicile de piata marind astfel aria de audienta, scaderea costurilor canalelor de distributie prin legarea managementului vânzarilor cu gestiunea stocurilor în Intranet, îmbunatatirea serviciilor catre angajati prin integrarea sistemului de resurse umane cu sistemul financiar-contabil în Intranet etc.
Restrictiile tinând de scalabilitatea hardware-ului fata de necesitatile de procesare în crestere, conectarea sistemelor dezvoltate anterior disparat în conditii de scalabiliate si eficienta, integrarea sistemelor dezvoltate pe baza mediilor suport provenind de la furnizori diferiti (de exemplu servere de baze de date diferite), restrictiile tinând de serviciile de securitate, tranzactii, integritate a datelor ce trebuie avute în vedere, toti acesti factori au împins software-ul de întreprindere catre o evolutie arhitecturala de la un singur strat (centralizare tip mainframe) la medii distribuite pe n straturi (n-tier). Astfel ca daca la început aspectele tinând de prezentare, logica afacerii si stocarea datelor erau practic nedelimitate, sistemele client/server (pe doua straturi) au realizat prima bresa preluând toate serviciile de prezentare si o parte din logica afacerii într-un strat distinct, dar introducând însa noi probleme tinând în special de administrarea aplicatiilor instalate pe multitudinea de clienti raspânditi în diverse locatii. Distribuirea aplicatiilor a fost favorizata apoi de aparitia unor noi tehnologii care au facut posibila dezvoltarea unor sisteme pe n straturi. în acest context, aplicatiile web sunt percepute ca rezultând din integrarea sistemelor pe trei straturi (cel putin) cu tehnologiile web.
În esenta, arhitecturile pe trei straturi, fata de arhitecturi le client/server pe doua straturi, separa logica afacerii pe un strat distinct localizat de regula pe un server de aplicatii care comunica strâns cu server-ul de baze de date. Paradigma dezvoltarii sofhvare-ului bazat pe componente ce comunica între ele prin interfete standardizate a facut posibila cresterea numarului de straturi armonizate în arhitecturi generic numite n-tier.
Tehnologiile web au adus în principal ca aport posibilitatea accesarii aplicatiilor folosind browser-e web, esentiale fiind protocoale ca HTML (pentru prezentare) sau HTTP pentru comunicare între clientii web si serverele web.
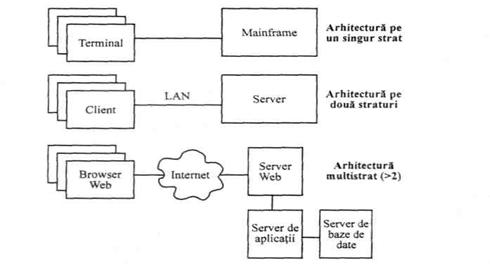
Fig.2.71. Prezentare sintetica a evolutiei arhitecturale a soft-ului de întreprindere
Arhitecturile multistrat se bazeaza pe dezvoltarea software-ului într-o abordare pe componente. Componentele software sunt slab cuplate între ele, favorizându-se astfel distribuirea lor pe mai multe straturi. Modelele bazate pe componente divid (din pacate) comunitatea dezvoltatorilor în doua lumi diferite: cele legate de tehnologiile Microsoft (MSActive X -* COM -* .NET) si cele legate de tehnologiile JAVA (sustinute în principal de SUN, dar si de alte companii importante ca IBM, BEA, Oracle plus comunitatea Open Source), mai exact J2EE (Java 2 Enterprise Edition). Ambele lumi (între care exista bineînteles si punti pentru interoperabilitate) se bazeaza pe paradigme de dezvoltare orientate-obiect (C++, re-proiectatul VB în varianta .NET si bineînteles Java). Optând (absolut nepartizan) pentru una din aceste tehnologii, un astfel de sistem ar arata cam ca în figura 2.72.
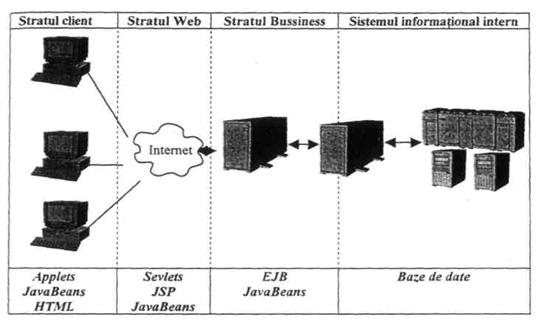
Fig.2.72. Tehnologiile Java (J2EE) pentru arhitectura multistrat specifica web-ului
Luând în considerare tehnologiile grupate sub umbrela Java 2 Enterprise Edition, fiecare dintre acestea este centrata pe o cerinta specifica si desemnata a fi utilizata într-un strat specific care influenteaza bineînteles modul cum vor fi proiectate, implementate si instalate (distribuite) aplicatiile de întreprindere. În tabelul 2.4. sunt prezentate pe scurt fiecare dintre aceste tehnologii:
Câteva detalii despre principalele tehnologii care formeaza platforma J2EE
Tabelul 2.4.
|
Tehnologie |
Rol |
|
Applet-uri |
Applet-urile reprezinta programe scrise în Java care pot rula direct într-un browser web (sunt gestionate la executie în browser, dar pot fi descarcate de pe un server web unde sunt rezidente). |
|
JSP (Java Server Pages) |
Sunt destinate, la fel ca si applet-urile, prezentarii informatiei în browser-ul clientului, însa nu într-un format executabil, ci prin cod HTML. în fapt JSP reprezinta tehnologia pentru scripting pentru server specifica mediilor Java. 0 pagina JSP reprezinta cod Java inclus într-un document HTML structurat si este intepretata pe serverul web care executa codul Java implicat generând o pagina HTML obisnuita. |
|
Servlet-uri |
Servlet-urile au aparut de fapt înaintea JSP-urilor si de altfel au în general cam acelasi scop. Servlet-urile reprezinta componente executate de server-ul web si care sunt apelate prin cereri HTTP la care raspund cu documente HTML construite în urma executiei lor. Deosebirea rezida în faptul ca ele nu reprezinta documente HTML care contin cod Java imbricat pentru portiunile dinamice, ci genereaza întreaga pagina. |
|
JavaBeans |
Reprezinta abordarea pe componente tipica în orice aplicatie Java (pentru web sau client/server). Ele înglobeaza de fapt logica obisnuita legata de regulile de afacere si pot fi apelate de tehnologiile implicate în partea de prezentare (applet-uri, servlet-uri, JSP) sau pot colabora între ele. |
|
Enterprise Java Beans |
Reprezinta o abordare pe componente superioara JavaBeans si sunt utilizate în aplicatii de întreprindere complexe bazate nu numai pe servere web (pe care se pot executa în mod obisnuit JSP, servlet-uri sau componente JabaBeans obisnuite), ci si pe servere de aplicatii dedicate care asigura un strat specific logicii afacerii pentru a satisface cerinte deosebite în ceea ce priveste scalabilitatea sau performantele superioare în medii puternic distribuite. Tehnologia EJB implica portabilitate nu numai pentru platforma OS (a sistemului de operare), ci si la nivelul 1 server-ului de aplicatii, asa încât o aplicatie bazata pe componente EJB ar trebui sa poate fi executata pe orice server certificat J2EE (cum ar fi IBM WebSphere, BEA WebLogic Server sau Oracle9i Application Server). De asemenea, componentele EJB sunt mult mai specializate decât JavaBeans-urile si sunt executate în container-e speciale asigurate numai de catre serverele de aplicatii (nu pot fi executate direct într-o JVM). Tipurile EJB sunt dedicate unor scopuri specifice care permit o mai buna proiectare a aplicatiilor de întreprindere. Astfel Session Beans-urile sunt utilizate drept controler-e (obiectele active ale aplicatiei), Entity Beans-urile sunt folosite pentru accesul la baza de date, iar Mesage-Driven Beans-urile sunt folosite pentru integrarea sistemelor slab cuplate (prin schimb de mesaje). |
Arhitectura pe 3 straturi pentru aplicatiile de întreprindere implica în general mai multe tipuri de servicii prezentate în tabelul 2.5.:
Scopul si obiectivele într-o arhitectura pe 3 straturi[32]
Tabelul 2.5.
|
Strat |
Scop |
Obiective |
|
Servicii de prezentare (Presentation Services) |
Prezentarea datelor Verificarea preliminara (acceptarea) datelor GUI (Graphical User Interface) |
Usurinta în utilizare Interactiuni naturale, intuitive cu utilizatorul Timpi mici de raspuns |
|
Servicii functionale ale afacerii (Business Services) |
Regulile de baza ale afacerii Flux de control al aplicatiei/dialogurilor Aplicarea regulilor de integritate a datelor |
Aplicare rigida a regulilor afacerii Conservarea investitiilor în cod Reducerea costurilor de întretinere |
|
Servicii de date (Data Services) |
Stocarea durabila a datelor si regasirea lor Accesul SGBD-urilor prin API-uri specifice (ODBC, JDBC, ADO) Controlul concurentei |
Baza de date consistenta, sigura si securizata Partajarea informatiei Timpi mici de raspuns |
n fapt aceasta arhitectura pe trei straturi este detaliata într-o arhitectura pe sase straturi logice, descompunând stratul Business Services (serviciile pentru afacere) în doua:
Business Context Services (serviciile de context) pentru filtrarea si "curatarea" informatiei provenita din interfata grafica;
Business Rule Services (serviciile regulilor afacerii) pentru implementarea regulilor traditionale ale afacerii.
De asemenea stratul Data Services (serviciilor pentru date) este descompus la rândul lui în:
Data Translation Services (serviciile de traducere/interpretare a cererilor de date) -pentru traducerea cererilor de informatii specifice "limbajului" stratului afacerii într-un limbaj compatibil cu serviciul de stocare a datelor (adica în SQL);
Data Access Services (serviciile de acces la date), cererile rezultate din stratul anterior sunt executate prin intermediul unui API specific comunicarii cu SGBD-ul care gazduieste baza de date (un driver ODBC sau JDBC);
Database Services (serviciile corespunzatoare bazelor de date).
Corespunzator, tehnologiile J2EE folosite în diversele straturi logice sunt repartizate ca în tabelul 2.6.:
Tehnologiile J2EE repartizate conform modelului arhitectural pe 6 straturi
logice[33]
Tabelul 2.6.
|
Serviciile |
Tehnologiile-suport |
|
Servicii de prezentare |
HTML si formulare cu script-uri executate pe partea de client |
|
Servicii de context ale afacerii |
JSP si servlet-uri sustinute de server-ul web |
|
Servicii ale regulilor afacerii |
JavaBeans si Enterprise JavaBens (session + entity beans) |
|
Servicii de traducere/interpretare a cererilor de date |
JavaBeans încapsulând cod nativ JDBC, ca si entity beans implementate într-un server de aplicatii ce asigura container-e pentru EJB |
|
Servicii de acces la date |
Implementate de catre JDBC sau managerul de persistenta pentru serverele de aplicatii ce suporta entity beans al caror mecanism de persistenta este asigurat de catre container printr-un manager de persistenta (CMP - Container Managed Persistence, în opozitie BMP - Beans Managed Persistence în care componenta entity beans comunica direct cu o interfata JDBC pentru a-si asigura singura serviciile de persistenta). |
|
Servicii corespunzatoare bazelor de date |
De exemplu Oracle sau MS SQL Server |
Prin urmare, conform arhitecturii pe sase straturi comunicarea dintre stratul serviciilor functionale ale afacerii - Business Services si serviciile de date - Data Services ar trebui realizata prin intermediul unui strat intermediar al serviciilor de traducere/interpretare a cererilor de date (Translation Services). Aceasta abordare este luata în considerare de majoritatea dezvoltatorilor datorita naturii diferite a celor doua medii conceptuale $i tehnologice (modelul orientat-obiect al aplicatiei - Java - prin care sunt specificate reguli]e afacerii si modelul relational prin care sunt formalizate structurile de stocare a datelor) care trebuie mapate prin intermediul acestui strat suplimentar.
Codificarea codului SQL-JDBC în clasele din domeniul afacerii
JDBC asigura o interfata (API) standard pentru accesarea bazelor de date relationale din aplicatiile Java indiferent de locatia în care se gaseste baza de date. Cu alte cuvinte JDBC ofera o cale prin care fraze SQL (corespunzatoare în principal standardului SQL recunoscut si mai putin clonelor SQL implementate în platformele de baze de date particulare) sunt transmise pentru a fi executate de catre SBD-ul gazda.
Structura unei aplicatii pentru web folosind tehnologia JDBC pentru conectarea la baza de date arata ca în figura 2.73.
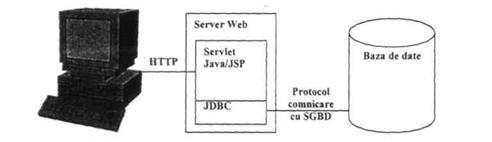
Fig. 2.73. Arhitectura unei aplicatii pentru Internet care acceseaza o baza de date prin JDBC
Se poate spune ca JDBC reprezinta o suma de specificatii prin care programatorul aplicatiei Java este scutit de sarcina codificarii accesului la un SBD proprietar, fiecare producator de SBD va furniza un driver specific care va respecta interfata JDBC, asa încât aplicatia Java va accesa datele într-o maniera (cât mai) portabila fata de bazele de date proprietare
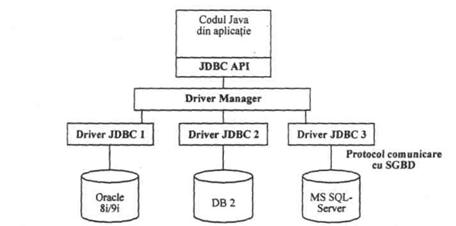
Fig. 2.74. Relatia dintre API JDBC si mecanismul de comunicare cu bazele de date[34]
JDBC API ofera astfel calea pentru utilizarea serviciilor esentiale ale SBD-ului folosit pentru stocarea datelor persistente din domeniul aplicatiei:
Stabilirea conexiunii la baza de date (invocând bineînteles mecanismul de securitate al SBD-ului).
Lucrul cu structurile logice relationale (tabele, view-uri etc.) pentru stocarea/regasirea datelor prin fraze conforme standardului SQL;
Administrarea mecanismului tranzactional oferit de SGBD (fie automat de catre driver-ul JDBC, fie manual în aplicatie);
Serviciile de partajare sau concurenta la nivelul datelor prin mecanismele de blocare si seriabilizare a tranzactiilor oferite ca suport prin SGBD-ul respectiv.
În practica, în functie de complexitatea aplicatiei (si oarecum si de abilitatea sau priceperea programatorului), exista mai multe abordari în ce priveste asigurarea (sub)stratului de persistenta[35]
Codificarea directa (hardcode) a dialogului SQL (prin API gen JDBC) în clasele din domeniul afacerii (stratul serviciilor regulilor afacerii).
Crearea unor clase pentru stocarea obiectelor care sa încapsuleze functionalitatea relationala corespunzatoare dialogului SQL. Acest lucru se face asemanator cu exemplul din listingul 1, eventualele îmbunatatiri constând în separarea suportului pentru persistenta (izolat în acest exemplu în structura statica) într-o clasa de sine statatoare (numita adesea DAO - Data Access Object [Reed, 2002]) care va respecta patern-ul singleton, adica o singura instanta în întregul spatiu al aplicatiei. în acest fel vom avea un JavaBean pur (doar cu metode get/set) care va abstractiza numai stratul logicii afacerii, iar în momentul în care se va face legatura dintre obiectele instan-tiate din aceasta clasa si baza de date relationala vor fi apelate metodele clasei DAO.
Crearea unui strat robust pentru persistenta. Este o sarcina dificila si care va aduce într-adevar beneficii pentru aplicatiile complexe în care separarea codului orientat-obiect al aplicatiei de schema relationala a bazei de date constituie un factor esential în asigurarea mentenantei. Programatorul aplicatiei va lucra într-un context asemanator cu cel din varianta anterioara, însa sarcinile legate de asigurarea corecta a suportului pentru persistenta vor genera responsabilitati pentru o suma de clase ce lucreaza împreuna pentru a asigura maparea transparenta a schemei 00 într-o schema relationala (tinând cont de aspecte mai complexe cum ar fi ierarhiile de mostenire sau legaturile asociative simple sau de agregare dintre obiecte), pentru a asigura desfasurarea într-o maniera tranzactionala a operatiilor legate de persistenta obiectelor (interactiunea cu mecanismele complexe de tranzactii si concurenta ale SGBD-urilor), pentru a centraliza suportul pentru persistenta disponibil eventual pe baza mai multor surse (baze de date relationale, baze de date obiectual/relationale, fisiere independente etc).
Clasele care au asigurata persistenta instantelor lor printr-una dintre caile amintite mai sus vor putea fi astfel invocate dintr-o interfata grafica construita pe baza unui applet Java sau a unei pagini HTML generata de un servlet sau o pagina JSP (Java Server Page).
2.9. Depozite de date
2.9.1. Definitie, caracteristici
Conform unor studii recente, depozitele de date au devenit, la sfârsitul anilor '90 una dintre cele mai importante dezvoltari din domeniul sistemelor informationale (Wixom and Watson, 2001). Palo Alto Management Group previziona înca din 1998 ca piata data ware-house va ajunge la 113,5 miliarde USD în 2002, incluzând aici vânzarile de sisteme data warehouse, software adecvat si servicii (Eckerson, 1998). Industria data warehouse s-a dezvoltat continuu în termeni de investitii, produse disponibile si proiecte elaborate. Se apreciaza ca aproximativ 90% dintre companiile multinationale au implementate depozite de date sau lucreaza Ia dezvoltarea unor proiecte data warehouse (Humphries et ai, 1999, p. xvii).
Depozitele de date sunt produsul mediului economic si al tehnologiilor avansate. Pe de o parte, mediul economic este tot mai competitiv, global si complex si solicita informatii elaborate pentru sprijinirea deciziilor strategice iar, pe de alta parte, evolutiile tehnologiilor informationale ofera solutii eficiente de gestionare a unor volume mari de date integrate, de ordinul terabytes-ilor, asigurând niveluri de sinteza/detaliere adecvate. Astfel, evolutiile performante hardware, precum sistemele de procesari masive paralele (Massive Parallel Processing - MPP), sistemele de multiprocesare simetrica (symetric multi-processing -SPM), sistemele tip baze de date paralele fac posibile încarcarea, întretinerea si accesul la baze de date de dimensiuni uriase. Aplicatiile data warehouse sunt în masura sa asigure si un timp mediu de raspuns extrem de scurt pentru categorii extinse de utilizatori.
Primele domenii care au adoptat tehnologia depozitelor de date au fost telecomunicatiile, bancile si comertul cu amanuntul. Ulterior depozitele de date au patruns si în alte domenii cum ar fi industria farmaceutica, sistemul sanitar, asigurarile, transporturile etc. Studiile statistice arata ca telecomunicatiile si sistemul bancar se mentin în top întrucât aloca cel putin 15% din bugetul IT pentru proiecte referitoare la depozite de date (Kelly, 1997).
Un proiect data warehouse reprezinta însa o investitie riscanta si scumpa. Costurile tipice pentru dezvoltarea unui depozit de date într-un interval de 3-6 luni se situeaza între 0,8 si 2 milioane USD. Ponderea echipamentelor se situeaza între 1/2 si 2/3 din costul total al proiectului (Humphries et ai, 1999, p. 59). O solutie pentru firmele mici si mijlocii este recurgerea la data marts pentru care costurile se situeaza sub 100.000 USD într-un interval adesea sub 90 de zile (Turban and Aronson, 2001, p. 145). Uneori investitiile în depozite de date nu se finalizeaza cu succes. Motivatiile cele mai des întâlnite pentru esecul unor data warehouse includ sustinerea insuficienta din partea conducerii organizatiei, insuficienta fondurilor si politicile organizationale defectuoase (Watson et ai, 1999).
Depozitele de date au fost definite în foarte multe moduri, astfel încât este destul de dificil de formulat o definitie riguroasa. în sens larg, un depozit de date reprezinta o baza de date care este întretinuta separat de bazele de date operationale ale organizatiei. Datele din sistemele sursa sunt extrase, curatate, transformate si stocate în depozite speciale în scopul sprijinirii proceselor decizionale (Graz and Watson, 1998). Depozitele de date sprijina procesarea informatiilor furnizând o platforma solida de consolidare a datelor istorice pentru analiza. Un depozit de date este o suma de date consistenta din punct de vedere semantic care serveste la o implementare fizica a unui model de date pentru sprijinirea deciziei si stocheaza informatii pe care o organizatie le solicita în luarea deciziilor strategice.
În concordanta cu W.H. Inmon, liderul în construirea sistemelor data warehouse, "un depozit de date este o colectie de date orientate pe subiecte, integrate, istorice si persistente, destinata sprijinirii procesului de luare a deciziilor manageriale" (Inmon, 1996). În sinteza definitia prezentata mai sus exprima caracteristicile majore ale depozitelor de date: orientarea pe subiecte, integrarea, caracterul istoric, persistenta datelor.
Orientarea pe subiecte
Un depozit de date este organizat în sensul unor subiecte majore cum ar fi: clienti, furnizori, productie, vânzari etc. Mai curând decât a concentra procesarea operatiilor si tranzactiilor zilnice într-o organizatie, un depozit de date se focalizeaza pe modelarea si analiza datelor pentru luarea deciziilor. Din acest motiv, depozitele de date ofera, în mod tipic, o viziune simpla si concisa relativa la un subiect particular excluzând datele care nu sunt utile în procesul de sprijinire a deciziei.
Integrarea
Un depozit de date este, în mod uzual, construit prin integrarea unor multiple surse heterogene: baze de date relationale, fisiere, înregistrari privind tranzactii on-line. Tehnicile de curatare a datelor {data cleaning) si de integrare sunt aplicate pentru a asigura concordanta în conventiile de atribuire a numelor, de codificare a structurilor, de atribuire a valorilor s.a.m.d.
Caracterul istoric.
Datele sunt stocate pentru a furniza informatii în perspectiva istorica (ex. 5-10 ani în urma). Astfel decidentii pot consulta valorile succesive ale acelorasi date pentru a determina evolutia în timp si a calcula tendintele anumitor indicatori.
Persistenta datelor
Datele dintr-un depozit sunt permanente si nu pot fi modificate. O actualizare a depozitului de date, ca urmare a modificarilor efectuate în datele-sursa, înseamna adaugare de date noi fara a modifica sau sterge datele existente. Un depozit de date este întotdeauna memorat separat, din punct de vedere fizic, de datele transformate din alte aplicatii. Datorita acestei separari, un depozit de date nu necesita mecanisme de procesare a concurentei. în mod uzual solicita numai doua operatiuni: încarcarea initiala a datelor si accesul la date.
În legatura cu depozitele de date o notiune frecvent utilizata este cea de "data warehousing" care desemneaza procesul de construire si utilizare a depozitelor de date (data warehouse). Construirea unui depozit de date necesita integrarea datelor, curatarea datelor si consolidarea datelor. Utilizarea unui depozit de date necesita adesea o colectie de tehnologii de asistare a deciziilor. Acestea permit specialistilor (ex. manageri, analisti, executivi) sa utilizeze depozitul pentru a obtine rapid si convenabil datele necesare si sa ia deciziile bazate pe informatiile din depozit. Alti autori utilizeaza termenul de "data ware-housing" pentru a referi numai procesul de construire a depozitului de date, în timp ce termenul de "warehouse DBMS" este utilizat pentru a referi conducerea si utilizarea depozitului de date (Han and Kamber, 2001).
2.9.2. Comparatie între depozitele de date si bazele de date
O comparatie între bazele de date si depozitele de date este în masura sa ofere o imagine coerenta privind rolul depozitelor de date în organizatii, precum si raporturile cu alte tipuri de sisteme informatice. Atât bazele de date, cât si depozitele de date contin mari cantitati de date structurate care pot fi consultate rapid datorita structurilor de acces optimizate si se bazeaza, în majoritatea cazurilor, pe tehnologii relationale. Totusi ele nu au fost proiectate pornind de Ia aceleasi obiective si se diferentiaza prin numeroase aspecte.
Sistemele de gestiune a bazelor de date sunt adecvate aplicatiilor curente de gestiune si servesc la crearea si întretinerea sistemelor de baze de date operationale. Aceste sisteme cunoscute sub denumirea de sisteme OLTP (On-Line Transaction Processing) au ca obiectiv executia on-line a tranzactiilor si a proceselor de interogare. Ele încorporeaza toate operatiile zilnice dintr-o organizatie cum ar fi: aprovizionari, stocuri, productie, decontari, plati, contabilitate. Sistemele depozite de date, pe de alta parte, servesc utilizatorii sau specialistii în domeniul analizei datelor si luarii deciziilor. Aceste sisteme pot organiza si prezenta datele în formate variate în ordinea solicitarilor de la diferiti utilizatori. Aceste sisteme sunt cunoscute sub numele de sisteme OLAP (On-Line Analytical Processing).
Bazele de date din sistemele operationale contin date curente, detaliate care trebuie actualizate si interogate rapid, în conditii de deplina securitate, constituind suportul sistemelor informationale de prelucrare a tranzactiilor (TPS).
Depozitele de date sunt concepute special pentru sprijinirea luarii deciziilor. Ele au ca obiectiv regruparea datelor, agregarea si sintetizarea lor, organizarea si coordonarea informatiilor provenind din surse diferite, integrarea si stocarea acestora pentru a da decidentilor o imagine adecvata care sa permita regasirea si analiza eficace a informatiilor necesare. Interogarile obisnuite într-un depozit de date sunt mai complexe si mai variate decât cele din sistemele de gestiune a bazelor de date. Ele se aplica asupra unor volume foarte mari de date si presupun calcule complexe (analiza tendintei, medii, dispersii etc.) care necesita adesea agregari (group by).
Deosebirile majore între OLTP si OLAP sunt sintetizate în tabelul 1 si iau în considerare urmatoarele trasaturi: utilizatorii si orientarea sistemului, caracterul datelor continute, nivelul de sinteza, unitatea de lucru, schemele de acces, numarul de înregistrari accesate, marimea bazelor de date, sistemul de evaluare etc.
Comparatie între sistemele OLTP si OLAP
Tabelul 2.6.
|
Nr. crt. |
Trasaturi |
OLTP |
OLAP |
|
Destinatia |
Procese operationale |
Procese informationale |
|
|
2. |
Orientarea sistemului |
Tranzactii |
Analize |
|
Utilizatori |
Functionari, administratori BD, profesionisti BD |
Specialisti, manageri executivi, analisti |
|
|
Functii |
Operatii zilnice |
Cerinte informationale pe termen lung, asistarea deciziei |
|
|
Instrumente folosite în proiectare |
Diagrame E-A |
Star/snowflake |
|
|
Caracterul datelor |
Curente, noutate garantata |
Istorice, precizie mentinuta în timp |
|
|
Nivelul de sinteza |
Primitive, detaliere ridicata |
Sintetizare, consolidare |
|
|
Unitatea de lucru |
Scurta, tranzactii simple |
Interogari complexe |
|
|
Scheme de acces |
Read/write |
Aproape întotdeauna Read |
|
|
Focalizare |
Culegere date |
Furnizare informatii |
|
|
Numar de înregistrari accesate |
Zeci |
Milioane |
|
|
Numar de utilizatori |
Mii |
Sute |
|
|
Marimea bazelor de date |
100MB-GB |
100GB-TB |
|
|
Prioritati |
Performante ridicate, disponibilitate ridicata |
Flexibilitate ridicata, autonomie utilizatori finali |
|
|
Sistem de evaluare |
Tranzactii culese |
Interogari culese, timp de raspuns |
Un sistem OLTP este orientat pe client (ciistomer oriented) si este utilizat pentru procesarea tranzactiilor si interogarilor. Un sistem OLAP este orientat spre piata (market-oriented) si este utilizat de manageri, analisti si specialisti. Din punctul de vedere al datelor continute, un OLTP gestioneaza date curente care, în mod obisnuit, sunt destul de detaliate pentru a fi usor utilizate în luarea deciziilor curente. Un sistem OLAP gestioneaza volume mari de date istorice furnizând facilitati pentru sintetizare si agregare, precum si pentru stocarea si gestionarea informatiilor cu diferite niveluri de granularitate. Aceste aspecte fac ca datele sa fie usor utilizate de catre decidenti, mai ales în domeniile tactic si strategic. De asemenea, un sistem OLTP este focalizat în principal pe datele curente dintr-o întreprindere sau dintr-un departament fara a referi date istorice sau date din alte organizatii, în contrast, un sistem OLAP cuprinde date istorice si date care provin de la diferite organizatii, integrând informatii din surse heterogene.
Discutiile despre depozitele de date conduc, în mod natural, la magazine de date (Operational Data Stores - ODS), care la prima vedere nu se deosebesc de depozitele de date. Desi ambele tehnologii sprijina decidentii, ele sunt diferite deoarece au scopul de a acoperi anumite tipuri de cerinte informationale.
W.H. Inmon, C. Imhoff, G. Battas (Inmon, W.H., Imhoff C, 1996) definesc un ODS ca "o constructie arhitecturala unde este stocata o colectie integrata de date operationale". ODS poate fi definit, de asemenea, ca o colectie de baze de date proiectate pentru sprijinirea controlului operational. Spre deosebire de bazele de date din aplicatiile OLPT (care sunt operationale sau orientate pe functii), ODS contin date orientate pe subiecte din întreprinderi mari. Spre deosebire de depozitele de date, datele din ODS sunt volatile si detaliate. ODS furnizeaza o viziune integrata asupra datelor din sistemele operationale. Tabelul 2.7. prezinta comparativ depozitele de date si magazinele de date.
Depozite de date în comparatie cu Magazinele de date
Tabelul 2.7.
|
Data Warehouse |
Operational Data Store |
|
|
Scopuri |
Sprijinirea deciziilor strategice |
Control operational |
|
Asemanari |
Date integrate Orientare pe subiecte |
Date integrate Orientare pe subiecte |
|
Deosebiri |
Date statice Date istorice Date sintetice |
Date volatile Date curente Detaliere ridicata |
2.9.3. Arhitectura depozitelor de date
Esenta unui depozit de date consta într-o baza de date de dimensiuni foarte mari continând informatiile pe care le pot folosi utilizatorii finali (vânzari, furnizori, campanii de publicitate etc). Arhitectura simplificata a unui depozit de date este prezentata în figura 2.75.
Fig.2.75 Arhitectura de principiu a unui depozit de date
În depozitul de date întâlnim mai multe tipuri de date care corespund diferitelor cerinte informationale ale utilizatorilor: date detaliate, date agregate, metadate. Metadatele descriu datele continute în depozitul de date si modul în care ele sunt obtinute si stocate. Prin metadate se precizeaza structura datelor, provenienta lor, regulile de transformare, de agregare si de calcul. Metadatele joaca un rol esential în alimentarea depozitului cu date. Ele sunt utilizate în toate etapele de încarcare a datelor si sunt consultate si actualizate pe parcursul întregului ciclu de viata al depozitului. Includerea datelor agregate în depozit, desi determina o crestere a redundantei datelor, este necesara deoarece în acest fel se poate asigura un timp mediu de raspuns cât mai redus.
Sursele de date pentru depozite sunt: bazele de date operationale curente, bazele de date vechi arhivate, precum si baze de date externe. Construirea depozitului de date presupune parcurgerea urmatoarelor etape:
Un proces de extragere a datelor din bazele de date operationale sau din surse externe urmat de copierea lor în depozitul de date. Acest proces trebuie cel mai adesea sa transforme datele în structura si formatul intern al depozitului.
Un proces de curatare a datelor, pentru a exista certitudinea ca datele sunt corecte si pot fi utilizate pentru luarea deciziilor.
Un proces de încarcare a datelor corecte în depozitul de date.
Un proces de creare a oricaror agregari ale datelor: totaluri precalculate, subtotaluri. valori medii etc. care se preconizeaza ca vor fi cerute si folosite de utilizatori. Aceste agregari sunt stocate în depozitul de date împreuna cu datele importate din sursele interne si externe.
Depozitele de date sunt destinate managerilor, analistilor si specialistilor angrenati în luarea deciziilor strategice privind dezvoltarea si viitorul organizatiilor. Pentru aceasta ei au nevoie de instrumente performante de accesare si utilizare a datelor din depozite, instrumente asigurate prin software-ul asociat depozitului de date. întreaga gama de instrumente software asociate depozitelor de date este prezentata în figura 2.76. Pe de o parte regasim instrumente necesare utilizatorilor care au nevoie de acces rapid la informatii punctuale care includ un limbaj de interogare gen SQL sau generatoare de rapoarte (Report Writers) ce transpun informatiile în formate adecvate. Pe de alta parte sunt instrumente specializate pentru asistarea deciziilor care transforma informatiile în forma ceruta de decidenti (grafice, diagrame, organigrame) sau ofera posibilitatea analizei tendintelor, corelatiilor si interpretarea acestora. In aceasta categorie se încadreaza instrumentele OLAP si Datamining.
Instrumentele OLAP se bazeaza pe reprezentarea multidimensionala a datelor (cubul de date) si permite analiza interactiva si rapida a datelor prin operatiuni de tip roll-up, drill--down, slice, dice etc. Utilizatorul poate obtine rezultate imediate parcurgând dinamic dimensiunile cubului de date lucrând cu niveluri diferite de sinteza/detaliere.
Instrumentele de tip datamining asigura transformarea datelor în cunostinte, de aceea multa lume considera termenul datamining sinonim cu termenul de Knowledge Discovery in Databases (KDD). Se utilizeaza tehnici ale analizei statistice sau de inteligenta artificiala care permit descoperirea de corelatii, reguli, cunostinte utile sprijinirii deciziilor.

Fig. 2.76. Componentele software ale depozitelor de date
Din punct de vedere al ariei de cuprindere, se întâlnesc trei modele de depozite de date: depozite de întreprindere (entreprise warehouse), data mart si depozite virtuale de date.
Un depozit de întreprindere (Entreprise Warehouse) colecteaza toate informatiile despre subiecte care privesc întreaga organizatie. El furnizeaza un volum extins de date. De regula contine date detaliate dar si date agregate, iar ca ordin de marime porneste de la câtiva gigabytes pâna la sute de gigabytes, terabytes sau mai mult. Un depozit de date de întreprindere poate fi implementat pe traditionalele mainframes, pe superservere UNIX sau pe platforme cu arhitecturi paralele. Necesita cheltuieli mai mari pentru modelare si ani de zile pentru proiectare si realizare.
Un data mart contine un subset al volumului de date din organizatie, specific unui grup de utilizatori. Domeniul este limitat la subiecte specifice. De exemplu, un data mart pentru marketing limiteaza subiectele Ia clienti, articole, vânzari. Datele continute în data mart sunt de obicei agregate. Data marts sunt, în mod curent, implementate pe servere departamentale mai ieftine care se bazeaza pe UNIX sau Window/NT. Ciclul de implementare a unui data mart este mai curând masurat în saptamâni decât în luni sau ani. Ca atare, un data mart poate fi considerat un subansamblu al unui depozit de date mai usor de construit si întretinut si mai putin scump.
Un depozit virtual (Virtual warehouse) este un set viziuni (yiews) asupra bazelor de date operationale. Pentru eficienta procesarii interogarilor numai unele dintre viziunile de agregare pot fi materializate. Un depozit virtual este usor de construit dar necesita capacitati suplimentare pe serverele de baze de date.
Modele de date specifice data warehouse
Cel mai popular model pentru depozitele de date este modelul multidimensional. Reprezentarea datelor în modelele multidimensionale poate fi în forma de stea (star schema), de fulg de zapada (snow-flake schema) sau de constelatie (constellation schema).
Reprezentarea "stea" (Star schema) este cel mai comun model de date, în care depozitul de date contine un tabel central voluminos (tabel de fapte) care cuprinde cea mai mare parte a datelor fara redundante si un set de tabele însotitoare (tabele-dimensiune) pentru fiecare dimensiune. Graful asociat seamana cu o stea în care tabelele-dimensiune sunt afisate radial în jurul tabelului de fapte central (vezi figura 3).
Exemplul 1.
Un exemplu de schema stea este prezentat în figura 2.77.
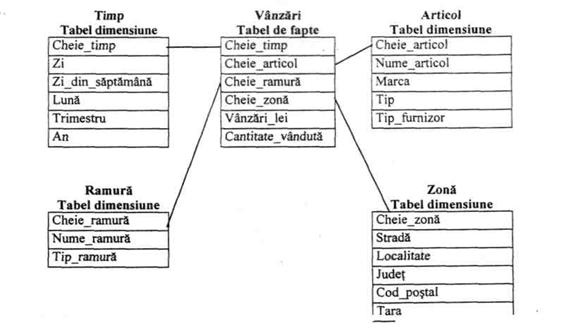
Fig.2.77. Schema-stea a unui depozit de date pentru vânzari
Vânzarile sunt considerate cu 4 dimensiuni numite timp, articol, ramura si zona. Schema cuprinde un tabel central pentru vânzari care contine chei pentru fiecare dintre cele 4 dimensiuni înaintea celor doua masuri: vânzari-lei si cantitate-vânduta.
Schema "fulg de zapada" (snowflake) este o varianta a modelului "stea", unde anumite tabele-dimensiune sunt normalizate, astfel încât apar tabele suplimentare. Rezulta o schema reprezentata într-un graf similar unui fulg de zapada. Diferenta majora între modelul "fulg de zapada" si modelul "stea" este ca tabelele dimensiune din modelul "fulg de zapada" pot fi pastrate în forma normalizata ceea ce determina o redundanta redusa. Asemenea tabele sunt usor de întretinut si se economiseste spatiu de stocare deoarece un tabel dimensiune mare poate deveni enorm.
Structura "fulg de zapada" poate reduce eficacitatea "browsing-ului" când mai multe ,join-uri" trebuie executate la o interogare. De aceea, schema fulg de zapada este mai putin raspândita decât schema-stea în proiectarea depozitelor de date.
Exemplul 2.
Un exemplu de schema fulg de zapada pentru vânzarile firmei ALFA SA este prezentat în figura 2.78. Aici tabelul de fapte - vânzari este identic cu cel din schema stea din figura 77. Principala diferenta între cele doua scheme cauta în definirea tabelelor-dimensiune. Dintr-un singur tabel-dimensiune pentru articol din schema stea, în schema fulg de zapada rezulta doua tabele: unul nou pentru articol si altul pentru furnizor. Atributul cheie-furnizor din furnizori face legatura cu tabelul articol. în mod similar, tabelul dimensiune zona poate fi normalizat în doua noi tabele: zona si localitatea. Atributul cheie-localitate face legatura între cele doua tabele. Normalizarea poate continua.
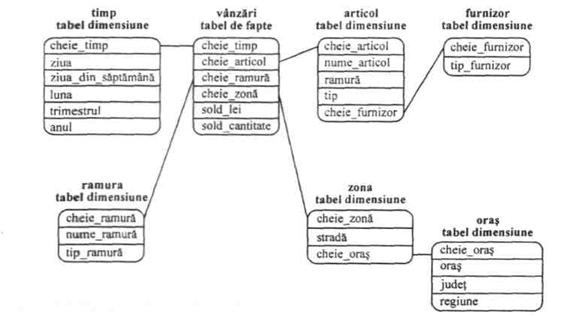
Fig.2.78. Schema fulg de zapada pentru depozitul de date Vânzari
Aplicatiile sofisticate pot solicita tabele multiple de fapte care partajeaza tabelele--dimensiune. Acest gen de schema poate fi vazut ca o colectie de stele si, de aici, denumirea de schema-galaxie sau constelatie de fapte (fact constellatiori).
Literatura de specialitate prezinta mai multe situatii în care un depozit de date este oportun pentru rezolvarea problemelor aparute: insuficienta partajare a informatiilor, grupuri diferite produc rapoarte contradictorii, procesul de creare a rapoartelor este foarte anevoios, rapoartele nu sunt dinamice si nu favorizeaza stilul de interogare ad-hoc, rapoartele care necesita date istorice sunt dificil de realizat.
o Insuficienta partajare a informatiilor
De exemplu, serviciile sau departamentele care au aceiasi clienti nu comunica informatiile între ele. Ca urmare, se pierd oportunitatile referitoare la stabilirea profilului real al clientilor. De asemenea, clientii pot fi plictisiti de faptul ca departamente din cadrul aceleiasi organizatii le solicita de mai multe ori aceleasi informatii. Rezolvarea acestei probleme, prin tehnologia depozitelor de date, duce la urmatoarele avantaje:
pot fi luate decizii mai eficiente în domeniul gestiunii clientilor;
clientii sunt tratati ca entitati individuale;
pot fi explorate noi oportunitati de afaceri.
o Grupuri diferite produc rapoarte contradictorii
Datele din sisteme operationale diferite conduc la informatii diferite despre acelasi subiect. Folosirea inconsistenta a termenilor duce la reguli diferite pentru acelasi subiect. Astfel, faptele sunt interpretate diferit, iar în organizatie vor exista mai multe versiuni ale "adevarului". Decidentii trebuie sa analizeze date conflictuale si îsi pot pierde credibilitatea în fata clientilor, furnizorilor etc. Solutia depozitelor de date conduce la urmatoarele beneficii:
se poate vorbi de o viziune consistenta asupra operatiunilor întreprinderii;
se pot lua decizii mai bune, bazate pe analize corecte.
o Procesul de creare a rapoartelor este foarte anevoios
Rapoartele de importanta critica necesita prea mult timp pentru a fi produse, ceea ce face ca atunci când sunt disponibile sa nu mai fie necesare. Preluarea datelor într-un raport complex din mai multe sisteme operationale poate conduce la inconsistente sau erori. Ca urmare, deciziile luate pe baza acestor rapoarte pot fi eronate. Analistii din organizatie pierd prea mult timp cu colectarea datelor de care au nevoie, iar pentru analiza propriu-zisa le ramâne prea putin timp. Concurentii care nu au asemenea probleme beneficiaza în mod clar de un avantaj competitiv. Rezolvarea acestei probleme conduce la urmatoarele rezultate pozitive pentru organizatie:
procesul de creare a rapoartelor este în mod vizibil îmbunatatit;
ramâne mai mult timp pentru analiza efectiva a datelor;
decidentii nu sunt nevoiti sa lucreze cu date "învechite".
o Rapoartele nu sunt dinamice si nu favorizeaza stilul de interogare ad-hoc.
Rapoartele prezentate managementului superior nu sunt dinamice si nu au capacitatea de a oferi facilitati drill-down pentru detalierea datelor. Ca urmare, când un raport prezinta o situatie de alarma sau de exceptie, decidentul nu poate vedea mai multe detalii despre situatia respectiva. O data rezolvata aceasta problema, decidentii pot obtine mai multe detalii atunci când au nevoie, iar analizele referitoare la tendinte si la relatii cauzale vor fi posibile.
o Rapoartele care necesita date istorice sunt dificil de realizat.
Datele istorice despre clienti, produse si operatiuni financiare nu sunt stocate în sistemele operationale. încercarea de a incorpora datele mai vechi în noile rapoarte se poate lovi de impedimentul nepotrivirii vechilor structuri cu cele actuale. Ca urmare, rapoartele nu pot fi produse la timp sau chiar deloc, iar decidentii nu vor avea posibilitatea de a efectua analize de trend de-a lungul unei perioade de timp mai mari. Organizatia nu va fi capabila sa anticipeze evenimentele si schimbarile de comportament; cererile consumatorilor vor veni ca o adevarata surpriza, iar organizatia va trebui sa se forteze pentru a le satisface.
2.9.5. Riscuri în realizarea si implementarea depozitelor de date
Riscurile tipice care se pot produce în timpul dezvoltarii unui depozit de date pot fi împartite în urmatoarele categorii: organizationale, tehnologice, legate de managementul proiectului, legate de proiectarea depozitului de date.
![]() Riscurile
organizationale.
Riscurile
organizationale.
Sustinatorul proiectului trebuie sa provina din zona conducerii strategice a afacerii si nu din zona strategica IT. Având în vedere dimensiunea si scopul, o initiativa data warehouse trebuie sa fie orientata pe afacere, altfel organizatia va considera întregul efort ca fiind un experiment tehnologic. Sustinatorul proiectului trebuie sa fie o persoana care va utiliza depozitul de date si care îsi poate asuma responsabilitatea initiativei.
Acest rol nu poate fi delegat unui comitet. Din pacate, multe organizatii prefera sa stabileasca un comitet însarcinat cu proiectul data warehouse pentru a dispersa responsabilitatile. Daca este stabilit un astfel de comitet, se recomanda ca presedintele comitetului sa fie sustinatorul proiectului.
Riscurile organizationale provin si de la utilizatorii finali care pot obstructiona, intentionat sau nu, evolutia proiectului. în functie de cunostintele tehnice pe care le au si de cultura organizationala, utilizatorii vor fi în masura sa precizeze cu grade diferite de acuratete cerintele pe care le au, necesitatile privind securitatea sistemului etc.
![]() Riscurile tehnologice
Riscurile tehnologice
În aceasta categorie se încadreaza folosirea inadecvata a tehnologiilor data warehouse, calitatea scazuta a sistemelor operationale existente, instrumente nepotrivite pentru utilizatorul final.
Folosirea inadecvata a tehnologiilor depozitelor de date apare atunci când se încearca utilizarea lor în scopul rezolvarii problemelor operationale ale organizatiei sau pentru a se implementa solutii în timp real. De asemenea, utilizarea mai multor minidepozite de date disparate nu poate constitui un factor de succes sigur, deoarece sistemul informational din cadrul organizatiei trebuie sa functioneze într-un cadru unic.
Calitatea scazuta a sistemelor operationale poate determina echipa de dezvoltare a depozitului de date sa-si concentreze atentia mai mult pe "curatarea" si verificarea datelor de intrare, neglijând esentialul depozitului de date. In acelasi timp, un sistem operational defectuos va ridica probleme la extragerea, transformarea si încarcarea datelor în depozitul de date. Utilizatorii potentiali ai depozitului de date nu-I vor apela daca informatiile pe care le ofera sistemul sunt eronate sau dubioase. Ceea ce conteaza foarte mult este perceptia asupra calitatii datelor, indiferent daca datele sunt corecte sau nu.
Aria larga de instrumente pentru utilizatorii finali trebuie bine analizata înainte de a decide ce instrument va folosi fiecare categorie de utilizatori. Daca, de exemplu, pentru conducerea executiva se va opta pentru un set de instrumente care sa necesite cunostinte informatice avansate, proiectul este cu siguranta sortit esecului. în acelasi mod pot reactiona utilizatorii versati care se vor simti frustrati în cazul în care instrumentele de folosire si gestionare a depozitului de date vor fi prea simple.
![]() Riscuri legate de
managementul proiectului.
Riscuri legate de
managementul proiectului.
Unul dintre aceste riscuri este determinat de definirea nerealista a anvergurii proiectului. Literatura de specialitate recomanda ca un astfel de proiect sa înceapa cu o etapa-pilot si apoi depozitul de date sa fie dezvoltat incremental. Specialistii considera ca organizatiile care mizeaza pe proiecte monolitice de amploare foarte mare vor întâmpina dificultati în gestionarea situatiilor care apar si vor avea sanse foarte mici de a termina cu bine ceea ce au început. în contrast, dezvoltarea incrementala reduce riscurile si minimeazâ pierderile.
Multe proiecte data warehouse au esuat datorita subestimarii timpului necesar operatiunilor de extragere, integrare si transformare a datelor. Desi poate parea neobisnuit, este realist ca pentru aceste operatiuni sa se aloce un timp important din durata întregului proiect. Practica a dovedit ca pentru operatiunilor back-end (extragere, integrare, verificare calitate, agregare, încarcare) trebuie sa se aloce între 60% si 80% din durata proiectului, iar pentru operatiunile front-end (instrumente OLAP, rapoarte, interogari) între 20% si 40% (Humphries et al., 1999, p. 65) Echipa de dezvoltare trebuie sa se concentreze atent pe partea de back-end deoarece pe ea se sprijina cealalta componenta (front-end) care nu poate fi implementata pâna când nu este functionala prima.
Managementul proiectului trebuie sa se preocupe si de ceea ce se întâmpla dincolo de implementarea depozitului de date: utilizatorii noi care au acces la functionalitatile depozitului trebuie instruiti, utilizatorii vechi trebuie înstiintati despre modificarile care apar si, de asemenea, se recomanda o monitorizare a activitatii depozitului de date în primul an (contorizare înregistrari frecvente, statistici despre cautarile care se efectueaza) pentru a optimiza structura si interogarile.
Riscuri legate de proiectarea depozitului de date. Echipa de proiectare trebuie sa faca o distinctie neta între metodele folosite în cazul sistemelor OLTP si cele de tip data warehouse. în timp ce sistemele OLTP mizeaza pe normalizarea relatiilor si pe înregistrarea eficienta a tranzactiilor, depozitul de date trebuie gândit ca un cub de date multidimensional care contine tabele denormalizate, agregari, variabile etc.
O greseala frecventa care se face consta în alegerea gresita a gradului de granularitate. Depozitul de date contine atât date atomice, cât si date sintetice. O granularitate prea mare nu permite obtinerea rapoartelor detaliate de care au uneori nevoie managerii, în timp ce un grad scazut de granularitate conduce la necesitatea efectuarii unui numar mare de agregari si la capacitati sporite de stocare.
2.9.6. Produse-program pentru dezvoltarea depozitelor de date
Majoritatea firmelor producatoare de software pentru baze de date s-au orientat catre implementarea unui modul specific depozitelor de date, însa în topul preferintelor de afla SQL Analysis Manager, produs de Microsoft Corporation, si Oracle Warehouse Builder, apartinând companiei Oracle. Aceste doua instrumente beneficiaza de experienta si puterea financiara a companiilor producatoare si au reusit sa se impuna pe piata ca solutii viabile.
Modulele principale pe care le poate folosi dezvoltatorul în proiectarea depozitului de date se refera la:
stabilirea surselor de date: baze de date de pe serverul compatibil sau dintr-o alta sursa agreata;
stabilirea tabelelor de fapte: câmpuri, chei, masuri etc;
stabilirea dimensiunilor din depozitul de date: ierarhii, surse de date;
stabilirea valorilor calculate si a agregarilor;
stabilirea drepturilor de utilizare si a politicilor de securitate privind accesul.
Evolutia continua a acestor produse software se concretizeaza într-o utilizare din ce în ce mai facila; de exemplu, utilizatorul poate gestiona vizual diferite elemente precum masuri, ierarhii, dimensiuni, valori agregate (vezi figura 2.79). De asemenea, aceste produse permit utilizatorului gestionarea facila a metadatelor, orice modificare efectuata asupra structurii depozitului fiind reflectata în cadrul sectiunii de metadate.
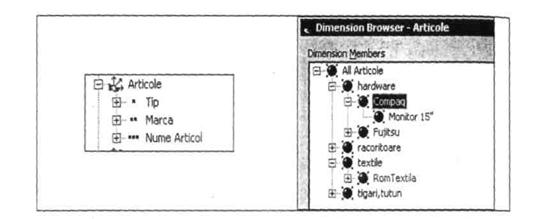
Fig.2.79. Ierarhia dimensiunii Articole în conceptia SQL Analysis Manager
2.9.7. Directii de dezvoltare a depozitelor de date
Industria depozitelor de date este în continua expansiune, numarul producatorilor data warehouse continua sa creasca, la fel si numarul de produse disponibile pe piata. O astfel de tendinta încurajeaza micii producatori sa se asocieze sau sa fuzioneze pentru a crea competitori mai puternici si mai viabili pe aceasta piata cu un potential ridicat (de exemplu, fuziunea dintre Apertus Technologies si Carleton Corporation din noiembrie 1997).
Actorii existenti pe piata sistemelor de gestiune a bazelor de date sunt interesati de achizitia tehnologiilor si companiilor care sa le ofere posibilitatea de a incorpora în motoarele bazelor de date facilitati warehouse (de exemplu, achizitia Intellidex Systems de catre Sybase în februarie 1998 si achizitia Logic Works de catre Platinum Technologies în martie 1998).
Instrumentele data-mining vor continua sa se maturizeze si din ce în ce mai multe organizatii vor adopta acest gen de tehnologie. Initiativele data mining provin cel mai adesea din zona departamentelor de marketing si de vânzari cu amanuntul si se preteaza foarte bine în organizatiile care detin baze de date cu volume foarte mari. Datorita faptului ca aceste instrumente dau cele mai bune rezultate cu date nivel ridicat de detaliere, popularitatea instrumentelor data mining va coincide de fapt cu dezvoltarea depozitelor de date la dimensiuni de ordinul terabytes. Proiectele data mining vor accentua si mai mult importanta calitatii datelor din depozitele de date.
Tehnologiile data warehouse continua sa fie influentate de popularitatea solutiilor bazate pe intranet si Internet. Ca urmare, din ce în ce mai multe instrumente de acces Ia date vor putea suporta facilitatile oferite de web. Unele organizatii au început deja sa foloseasca infrastructura Intemetului pentru a oferi utilizatorilor posibilitatea de a utiliza depozitul de date de Ia distanta, însa exista rezerve serioase în ceea ce priveste securitatea acestui mediu de transmisie.
Date, C.L, An Introduction to Database Systems, Addison-Wesley, Reading, Massachusetts, 4th edition, 1986, p. 33.
Pascal, F., The Future of DBMS-Part I, DBAzine, https://www.dbazine.com/ pascal..html
Pascal, F., OOfor application development, not database management, SearchData-base, https://www.searchdatabase.com. sept. 2001 care îi citeaza pe Butler si Bloor.
Garcia-Molina, H., Ullman, J., Wdiom, J., Database Systems: The Complete Book, Prentice-Hall, New Jersey, 2002, p. 11.
Sursa: Date, C.J., "Thirty Years of Relational. Codd's Relational Algebra", în fntelligent Enterprise, mai 1999
Stodder, D., Kestelyn, J., "What's Next for the Database", în Intelligent si Enterprise Magazine, mai 2002.
T. Livy-Abegnoli, "SGBD Workgroup: un concept tras marketing", în 01 Informatique, no. 1354/1995, pp. 24-25; "Workgroup Databases Redux" (M. Ricciuti), în InfoWorld, voi. 17, no. 46/1995, p. 43.
Date, C.J., An Introduction to Database Systems, Addison-Wesley, Reading, Massachusetts, 4thedition. 1986, p. 651.
Connolly, T. and Begg , C, Database Systems. A practicai Approach to Design, Implementation, and Management, Addison Wesley, third edition, 2002, p. 702.
Date, C.J., An Introduction to Database Systems, Addison-Wesley, Reading, Massachusetts, 4thedition, 1986, p. 655.
Miranda, S., Busta, J.M., L 'ort des bases de donnees, voi. I-II, Eyrolles, Paris, 1990, voi. 2, p. 30.
Pascal, F" The Future of DBMS- Part I, DBAzine, https://www.dbazine.com/ pascal6.html.
Preluare din Harmon, P., "Les systemes client-serveur", în Ginie logiciel et systemes experti, I no. 34, mart. 1994.
Preluare de pe httD.//www.infoit.com
Extended Relational DBMS's: The Technology, https://www.dbmsmag.com/9706d 13.htm si IUniversal Servers: The Players, https://www.dbmsmag.com/9707d 14.htm
Ahmed, Khawar Yaman si Umrysh, Carrz E., Developing Entreprise Java Applications with J2EE and UML, Addison-Weslez, 2002
Stodder, D., Kestelyn, J., "What's Next for the Database", în Intelligent Enterprise Magazine, mai 2002
|