Internetul si World Wide Web reprezinta fundamentul pe care îl utilizeaza firmele pentru a construi economia informationala. În aceasta economie, informatia valoreaza la fel de mult ca bunurile sau serviciile, devenind o parte vitala a pietei. Pe o asemenea piata, se impun tehnologiile cele mai bune, deoarece toate organizatiile încearca sa obtina un avantaj fata de competitori, utilizând, printre altele, si noile tehnologii.
În economia informationala, este strategic pentru fiecare organizatie sa aiba o buna utilizare a informatiilor. Este foarte important, deci, ca informatia sa fie integrata cu afacerea însasi.
În vreme ce acestea par a fi noi tendinte, Internetul si World Wide Web doar intensifica o provocare pe care profesionistii din IT (Information Technology) o simt de mult, si anume cererea de a realiza un management de calitate al informatiilor valoroase ale organizatiei. Într-o prima faza, raspunsul la aceasta cerere s-a materializat în managementul computerizat al informatiilor critice ale afacerii. Mai recent, a început sa fie simtita nevoia de integrare mai mare între afacere si sistemele de calcul, precum si nevoia de a avea capacitatea de corelare a unor informatii din surse diferite în vederea unor nevoi strategice specifice.
Enterprise Java este un concept din ce în ce mai raspândit în lumea calculatoarelor. Nu s-a dorit traducerea acestui concept în româna, întrucât i s-ar putea denatura sensul original. În orice caz, enterprise semnifica întreprindere, companie, organizatie. De ideea de organizatie, este legat un alt termen foarte des întâlnit în lumea informatica, si anume intranet.
Un intranet reprezinta o retea de calculatoare interna a unei organizatii deci protejata de lumea exterioara. Cu alte cuvinte, un intranet reprezinta o insula în marea numita Internet, insula autonoma si cu guvernare interna, dar supusa protocoalelor de comunicare din Internet.
Acum se clarifica conceptul de enterprise Java: este vorba de aplicatiile Java proiectate pentru intranet, si anume pentru intranet - ul specific unei organizatii, deci e vorba de modul de utilizare a tehnologiei Java la nivel de întreprindere.
Una dintre tehnologiile Internet obisnuite, puse în functiune în interiorul organizatiilor, este sistemul hypertext al Web-ului. Folosirea intranet - ului unei companii ca mediu de scriere a informatiilor în pagini de Web da posibilitatea angajatilor companiei sa gaseasca repede raspunsuri la întrebari. Ei nu trebuie sa caute documentatie în alta parte, ci e suficient sa caute informatia respectiva în paginile de Web ale companiei. În mod ideal, intranet - ul unei companii foloseste multe tehnologii Internet ca : e-mail, ftp, telnet, news si servicii de Web.
Notiunea de enterprise este destul de larga, ea semnificând orice firma, organizatie, companie care utilizeaza calculatoare ce ruleaza aplicatii de uz intern. Asta nu înseamna, însa, ca aplicatiile dezvoltate si folosite de o firma anume nu pot fi folosite si de altele. Fiecare companie fie ea mica, medie sau mare are diferite departamente : management, marketing, proiectare si dezvoltare de programe, resurse umane, etc. Fiecare departament foloseste aplicatii specifice, deci aceleasi departamente ale mai multor firme pot folosi aceleasi aplicatii.
În industria calculatoarelor, termenul enterprise este utilizat pentru a desemna o organizatie care utilizeaza computere. Acest termen desemneaza corporatii, mici afaceri, institutii non profit, institutii guvernamentale si alte tipuri de organizatii. Totusi, în practica, termenul este aplicat mai degraba organizatiilor mai mari.
Pe masura dezvoltarii tehnicii de calcul si odata cu aparitia arhitecturii client/server, se impun noi strategii de dezvoltare a aplicatiilor folosite în industrie.
Pentru a raspunde nevoilor organizatiilor, s-a impus ideea de componente software. Exista mai multe implementari ale acestui concept. În principal, implementarile vin de la Microsoft , Sun si OMG.
O posibila definitie a componentelor software este urmatoarea: "O componenta software este o portiune de cod care implementeaza un set de interfete. Este o unitate discreta de aplicatie logica care poate fi controlata. Componentele nu sunt aplicatii de sine statatoare, nu pot functiona singure. Ele sunt utilizate în mod asemanator pieselor de puzzle pentru a rezolva probleme mai mari. Ideea de componente software este foarte practica. O companie poate cumpara un modul bine definit care rezolva o problema si îl poate utiliza împreuna cu altele pentru a rezolva probleme mai mari". (Roman, 1999).
Se spune ca o componenta software are o "granularitate" mai mare decât cea a unei clase (Roman, 1999), dar, în mod evident, mai mica decât a întregii aplicatii.
O alta posibila definitie este aceasta: "Componentele software sunt unitati de compunere cu interfete specificate prin contract si care au doar dependente de context explicite. O componenta software poate fi instalata si utilizata de terte parti. Componentele si potentialii utilizatori ai acestora se dezvolta independent, motiv pentru care este important ca serviciile oferite de catre o componenta sa fie facute cunoscute prin interfetele implementate de componenta. Mai mult, distributia si instalarea componentelor se face sub forma binara, deci clientii lor nu vor avea acces la codul sursa." (Jurca, 2000)
Avantajele utilizarii componentelor software sunt multiple: în primul rând, timpul în care poate sa fie dezvoltata o aplicatie scade simtitor, ceea ce permite firmei sa aiba o pozitie mai buna pe piata. Un alt avantaj este ca nu este nevoie de persoane cu experienta foarte bogata pentru a crea o aplicatie, folosind componente software cumparate. Aici trebuie mentionat ca realizarea componentelor necesita, totusi, cunostinte foarte solide de programare obiectuala. Cel mai mare avantaj este faptul ca se poate astfel reutiliza codul în alte aplicatii, în acest fel costul total al unei aplicatii scazând.
Un alt concept foarte important, care tine de filozofia unei aplicatii enterprise, este cel de arhitectura multi tier. În primul rând, ar trebui prezentat conceptul de tier. O aplicatie software poate fi împartita în mai multe niveluri izolate unele de altele. Avantajul este ca se câstiga o independenta între nivele, astfel ca, atunci când unul se modifica, impactul asupra celorlalte este minim, daca interfata dintre ele nu se modifica. Un astfel de nivel al aplicatiei se numeste tier.
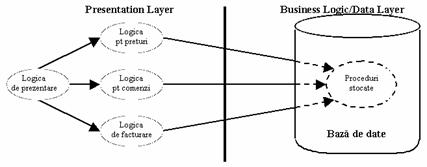
În mod traditional, aplicatiile sunt structurate pe doua tiers: Presentation Layer si Business Logic/Data Layer. Problema cu aceasta abordare este ca logica de bussiness este continuta în procedurile stocate din baza de date. Din pacate, fiecare baza de date are propriul limbaj în care se scriu procedurile stocate, deci este foarte greu portabil. În cele mai multe cazuri, aplicatiile create folosind doar doua straturi (tiers) sunt nescalabile si greu portabile. Arhitectura unei asemenea aplicatii poate fi observata în Figura 2.1.
Scalabilitatea este proprietatea unei aplicatii de a fi extinsa (pentru a putea fi utilizata de mai multi utilizatori, în ideea de acoperire a nevoilor unei organizatii în expansiune) folosind mai multe sisteme de calcul dar fara a fi nevoie sa se modifice codul sursa.
Totusi, avantajul unei asemenea arhitecturi sta în faptul ca traficul în retea necesar este mai mic, deoarece procesarea se face local în serverul de baze de date. Pe de alta parte, Java începe sa fie folosit tot mai mult ca limbaj pentru procedurile stocate. Însa, ramân probleme cu scalabilitatea aplicatiei si cu faptul ca driverul de baze de date este instalat la client. Astfel, orice update la driver este foarte costisitor, deoarece necesita ca fiecare client sa-si schimbe driverul.
Figura
2.1. Arhitectura clasica two
tier a aplicatiilor
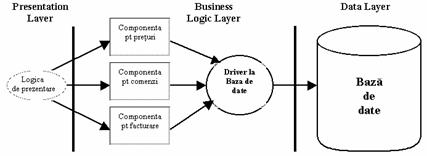
Într-o
arhitectura multi tier, se
interpun între cele doua tiers
din modelul clasic, unul sau mai multe
alte tiers noi. De fapt, ceea ce se
face este ca se separa logica de business de cea legata de baza
de date. În acest fel, se poate câstiga independenta fata
de baza de date. De obicei, aplicatiile multi tier sunt divizate în
trei straturi, dupa cum se poate
observa si din Figura 2.2.
Figura 2.2. Arhitectura unei aplicatii three tier
Cele trei straturi (tiers) ale arhitecturii three tier, pornind de la nivelul bazei de date, sunt:
I. Data Tier (stratul de date) este compus din una sau mai multe baze de date care pot contine si logica de procesare sub forma de proceduri stocate.
II. Business Logic Tier (stratul de logica de business) este stratul în care ruleaza componentele software. Serverul (serverele) utilizat în acest strat are rolul de a furniza un mediu de viata potrivit pentru componentele software. Acest server are rolul de a realiza un management eficient al componentelor si de a le furniza anumite servicii. De exemplu, serverul poate furniza un strat de acces la baza de date, permitând componentelor sa salveze si sa încarce date din System Information Tier. Un alt rol important al serverului este sa faca componentele sa fie disponibile pentru utilizare, sa le instantieze dupa necesitati, deci sa le gestioneze ciclul de viata.
III. Presentation Tier (stratul de prezentare) are rolul de prezenta informatia la client, de obicei folosind tehnologii ca Java Server Pages si servlets sau Active Server Pages, iar ca server folosind servere Web.
Caracteristicile unei aplicatii multi tier sunt urmatoarele:
Costurile deployment - ului (instalarea si punerea în functie) aplicatiilor este mai mic, deoarece driverele pentru bazele de date sunt instalate la partea de server si nu sunt necesare instalarile la fiecare client ca în modelul clasic.
Modificarea bazei de date se poate face cu usurinta, deoarece clientii nu mai acceseaza direct baza de date, ci middle tier care va face legatura cu baza de date. Deci o modificare a bazei de date va duce doar la modificari ale middle tier, fara a necesita vreo modificare la partea aplicatiei client.
Modificarea logicii de business este usor de realizat, deoarece nu este nevoie de recompilarea clientului.
Partile vitale ale aplicatiei ( situate în Business Logic Tier si Data Information System) pot fi protejate folosind firewalls amplasate plasate între Presentation Ttier si Business Logic Tier.
Resursele pot fi reutilizate în mod eficient exploatând faptul ca, de obicei, clientii fac alte lucruri pe lânga utilizarea de resurse, ca de exemplu afisarea interfetei grafice. Se poate implementa un mecanism prin care componentele folosesc împreuna conexiunile la resurse. Acest mecanism se numeste pooling mechanism si are avantajul cresterii scalabilitatii aplicatiei. Acest mecanism se poate aplica si asupra componentelor, având ca rezultat faptul ca un client nu va avea nevoie de o componenta dedicata doar lui. Acesta este un avantaj major al arhitecturii multi tier fata de arhitectura two tier (cea clasica), unde fiecare client avea o componenta dedicata lui.
Erorile sunt localizate, nu se propaga de la un tier la altul. Daca apare o eroare critica, ea se gaseste într-un singur tier. Celelalte tiers pot sa functioneze fara probleme în continuare, punând la dispozitie ceea ce le sta în putere pentru a face fata situatiei. De exemplu, daca serverul de aplicatii în care ruleaza componentele din middle tier cade, totusi ramâne în functiune Web serverul din presentation tier care poate afisa o pagina de "site down" pentru clienti.
Dezavantajul aplicatiilor cu arhitecturi multitier este necesitatea unei benzi mai mari, daca nu se face o proiectare inteligenta a obiectelor distribuite. Aceasta apare deoarece tiers (straturile aplicatiei) sunt separate fizic, aflându-se de multe ori pe masini diferite, iar obiectele distribuite trebuie sa comunice unele cu altele. Toate acestea duc la cresterea traficului. Exista, totusi, posibilitatea de a elimina o parte din trafic, daca se face o proiectare a obiectelor distribuite, astfel încât sa se apeleze între ele cât mai rar si atunci sa-si transmita unul altuia datele în mod eficient.
În concluzie, cele doua arhitecturi au avantajele, dar si dezavantajele lor. Daca se doreste realizarea unei aplicatii care sa aiba trafic minim, atunci se va folosi arhitectura clasica, cea two tier, însa vor fi mari probleme cu portabilitatea si cu modificarile ulterioare ale codului, uneori si cu scalabilitatea. Daca, în schimb, se foloseste arhitectura multi tier, atunci se va câstiga portabilitate si usurinta în realizarea modificarilor ulterioare, precum si scalabilitate, dar se va pierde din eficienta utilizarii traficului disponibil. Totusi trebuie mentionat faptul ca o proiectare buna a aplicatiei poate atenua mult din acest dezavantaj.
Componentele Enterprise au avantajul ca permit realizarea de aplicatii cu arhitectura multi tier, beneficiind, astfel, de toate avantajele mai sus mentionate.
Implementarea conceptului de componenta de catre Microsoft a fost facuta folosind serviciile sistemului de operare Windows NT. Tehnologia DCOM furnizeaza o modalitate de separare a interfetei fata de implementarea ei si astfel se realizeaza independenta fata de limbaj. Alte tehnologii Microsoft utilizate in aplicatiile enterprise sunt:
MSMQ (Microsoft Message Queues) permite comunicarea între componente.
MTS (Microsoft Transaction Server) este un server care foloseste componentele.
Microsoft SQL Server este folosit pentru stocarea datelor în baze de date relationale.
Microsoft Internet Information Services are rol de server Web.
Microsoft Management Console este utilizat pentru deployment.
Dezavantajul major al implementarii de la Microsoft este dependenta de platforma, deoarece se poate utiliza doar Windows NT si în plus, pentru acest gen de servere, este nevoie de masini foarte puternice, mai ales pentru marile companii. Numarul maxim de procesoare pentru masinile pe care poate rula Windows NT este de 16 pentru Windows 2000 (NT5.0).
Implementarea conceputului de componenta de catre Object Management Group (OMG) este înca în faza de început. Celelalte doua standarde dezvoltate pâna acum de catre OMG sunt Common Object Request Broker (CORBA) si Internet Inter-ORB Protocol (IIOP). Aceste doua standarde furnizeaza un cadru potrivit pentru obiecte distribuite. Este foarte important de mentionat ca J2EE (produsul de la Sun) implementeaza deja cele doua standarde. În plus, în cadrul OMG, exista mari dezbateri daca standardul CORBA Components sa fie scos, deoarece J2EE este deja compatibil CORBA/IIOP.
O implementare foarte populara vine de la firma Sun Microsystems si este reprezentata de standardul J2EE. Acest standard a fost implementat de Sun precum si de catre alte firme ca BEA prin produsul BEA Web Logic sau Allaire prin produsul JRun. Java 2 Enterprise Edition (platforma J2EE) suporta aplicatii distribuite, care folosesc avantajele oferite de un numar mare de alte tehnologii aflate în expansiune în momentul de fata.
J2EE (Java 2 Enterprise Edition) este o platforma Java proiectata pentru a prelucra date pentru organizatii mari, care folosesc mainfraime - uri. Sun Microsystems (împreuna cu partenerii sai ca IBM) au proiectat J2EE pentru a simplifica dezvoltarea aplicatiilor client/server cu client, fara capacitate mare de procesare (ca de exemplu un browser). J2EE simplifica dezvoltarea aplicatiilor prin crearea de componente care pot beneficia de multe servicii din partea platformei în mod automat.
Platforma J2EE pune la dispozitie un model multi tier distribuit de realizare a aplicatiilor. Aceasta înseamna ca parti diferite ale aplicatiei pot sa ruleze pe calculatoare diferite. Arhitectura J2EE defineste un Client Tier , un Middle Tier (care poate fi compus din mai multe subtiers, de obicei denumite Web Tier si EJB Tier) si un Enterprise Information Tier care furnizeaza servicii utilizând sistemele de informatii deja existente (de obicei bazele de date).
Client tier suporta o mare varietate de tipuri de clienti care se pot afla sau nu dupa firewall, cum e cazul, in general, al firmelor care se protejeaza folosind firewalls.
Middle tier furnizeaza servicii pe de o parte pentru clienti folosind containere Web si pe de alta parte pentru componentele de business folosind containere Enterprise JavaBeans.
Enterprise Information System furnizeaza accesul la sistemele informationale deja existente, folosind APIs (Application Programming Interfaces) standardizate.
În Figura 2.3., se prezinta arhitectura generica a unei aplicatii enterprise folosind J2EE, cu ilustrarea împartirii în tiers (straturi).
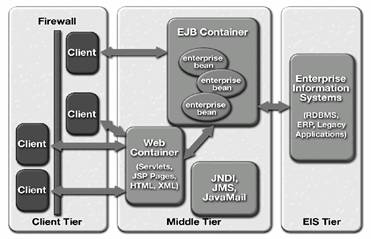
Figura 2.3. Arhitectura multi tier pusa la dispozitie de platforma J2EE
Platforma Java 2 Enterprise Edition este compusa dintr-o suita de tehnologii care fac platforma usor de utilizat, chiar pentru probleme complicate, astfel dându-i o valoare sporita.
Nucleul tehnologiei J2EE este Enterprise JavaBeans (EJB), care este o specificatie a componentelor software utilizate de catre platforma J2EE. Aceasta specificatie este implementata de mai multe firme (prima care a reusit a fost BEA prin produsul WEBLogic).
Celelalte tehnologii utilizate de platforma J2EE vor fi prezentate foarte pe scurt în continuare:
Java Remote Method Invocation (RMI) si RMI- IIOP. Tehnologia RMI permite comunicarea între procese si furnizeaza alte servicii legate de comunicare. RMI-IIOP este o extensie portabila a RMI, care foloseste protocolul de comunicare Internet Inter Object Protocol (IIOP). IIOP poate fi utilizat pentru a migra spre CORBA (Common Object Request Broker). Folosind CORBA, se poate realiza comunicarea între aplicatii de pe platforme diferite, scrise în limbaje de programare diferite. Aceasta este o modalitate de legare a componentelor J2EE cu alte componente create folosind alte tehnologii.
Java Naming and Directory Interface (JNDI). JNDI identifica locatia componentelor si a altor resurse în retea.
Java Database Connectivity (JDBC). JDBC este un bridge (punte de legatura) care permite realizarea unor operatii la baza de date în mod portabil.
Java Transaction API (JTA) si Java Transaction Serice (JTS). Aceste tehnologii adauga platformei J2EE capacitatea de a rula tranzactii la nivel de componente software si la nivelul bazei de date.
Java Messaging Service (JMS). JMS permite comunicarea între obiecte distribuite în mod asincron.
Java Servlets si Java Server Pages (JSP). Servlet-urile si JSP - urile sunt componente de retea care sunt potrivite pentru prelucrari cerere / raspuns, cum este cazul clientilor HTTP.
Java IDL este implementarea standardului CORBA de catre Sun folosind Java. Java IDL permite obiectelor distribuite sa beneficieze de toate serviciile puse la dispozitie de catre CORBA. De remarcat ca platforma J2EE este complet compatibila CORBA.
Java Mail este un serviciu care permite aplicatiilor sa trimita mesaje e-mail într-o maniera independenta de platforma, respectiv de protocol.
Connectors. Conectorii sunt o tehnologie care permite integrarea unor sisteme deja existente.
Extensible Markup Language (XML). Unele tehnologii J2EE (ca EJB1.1 si JSP) utilizeaza XML pentru a descrie continutul.
În Figura 2.4., este prezentata o imagine de ansamblu a tuturor tehnologiilor care sunt parte din J2EE si care fac aceasta platforma foarte puternica.
Având în vedere importanta majora a acestor tehnologii ca parti ale platformei J2EE, se va face, în continuare, o prezentare foarte sumara a fiecareia.
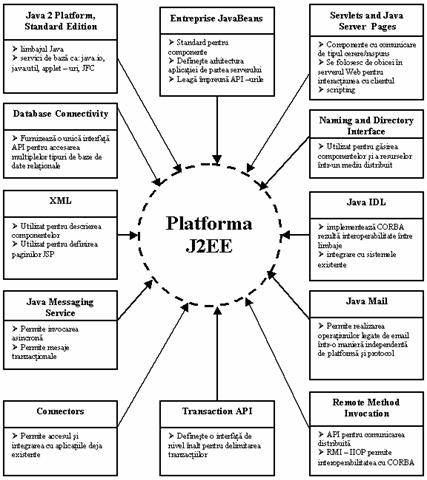
Figura 2.4. Imagine de ansamblu asupra tehnologiilor utilizate de platforma J2EE
RMI este un mecanism de invocare a metodelor obiectelor aflate pe alte statii sau pe aceeasi statie, dar în Java Virtual Machine diferite . Este foarte bine integrata cu limbajul Java. RMI permite programatorilor Java sa comunice într-o maniera distribuita, folosind un stil de programare aproape identic cu cel de la scrierea applet-urilor sau a aplicatiilor stand alone. RMI aduce comunicarea prin retea la nivelul de concept deorece ascunde programatorului detaliile legate de retea, ca de exemplu ordinea de transmitere a bitilor. RMI are si alte caracteristici, ca de exemplu download - ul dinamic de clase, activarea automata a obiectelor distante. Are un Garbage Collector distribuit, care distruge obiectele distante nefolosite.
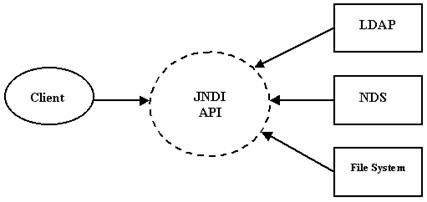
Aceasta tehnologie este un standard pentru serviciile de naming and directory. Enterprise JavaBeans se bazeaza pe aceasta tehnologie pentru a gasi componentele distribuite în retea. JNDI este o tehnologie cheie, deoarece aceasta este singura modalitate de a obtine o referinta la componente din codul clientului.
Figura
2.5. Serviciul de naming and
directory JNDI
JNDI afiseaza termenul de serviciu de directoare. Un serviciu de directoare stocheaza informatii despre locul în care se afla componentele, cât si alte informatii conexe, ca de exemplu numele utilizatorului si parola. În EJB, atunci când un client cere accesul la o componenta, serviciul de directoare este folosit pentru a obtine o componenta care sa deserveasca acel client. Serviciul de directoare poate fi gândit ca facând corespondenta între clienti si componentele cerute.
În mod istoric, exista mai multe asemenea servicii de directoare, ca de exemplu NDS de la Novell sau LDAP. JNDI este independent de toate acestea, fiind ca o punte care stie sa comunice cu toate aceste servicii. JNDI abstractizeaza codul scris într-un serviciu de naming and directory particular si permite ca sa se foloseasca alt serviciu fara a modifica codul. Din acest motiv, folosind JNDI se poate scrie cod portabil pentru serviciul de naming and directory.
Package-ul Java Database Connectivity (JDBC 2.0) este o extensie standard a limbajului Java, care permite programatorilor Java sa foloseasca o unica interfata aplicatie (API) pentru accesul la baze de date relationale. Cu JDBC, programatorii Java pot folosi conexiuni la baze de date, executa comenzi SQL, procesa rezultatele interogarilor, utiliza proceduri stocate si multe altele, într-o maniera portabila. Pentru fiecare tip de baza de date care se doreste a fi utilizata împreuna cu JDBC, este nevoie de un driver care "traduce" comenzile JDBC în comenzi specifice acelei baze de date. JDBC este asemanator cu Open Database Connectivity (ODBC), ba chiar cele doua sunt inter-operabile prin puntea JDBC - ODBC.

JDBC 2.0 are, din
start, inclus mecanismul de pooling
pentru conexiunile la baze de date. Este un lucru stiut ca o
conexiune la o baza de date este mare consumatoare de resurse. Acest
mecanism permite ca o anumita conexiune sa fie utilizata mai
eficient. Atunci când o componenta are nevoie de o conexiune se va
instantia una. Cand componenta nu o mai utilizeaza conexiunea este
trecuta într-un asa numit bazin (pool)
. În momentul când vreo componenta are nevoie de o conexiune, se va scoate
din bazin conexiunea si se va furniza componentei pentru a o utiliza.
Numarul de conexiuni maxim din bazin este configurabil.
Figura 2.6. Privire de ansamblu asupra JDBC
Datorita importantei mari in aplicatii, aceasta tehnologie va fi tratata separat într-un capitol urmator.
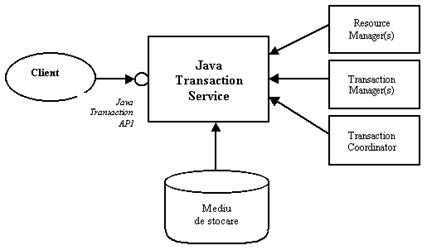
O tranzactie este un set de operatii care sunt garantate ca vor fi executate împreuna, iar daca apar erori, atunci se renunta la toate operatiile din succesiunea de operatii ce au fost deja executate. Tranzactiile sunt unul dintre punctele forte ale platformei J2EE. Rolul lor este de a mentine un sistem în stare de consistenta. Tranzactiile permit mai multor utilizatori sa modifice aceleasi date simultan si, totusi, tranzactiile sa fie izolate unele de altele . În esenta, este o forma foarte avansata de sincronizare a datelor.
Pentru a facilita tranzactiile, firma Sun a produs doua interfete aplicatie : Java Transactions API (JTA) si Java Transaction Service(JTS). Aceste doua produse specifica cum pot fi realizate tranzactiile în Java, dupa cum se poate observa din Figura 2.7.
JTA este o interfata de nivel înalt, care permite aplicatiilor client sa controleze tranzactiile în codul Java.
JTS este un set de interfete de nivel jos pentru tranzactii, care este folosit de catre EJB în spatele scenelor. JTS este bazat pe Object Transaction Service (OTS), care este o parte a CORBA. Enterprise JavaBeans depinde strict de JTA, dar nu depinde de JTS.
Figura
2.7. Java Transaction API (JTA)
si Java Transaction Service (JTS)
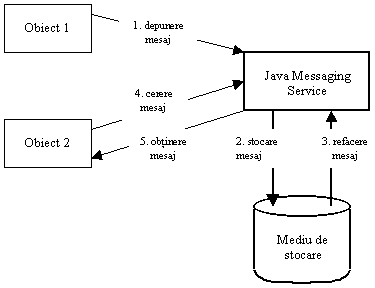
Un serviciu de messaging permite obiectelor distribuite sa comunice într-o maniera asincrona, dar sigura. Prin faptul ca mesajele sunt trimise asincron, în loc sa fie transmise sincron, scalabilitatea sistemului creste. Procesele pot raspunde la mesaje când sunt în executie, dar exista situatia în care s-ar putea sa nu se afle în executie în momentul în care mesajul este trimis initial.
Specificatia Java Messaging Service (JMS) defineste un serviciu portabil de messaging. Prin utilizarea unui API comun, obiectele distribuite pot comunica într-o maniera tranzactionala, toleranta la caderi, asincrona, dar cel mai important este ca ele comunica într-o maniera independenta de vendor. În Figura 2.8. este schitat serviciul de messaging din platforma J2EE.
Figura
2.8. Serviciul de messaging JMS
al platformei J2EE
Servlet - urile sunt componente distribuite, care pot fi folosite pentru a extinde functionalitatea unui server Web. Servlet - urile sunt orientate pe un protocol de tipul cerere / raspuns, în sensul ca preiau cererile de la clientii care le lanseaza (de obicei dintr-un Web browser), iar apoi proceseaza un raspuns pentru acea cerere. Din acest motiv, servlet-urile sunt potrivite pentru a rezolva problemele legate de Web. Oricum, este important de observat faptul ca servlet-urile nu sunt, în mod necesar, legate de serverele Web si pot fi utilizate ca si componente generice de tipul cerere / raspuns, fara a necesita managementul sofisticat al unui application server.
Java Server Pages (JSPs) sunt foarte similare servlet-urilor. De fapt, scripturile JSP sunt compilate în servlet-uri. Cea mai mare diferenta dintre scripturile JSP si servlet-uri este ca scripturile JSP nu sunt cod Java pur, ci sunt centrate mai mult în jurul problemelor de aspect ale interfetei. Se vor utiliza pagini JSP atunci când se doreste ca partea de interfata a aplicatiei sa fie separata de restul aplicatiei. Avantajul paginilor JSP este ca pot fi realizate si întretinute de catre persoane care nu cunosc programare în Java.
Ambele tehnologii vor fi prezentate într-un subcapitol separat datorita faptului ca sunt foarte des utilizate.
CORBA este un standard dezvoltat de catre OMG în interesul si cu acordul comun a sute de alte companii care au fost interesate într-o arhitectura independenta de platforma. CORBA este independent de limbaj. Nu conteaza limbajul în care este scris programul, atâta timp cât CORBA suporta acel limbaj.
Common Object Request Broker Architecture (CORBA) defineste o arhitectura pentru crearea, distribuirea si managementul obiectelor distribuite într-o retea. Aceasta arhitectura permite programelor din locatii diferite si dezvoltate în limbaje de programare diferite sa comunice în retea prin intermediul unui Object Request Broker (ORB). Acest ORB reprezinta programul care actioneaza ca "broker" între cererile pentru un anume serviciu, venite de la un obiect sau componenta distribuita si satisfacerea acelor cereri. Daca într-o retea este implementat ORB, atunci componentele sau obiectele pot solicita servicii de la alte componente de pe alte masini, fara a fi nevoie sa stie nici macar pe ce server sunt situate acele componente distante sau cum arata interfata la server. Prin intermediul ORB, componentele pot sa se gaseasca una pe alta si sa schimbe informatii în timpul rularii.
Un ORB foloseste CORBA Interface Repository pentru a localiza în retea o componenta si pentru a comunica cu ea. Atunci când se creeaza o componenta care sa poata utiliza serviciile puse la dispozitie de ORB, programatorul trebuie sa declare interfetele publice ale componentei folosind Interface Definition Language (IDL).
IDL este un limbaj care permite unui obiect scris într-un limbaj sa comunice cu un alt obiect scris într-un limbaj "necunoscut". IDL solicita ca interfetele unui program sa fie descrise într-un stub, care este o extensie adaugata programului si compilata împreuna cu el. Stubs din fiecare program sunt utilizate de catre ORB pentru a realiza comunicarea între componente. De exemplu, când o componenta este solicitata sa furnizeze un serviciu de catre ORB, stub accepta cererea de la ORB si o da componentei propriu-zise, care, dupa ce o onoreaza, returneaza rezultatele stub - ului, care le trimite apoi înspre ORB. Astfel, prin intermediul stub-urilor, se realizeaza comunicarea cu ORB, iar prin intermediul ORB, se realizeaza comunicarea în retea.
Este foarte important ca ORB sa fie implementat în acel limbaj. Java IDL este implementarea specificatiei CORBA pentru limbajul Java si permite conectarea si inter-activitatea cu obiecte heterogene. Java IDL este o implementare specifica a CORBA. Exista mai multe asemenea implementari ale CORBA în limbajul Java. Desi Java IDL nu implementeaza tot ceea ce specifica standardul CORBA, el este furnizat gratis împreuna cu platforma J2EE.
Java Mail API permite aplicatiilor sa trimita email - uri. La fel ca alte API din J2EE, Java Mail defineste un set de interfete care vor fi utilizate pentru a scrie aplicatii, folosind serviciile de mail. Aceste interfete sunt o abstractizare a serviciului de mail, astfel încât codul aplicatiei sa nu depinda de o anume implementare a serviciului de mail. Deci codul scris folosind API - ul de JavaMail este portabil atât privitor la platforme, cât si la protocoale.
XML este un standard universal de structurare a continutului electronic în documente. XML este extensibil în sensul ca, spre deosebire de HTML, tag-urile sunt nelimitate si se autodefinesc. XML este o varianta mai simpla si mai usor de utilizat a Standard Generalized Markup Language (SGML), standardadul utilizat pentru a crea structura documentelor. Standardul XML nu este afectat de problema revizuirii standardului de la o versiune la alta, deoarece nu exista tag -uri predefinite, dimpotriva tag-urile se definesc dupa nevoie. Cu alte cuvinte, XML este o metoda flexibila de definire a formatului informatiilor si de distribuire a formatului împreuna cu datele.
Platforma J2EE foloseste XML în mai multe feluri. JSP foloseste XML pentru a specifica formatul paginilor si continutul lor. XML este, de asemenea, utilizat în specificatia EJB1.1. pentru descrierea datelor utilizate la deployment-ul aplicatiilor.
J2EE include package-ul Java API for XML Processing (JAXP), care permite procesarea documentelor XML prin intermediul DOM, SAX si XSLT.
Simple API for XML (SAX) poate fi gândit ca un protocol de acces serial la XML. Acesta este un mecanism rapid, care consuma putina memorie. Acest protocol este event-driven (condus de evenimente), pentru ca tehnica este de a înregistra un handler cu un parser SAX, iar apoi parserul va invoca metodele înregistrate ori de câte ori întâlneste un nou tag de acel tip (sau întâmpina o eroare). Deci specific pentru SAX este ca tag - urile se parcurg unul dupa altul, în mod serial, fara a putea avea acces oricând la orice parte din date.
Document Object Model (DOM) se deosebeste de SAX prin aceea ca DOM converteste documentul XML într-o colectie de obiecte în cadrul programului. Acest model de obiecte poate fi manipulat în toate felurile care au vreo semnificatie. Acest mecanism este denumit random access protocol pentru ca se poate accesa orice parte din date în orice moment. Datele se pot modifica, sterge sau pot fi inserate date noi.
Comparând cele doua API se poate afirma ca SAX consuma mai putine resurse decât DOM, însa nu permite accesul în orice moment la oricare parte a datelor, asa cum permite DOM.
Extensible Stylesheet Language for Transformations (XSLT) este, în esenta, un mecanism de traducere care permite specificarea modului în care sa fie tradus un tag XML. Ca de exemplu, cum sa fie tradus un tag XML în HTML pentru a putea fi apoi afisat. Apoi se pot utiliza diferite formate XSL pentru a afisa aceleasi date în moduri diferite pentru utilizatori diferiti.
Modelul de programare J2EE permite o proiectare a aplicatiilor care sa fie scalabile, sa permita re-utilizarea componentelor. Modelul de programare J2EE are în miezul sau integrarea straturilor (tiers).
În Figura 2.9., este prezentata o posibila arhitectura de complexitate maxima, care poate fi suportata de catre aplicatiile J2EE. Se observa ca exista posibilitatea utilizarii mai multor Web Containers si EJB Containers, ceea ce face ca aplicatiile J2EE sa fie foarte scalabile.
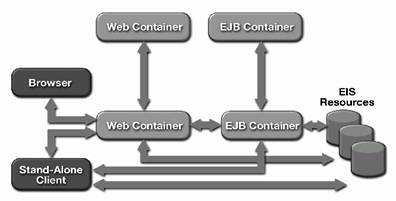
Figura 2.9. Arhitectura de complexitate maxima a unei aplicatii J2EE
Prin eliminarea unor parti din arhitectura de maxima complexitate, se obtin alte noi arhitecturi care pot fi adecvate pentru aplicatii particulare.
Figura 2.10. ilustreaza un scenariu de aplicatie în care containerul Web gazduieste componente Web dedicate, aproape în exclusivitate, pentru a realiza logica de prezentare. Furnizarea continutului dinamic Web spre client este responsabilitatea paginilor JSP si a servlet -urilor. Containerul EJB gazduieste componentele aplicatie care, pe de-o parte, raspund cererilor din Web Tier, iar pe de alta parte, acceseaza resursele Enterprise Information System. Puterea acestui scenariu sta în capacitatea de a decupla accesarea datelor de partea care realizeaza interactiunea cu clientul. Aceasta face ca aplicatia sa fie usor de modificat ulterior.
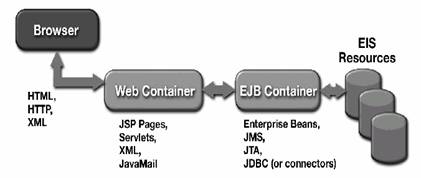
Figura 2.10. Scenariul multi tier al unei aplicatii J2EE
Trebuie mentionat ca XML este parte integranta a acestui scenariu. Avantajul major al acestui fapt este ca se adauga facilitatea de a produce si consuma mesaje XML în containerul Web. Aceasta este o metoda foarte flexibila de a trimite si primi mesaje de la mai multe tipuri de platforme. Aceste platforme pot varia de la obisnuitele XML enabled browsers la cele mai specializate rendering engines (motoare de afisare) care folosesc XML. Indiferent de domeniul aplicatiei, se considera ca datele XML vor utiliza HTTP pentru comunicare.
Apare aparenta dilema de a utiliza pagini JSP sau servlet -uri. Programarea J2EE promoveaza tehnologia JSP ca o facilitate a containerului Web. Paginile JSP se bazeaza pe functionalitatea servlet-urilor, dar modelul de programare J2EE afirma ca paginile JSP sunt mai naturale, mai usor de utilizat si realizat de catre programatorii Web. Deci Web containerul este optimizat pentru crearea continutului dinamic destinat clientilor Web, asa ca, în mod normal, se for utiliza pagini JSP si doar în mod exceptional servlet-uri.
Privind din perspectiva modelului de programare J2EE, se impune considerarea a trei tipuri de clienti stand alone:
Clienti EJB care inter actioneaza direct cu serverul EJB, de fapt cu Enterprise JavaBeans gazduite de containerul EJB. Un asemenea scenariu este ilustrat în Figura 2.11. Aici se presupune ca se utilizeaza RMI - IIOP pentru accesul la EJBs. Pentru accesul la resursele întreprinderii (de obicei baze de date), se utilizeaza JDBC, iar în viitor se vor utiliza conectorii.
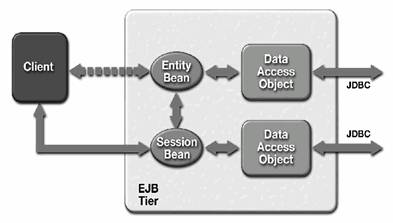
Figura 2.11. Client Java care interactioneaza direct cu EJB components
Clienti sub forma de aplicatii Java stand alone care acceseaza direct resursele întreprinderii (de obicei baze de date) folosind JDBC. În acest scenariu, logica de prezentare si logica de business sunt, prin definitie, puse pe platforma clientului si sunt integrate într-o aceeasi aplicatie. Acest scenariu elimina middle tier. De fapt, în esenta, acest scenariu este foarte asemanator cu cel al unei aplicatii client - server. Din pacate, el mosteneste si toate neajunsurile acestei arhitecturi legate de distributie, întretinere si scalabilitate.
Clienti Visual Basic care consuma continutul dinamic Web cel mai adesea sub forma de mesaje XML. În acest scenariu, containerul Web are, în principal, rolul de a trece datele sub forma de masaje XML pe care mai apoi le trimite clientilor. Logica de prezentare este lasata în seama client tier. Web Tier poate fi proiectat sa contina logica de business si sa acceseze direct bazele de date. Ideal ar fi ca logica de business sa fie totusi plasata în serverul EJB, unde s-ar putea descrie mult mai bine modelul.
Acest scenariu este ilustrat în Figura 2.12. În acest caz, Web containerul gazduieste, în esenta, atât logica de prezentare, cât si logica de business. Trebuie mentionat ca în unele implementari J2EE, cum este cea de referinta de la Sun, s-a ales sa se implementeze serverul J2EE, astfel încât cele doua containere( Web containerul si EJB containerul) sa fie integrate împreuna. Din aceasta rezulta o comunicare eficienta între cele doua containere. În acest caz, se poate considera, totusi, ca aplicatia este multi tier.
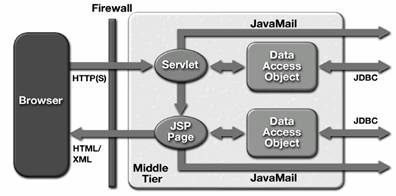
Figura 2.12. Scenariul unei aplicatii centrata în Web tier
Acest scenariu se focalizeaza pe interactiuni directe între containere. Modelul de programare J2EE propune utilizarea XML pentru a transmite mesaje utilizând protocolul HTTP ca metoda primara pentru a realiza comunicarea între Web containere. Aceasta comunicare se doreste sa fie cât mai putin "cuplata", în sensul de restrictiva. Acest scenariu este foarte potrivit pentru aplicatiile Web de comert electronic.
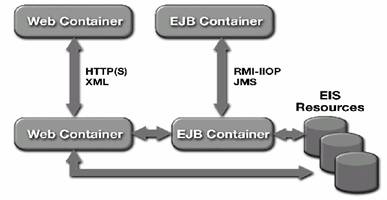
Figura 2.13. Scenariul Business to Business
Aplicatiile J2EE, indiferent de scenariul pe care îl urmeaza, pot fi realizate folosind arhitectura Model View Controller (MVC). Aceasta permite realizarea unor aplicatii care sa fie scalabile si usor de modificat si dezvoltat în continuare. Aceasta se realizeaza, in principal, datorita faptului ca se permite componentelor sa fie cât mai independente unele de altele.
Arhitectura MVC este un design pattern (tipar de proiectare) care permite divizarea functionalitatii obiectelor implicate în prezentarea datelor cu un grad de cuplaj (dependenta) cât mai mic. Aceasta arhitectura a fost initial conceputa pentru a prezenta datele în interfetele grafice standard. Aceste concepte sunt usor de mapat si în domeniul aplicatiilor enterprise multi tier bazate pe interfata Web.
În arhitectura MVC, partea de Model reprezinta datele aplicatiei si regulile care guverneaza accesul si modificarea acestor date. De cele mai multe ori, modelul reprezinta o aproximatie software a proceselor din lumea reala.
Modelul notifica partea de View atunci când apar schimbari si pune la dispozitia acestuia metode de interogare asupra starii modelului. El pune, de asemenea, la dispozitia partii de controller metode de a accesa functionalitatile aplicatiei, care vor modifica apoi datele încapsulate de catre model. Cu alte cuvinte, controller - ul nu are acces direct la datele încapsulate de Model, ci doar prin API - ul pus la dispozitie de acesta.
Partea de View afiseaza datele încapsulate de model. El acceseaza datele din model si specifica cum vor fi prezentate. Atunci când datele din model se modifica, este responsabilitatea modelului de a mentine consistenta prezentarii. Gesturile utilizatorului sunt trimise la controller.
Un controller defineste comportarea aplicatiei. El interpreteaza gesturile utilizatorului si le transpune apoi în actiuni pe care le va executa modelul. Pentru un client de tipul interfata grafica sub forma de aplicatie stand alone, gesturile utilizatorului ar putea fi selectie de meniuri si clickuri. Pentru aplicatiile Web, ele apar ca si cereri de tipul GET sau POST adresate Web Tier. Actiunile realizate de catre controller presupun inclusiv activarea proceselor de business sau schimbarea starii modelului. Bazat pe gesturile utilizatorului si pe rezultatul comenzilor date modelului, controller-ul va selecta un view pe care îl va trimite ca raspuns pentru cererea primita. Pentru fiecare set de functionalitati, exista, de obicei, câte un controller. De exemplu, pentru aplicatiile destinate managementului resurselor umane, exista un controller pentru angajati si un altul pentru personalul de resurse umane.
Interactiunile dintre Model View si Controller sunt aratate în Figura 2.14.
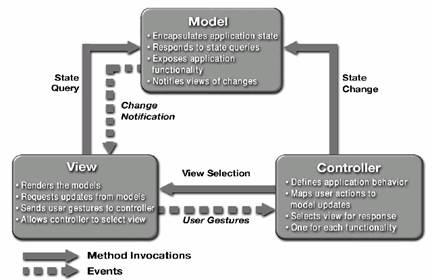
Figura 2.14. Interactiunile între Model View si Controller în cadrul unei aplicatii care respecta design patternul Model View Controller
Într-o aplicatie J2EE multi tier, Middle Tier este divizat în doua alte subtiers: Web Tier si Enterprise JavaBeans Tier. Web Tier este cel care gazduieste componentele Web (pagini JSP si servlets). Enterprise JavaBeans Tier este cel care gazduieste componentele enterprise, cele care contin logica de business, serviciile la nivel de sistem ca si managementul tranzactiilor, controlul concurentei si securitatea. Tehnologia Enterprise JavaBeans furnizeaza un model de componenta distribuita, care permite utilizatorilor sa se focalizeze pe rezolvarea problemelor de business, iar restul de probleme la nivel de sistem sunt lasate în seama platformei J2EE. Aceasta separare de roluri permite dezvoltarea rapida a unor aplicatii scalabile, accesibile si foarte sigure. În modelul de programare J2EE, componentele Enterprise JavaBeans constituie legatura fundamentala dintre componentele gazduite de Web Tier si datele sau sistemele critice aflate în Enterprise Information Tier.
Probabil ca termenul care înca a ramas pâna acum o necunoscuta si fara de care nu poate fi înteles rolul EJB, este logica de business (Business Logic). O definitie ar putea fi aceasta: "Logica de business, într-un sens foarte larg, este un set de reguli utilizate pentru a realiza o anume functie de business (functie necesara pentru întreprindere)". (Blueprints, 2000)
Folosind o abordare obiectuala, utilizatorul poate sa descompuna o functie de business într-un set de componente numite business objects (obiecte de business).Ca orice alte obiecte, aceste obiecte de business vor avea caracteristici (stare sau date) si comportare. De exemplu, un obiect de tipul angajat va avea date ca nume, prenume, adresa, data angajarii, data nasterii etc. Va avea, însa, si metode de asignare la un nou departament sau de schimbare a salariului cu un anume procentaj. Pentru a rezolva aceasta problema de business, va trebui sa reprezentam modul de functionare al acestor obiecte si de interactiune între ele pentru a obtine functionalitatea dorita. Regulile de business specifice, care ne ajuta în a identifica structura si comportamentul acestor obiecte de business, împreuna cu pre conditiile si post conditiile care trebuie sa fie îndeplinite atunci când obiectul îsi expune comportarea celorlalte obiecte din sistem, poarta numele de logica de business.
Prima cerinta impusa unui obiect de business este de a mentine starea reprezentata de variabilele instantiate între apelurile metodelor. Starea poate fi conversationala sau persistenta.
Pentru a întelege starea conversationala, se considera exemplul unui cos de cumparaturi virtual. Starea cosului este reprezentata de lucrurile luate si cantitatea lor. Cosul este initial gol si va avea vreo stare care sa însemne ceva atunci când cumparatorul (evident si el virtual) va adauga ceva în el. Atunci când cumparatorul adauga un alt lucru în cos, el va trebui sa contina ambele lucruri. La fel, atunci când sterge ceva din cos, acesta trebuie sa reflecte schimbarea din starea sa. Atunci când utilizatorul paraseste aplicatia, obiectul cos trebuie sa fie reinitializat. Atunci când un obiect câstiga, mentine si apoi îsi pierde starea ca rezultat al interactiunilor repetate cu acelasi client, se spune ca obiectul îsi mentine starea conversationala.
Pentru a întelege starea persistenta, se va lua exemplul unui cont într-o aplicatie. Atunci când utilizatorul creeaza un cont, informatia trebuie sa fie stocata permanent, pentru ca, atunci când utilizatorul paraseste aplicatia si apoi reintra, sa poata regasi informatia legata de contul sau. Starea unui obiect cont trebuie sa fie mentinuta pe un mediu persistent, pe o baza de date. În mod obisnuit, obiectele de business care opereaza asupra datelor care nu sunt legate de sesiunea cu clientul, vor prezenta stare persistenta.
O alta cerinta pe care trebuie sa o îndeplineasca obiectele de business este sa opereze asupra unor date partajate. În acest caz, trebuie luate masuri pentru a avea control concurent si diferite nivele de izolare a datelor partajate. Un exemplu este situatia când mai multi utilizatori modifica aceleasi informatii concomitent.
Una dintre cele mai importante cerinte impuse obiectelor de business este sa poata participa în tranzactii. Mai întâi însa, ar trebui sa definim termenul de tranzactie. O tranzactie este un set de taskuri care trebuie executate ori toate împreuna, ori nici unul. Daca unul dintre taskuri nu este executat, toate taskurile vor fi rolled back (derulate înapoi) si se revine la starea din care s-a plecat înainte de executarea primului task. Daca, însa, reusesc toate taskurile, atunci se spune ca tranzactia este committed (realizata) si se salveaza noua stare.
Obiectele de business trebuie sa participe în tranzactii. De exemplu, realizarea unei comenzi de materiale la o firma trebuie sa fie tranzactionala, deoarece exista un set de taskuri care este necesar sa fie realizate pentru ca respectiva comanda sa reuseasca (decrementarea cantitatii de produse ce au mai ramas în magazie, stocarea detaliilor comenzii, trimiterea unei confirmari de preluare a comenzii la clientul solicitant ). Daca oricare dintre aceste taskuri nu reuseste atunci modificarile realizate de taskurile anterioare devin incorecte, motiv pentru care trebuie sa fie derulate înapoi.
În multe operatii de business, tranzactiile se pot întinde pe mai mult de o sursa de date distanta. Asemenea tranzactii, denumite tranzactii distribuite, au nevoie de protocoale speciale pentru a asigura integritatea datelor.
O alta cerinta importanta, care se impune obiectelor de business, este sa deserveasca un numar mare de clienti în acelasi timp. Aceasta se traduce în necesitatea, de exemplu, de a se utiliza algoritmi care vor da fiecarui client impresia ca un anume obiect de business dedicat este disponibil sa-i execute cererea. Fara un asemenea mecanism, sistemul ar putea sa se blocheze, deci nu va mai fi capabil sa serveasca alti clienti.
Este necesar, de asemenea, ca EJB sa furnizeze acces distant la date. Un client trebuie sa fie capabil sa acceseze de la distanta serviciile oferite de un anume obiect de business. Aceasta înseamna ca obiectul de business ar trebui sa aiba o infrastructura care sa-i permita sa deserveasca clientii prin retea. Aceasta, în schimb, implica faptul ca un obiect de business trebuie sa fie parte dintr-un mediu distribuit, care sa se ocupe de chestiuni fundamentale legate de sistemele distribuite, ca de exemplu localizarea.
O alta cerinta ce se impune obiectelor de business este controlul accesului. Serviciile oferite de obiectele de business de multe ori necesita un mecanism de autentificare si de autorizare pentru a permite unui anume set de clienti sa acceseze serviciile protejate. De exemplu, un obiect de business care reprezinta contul bancar al unui client trebuie neaparat sa faca autentificarea clientului, înainte de a permite clientului sa modifice informatia din contul bancar. În multe scenarii de aplicatii enterprise, sunt necesare mai multe nivele de control al accesului. De exemplu, oricarui angajat i se permite doar sa poata citi datele din obiectele de business de tip salariu, pe când unui administrator al departamentului economic i se permite si sa modifice obiectele de tip salariu.
Ultima, dar nu cea mai neînsemnata cerinta ce se impune obiectelor de business, este ca trebuie sa poata fi reutilizate în acea aplicatie de la o versiune la alta a ei sau de catre alte aplicatii. De exemplu, o aplicatie a departamentului de contabilitate poate sa stocheze datele referitoare la salariile angajatilor folosind doua obiecte : angajat si salariu. Obiectul de business de tip angajat va utiliza obiectul de business de tip salariu pentru a afla care este valoarea salariului acelui angajat. O aplicatie care va gestiona posibilitatile de a pleca în concediu ale angajatilor va utiliza obiectul de tip angajat pentru a obtine numele si prenumele angajatului. Pentru ca obiectele de business sa fie componente utilizabile inter si intra aplicatii, ele au nevoie sa fie dezvoltate în maniera standard si sa ruleze în medii unde se dispun tot de facilitati standard. Daca standardele sunt bine definite si acceptate pe piata, atunci se va ajunge la realizarea de aplicatii, folosind componente cumparate de la mai multi providers, iar munca necesara va fi doar de asamblare a diferitelor componente în cadrul aplicatiei. Aceasta va permite dezvoltarea foarte rapida a aplicatiilor.
Obiectele de business furnizeaza clientilor unele servicii generice, ca de exemplu suport pentru tranzactii, securitate si acces la distanta. Aceste servicii comune sunt, de fapt, în natura lor, foarte complicate, dar sunt implementate la nivel de platforma, iar utilizatorul nu trebuie sa implementeze nimic pentru a dispune de acele servicii. Pentru a simplifica dezvoltarea aplicatiilor enterprise, componentele au nevoie de o infrastructura standard de partea serverului care sa le furnizeze serviciile.
EJB Tier, din platforma standard J2EE, furnizeaza un model de componenta distribuita standard de partea serverului, care simplifica mult taskul de a scrie logica de business. În arhitectura EJB, expertii sistemului furnizeaza un cadru pentru a oferi servicii la nivel de sistem, iar expertii în domeniul aplicatiei vor furniza componente care vor contine doar informatii legate de partea de business a aplicatiei. Platforma J2EE permite programatorilor enterprise sa se concentreze pe rezolvarea problemelor întreprinderii, în loc sa se lupte cu probleme de nivel de sistem.
Pentru a utiliza serviciile furnizate de platforma J2EE, obiectele de business sunt implementate ca si componente EJB sau enterprise beans. Exista doua tipuri majore de enterprise beans: entity beans si session beans. Session beans sunt destinate sa fie resurse private, folosite doar de clientii care le-au creat. Din acest motiv, session beans, privite din perspectiva clientului, apar ca anonime. În contrast, fiecare entity bean are o identitate unica, care este expusa sub forma de cheie primara.
În plus fata de componentele enterprise beans, arhitectura EJB defineste alte trei entitati: servere, containere, si clienti. Enterprise JavaBeans traiesc în interiorul unor containere EJB care furnizeaza o multime de servicii, inclusiv gestiunea ciclului de viata. Un container EJB este o parte a unui server EJB care furnizeaza serviciile de naming and directory, email, tranzactii, securitate, etc. Atunci când un client invoca o operatie asupra unei enterprise bean, apelul este interceptat de catre container. Prin intercalarea containerului între client si componente la nivelul apelului, containerul poate realiza servicii care se propaga dincolo de apelurile metodelor componentelor si chiar dincolo de containerele care functioneaza pe diferite servere sau pe masini diferite. Acest mecanism simplifica dezvoltarea atât a aplicatiilor, cât si a clientilor.
Arhitectura EJB înzestreaza enterprise beans si containerele EJB cu multe trasaturi unice care vor permite portabilitatea si reutilizarea:
Instantele enterprise beans sunt create si gestionate de catre container la runtime. Daca un enterprise bean foloseste doar servicii definite în specificatiile EJB, atunci acel enterprise bean poate fi utilizat în cadrul oricarui container care respecta standardul EJB. Containere specializate pot furniza servicii aditionale fata de cele specificate în specificatia EJB. Un enterprise bean care depinde de asemenea servicii poate fi utilizat în cadrul oricarui container care furnizeaza acele servicii.
Comportarea unui enterprise bean nu este continuta în totalitate în implementarea sa. Serviciul de tranzactii si serviciul de securitate sunt separate de implementarea enterprise bean. Aceasta permite ca serviciile acestea sa fie configurate la deployment (faza în care se adapteaza aplicatia la platforma si se configureaza anumiti descriptori utilizati de platforma). Aceasta face posibila includerea de enterprise beans într-o aplicatie gata asamblata, fara a fi necesara modificarea codului sursa sau recompilarea.
Providerul de componente defineste o vedere a clientului asupra enterprise beans. Aceasta vedere a clientului asupra enterprise beans nu este afectata în nici un fel de container sau de serverul în care aplicatia este plasata. Aceasta asigura ca atât enterprise beans, cât si clientii lor pot fi plasati în mai multe medii de executie, fara a necesita recompilare. Perspectiva clientului asupra unei enterprise bean este concretizata în doua interfete. Aceste interfete sunt implementate prin clase construite de catre container la deployment - ul bean - ului, bazat pe informatiile furnizate de catre bean. Tocmai prin implementarea acestor interfete, se realizeaza intercalarea containerului între componenta si clientul ei la apelul de functii.
Cele doua interfete care trebuie implementate se numesc Home si Remote interfaces, iar componenta este clasa enterprise bean. Acestea trei vor fi detaliate în continuare.
Clasa Enterprise Bean contine detaliile de implementare ale componentei. In aceasta clasa sunt, de fapt, implementate metodele de business ale bean - ului. Aceasta este o clasa Java obisnuita, care se conformeaza unei interfete bine definite si respecta anumite reguli. Aceasta clasa trebuie sa implementeze interfata javax.ejb.EntityBean, daca componenta este de tipul entity bean sau javax.ejb.SessionBean, daca este de tipul session bean.
Orice trebuie sa implementeze interfata javax.ejb.EnterpriseBean, deoarece ambele interfete de mai sus o extind pe aceasta. Interfata aceasta este prezentata în continuare. Aceasta interfata are rolul de a arata ca respectiva clasa care o implementeaza este un enterprise bean. Interesant este ca ea extinde java.io.Serializable, aceasta însemnând ca orice enterprise bean poate fi serializat, adica poate fi stocat si transmis prin retea ca un sir de biti din care poate fi refacut.
|
Interfata javax.ejb.EnterpriseBean |
| public interface javax.ejb.EnterpriseBean extens java.io.Serializable |
Atunci când un client doreste sa foloseasca o instanta a unei clase enterprise bean, el nu va invoca niciodata în mod direct instanta clasei, ci apelul este interceptat de containerul EJB si este delegat apoi instantei clasei enterprise bean. Aceasta se face în acest fel din mai multe motive:
Clasa enterprise bean nu poate fi invocata direct prin retea, deoarece ea nu este prevazuta cu mecanisme de acces la retea. Containerul EJB este cel care se ocupa de interactiunea cu reteaua, înfasurând clasa bean cu un obiect care este prevazut cu mecanisme de acces la retea (network enabled). Acest obiect network enabled primeste apelurile de la clienti si le deleaga instantei clasei enterprise bean. Din acest motiv, programatorul nu trebuie sa se mai preocupe de legarea la retea si sa scrie cod RMI sau RMI-IIOP. Serviciul de networking este pus la dispozitie de catre container.
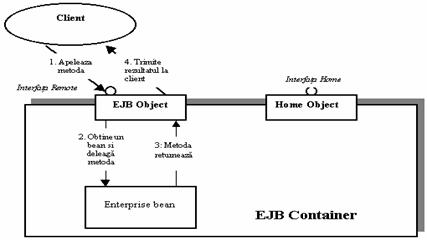
Prin
interceptarea cererilor containerul EJB poate realiza în mod automat unele
operati de management cum ar fi: tranzactiile, securitatea,
implementarea mecanismului de pooling
s.a.
Figura 2.15. Obiectul EJB si apelul unei metode a Enterprise Bean
Astfel, containerul EJB actioneaza ca un indirection layer (nivel de redirectare) între codul clientului si bean. Acest nivel se concretizeaza într-un singur obiect, care dispune de mecanisme de acces la retea si este denumit EJB object. Obiectul EJB este un obiect inteligent care, în plus, este capabil de tranzactii, securitate si realizarea logicii intermediare pe care o necesita containerul EJB înainte de a realiza apelul metodelor obiectului enterprise bean. Un obiect EJB actioneaza ca o punte între client si bean si expune fiecare metoda pe care o pune la dispozitie obiectul enterprise bean. Obiectele EJB deleaga toate cererile clientului la obiectele enterprise beans.
Asa cum s-a mentionat mai devreme, clientii unui bean invoca metode asupra obiectelor EJB si nu asupra obiectelor enterprise beans. Pentru ca sa realizeze aceasta, obiectele EJB trebuie sa cloneze fiecare metoda pe care o expune bean - ul si sa o expuna si el. Dar de unde stiu uneltele care genereaza automat obiectele EJB ce metode sa cloneze? Raspunsul este ca exista o interfata speciala pe care programatorul trebuie sa o scrie, în care se specifica metodele pe care le expune enterprise bean - ul. Aceasta interfata este denumita Remote interface.
Interfetele Remote trebuie sa respecte anumite reguli pe care le defineste specificarea EJB. De exemplu, fiecare interfata Remote extinde interfata javax.ejb.EJBObject pusa la dispozitie de Sun Microsystems. Explicarea metodelor din aceasta interfata se poate observa în Tabelul 2.1.
Pe lânga aceste metode din Tabelul 2.1., interfata Remote trebuie sa contina si metodele de business ale bean - ului. Codul clientului care doreste sa lucreze cu enterprise bean - ul va lucra, de fapt, cu un obiect ce implementeaza interfata javax.ejb.EJBObject.
|
Interfata javax.ejb.EnterpriseBean |
|
public interface javax.ejb.EJBObject extens java.rmi.Remote |
|
getEJBHome() |
Obtine o referinta la Home object (va fi explicat imediat) |
|
getPrimaryKey() |
Returneaza cheia primara a acestui obiect EJB (doar entity beans au primary key) |
|
remove() |
Distruge acest obiect EJB, iar pentru entity beans sterge si din mediul persistent |
|
getHandle() |
Obtine un handle la acest obiect EJB. Un EJB handle este o referinta persistenta la un obiect EJB pe care clientul o poate tine minte si apoi reutiliza mai târziu pentru a obtine obiectul EJB. |
|
isIdentical() |
Testeaza daca doua obiecte EJB sunt identice |
Tabelul 2.1. Metodele pe care trebuie sa le expuna toate obiectele EJB
Dupa cum s-a vazut deja, codul clientului acceseaza obiecte EJB si nu ajunge niciodata sa acceseze direct bean - urile. Urmatoarea întrebare logica este cum obtin atunci clientii referinte la obiectele EJB?
Clientul nu poate instantia direct un obiect EJB, deoarece obiectele EJB s-ar putea sa se afle pe alta masina decât cea pe care se afla clientul. Pe de alta parte, tehnologia EJB propune transparenta fata de locul unde se afla obiectele EJB, astfel încât clientii sa nu fie nevoiti sa stie unde rezida obiectele EJB.
Pentru a obtine o referinta la un obiect EJB, clientul este nevoit sa îl solicite de la un EJB object factory. Aceast object factory este responsabil de instantierea si distrugerea obiectelor EJB. În specificarea EJB, acest object factory este denumit home object. Îndatoririle cele mai importante ale obiectelor home sunt urmatoarele:
Sa creeze obiecte EJB
Sa permita gasirea obiectelor EJB existente (aceasta se întâlneste la entity beans si va deveni mai clar în curând)
Sa stearga obiectele EJB
La fel ca obiectele EJB, obiectele home sunt specifice fiecarui container, fac parte din acesta si sunt generate folosind uneltele specifice acelui container.
Acum ca s-a vazut ca obiectul Home este factory pentru obiectul EJB, se pune întrebarea de unde stie obiectul Home cum sa initializeze obiectul EJB ? De exemplu, un obiect EJB s-ar putea sa expuna o metoda de initializare care primeste un întreg ca parametru, în vreme ce alt obiect EJB s-ar putea sa ia un String. Containerul are nevoie sa cunoasca aceste informatii pentru a genera obiectele home. Aceste infrmatii sunt furnizate containerului prin intermediul home interface. Interfetele home definesc metode de creare, distrugere si gasire a obiectelor EJB. Obiectul Home a containerului implementeaza interfata home specificata de programator. Aceasta se poate observa si în Figura 2.16.
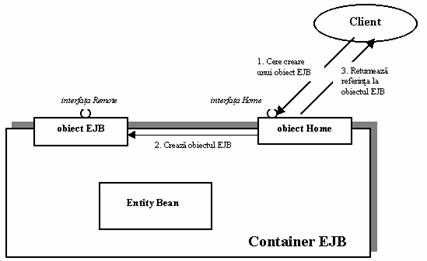
Figura 2.16. Obiectul Home
Specificatia EJB defineste câteva metode pe care trebuie sa le suporte orice interfata home. Aceste metode sunt definite de interfata javax.ejb.EJBHome pe care toate interfetele trebuie sa o extinda. Continutul acestei interfete este:
|
Interfata javax.ejb.EJBHome |
|
public interface javax.ejb.EJBHome extens java.rmi.Remote |
Se poate observa ca javax.ejb.EJBHome deriva din java.rmi.Remote. Aceasta înseamna ca home objects sunt prevazute cu posibilitati de acces la retea, folosind Java RMI care poate realiza comunicarea între masini virtuale diferite. De aceea, tipurile parametrilor metodelor specificate în home interface trebuie sa fie valide pentru Java RMI. De fapt, este suficient sa implementeze interfata java.io.Serializable.
Deployment descriptors permit containerelor sa furnizeze middleware services pentru componentele EJB. Un middleware service este un serviciu de care bean - urile pot beneficia în mod automat, fara ca programatorul sa fie nevoit sa scrie cod.
Pentru ca sa poata fi informat containerul de serviciile de care are nevoie componenta, trebuie sa se specifice cererile de middleware services în fisierul deployment descriptor. De exemplu, se poate utiliza un deployment descriptor pentru a specifica cum trebuie sa gestioneze containerul ciclul de viata, persistenta, controlul tranzactiilor, serviciile de securitate. Containerul va utiliza acesti descriptori pentru a configura serviciile dorite.
În specificarea EJB 1.0, un deployment descriptor este un obiect serializabil. Crearea deployment descriptors este automatizata de catre EJB container tools sau Java Development Environment tools. De exemplu, s-ar putea ca într-un IDE sa se parcurga pur si simplu un wizard cu câteva întrebari, iar apoi IDE sa genereze singur deployment descriptor. Din acest motiv, nici nu vom insista pe acesti descriptori. Ceea ce trebuie retinut este ca, pentru a beneficia de un serviciu middleware de la platforma J2EE, este nevoie ca acesta sa fie configurat corespunzator. Aceasta configurare se poate face usor folosind uneltele puse la dispozitie de server, container sau IDE.
Specificarile EJB 1.0 si EJB 1.1 definesc doua tipuri diferite de enterprise beans: session beans si entity beans.
Session beans sunt componente care au durata de viata egala cu cea a sesiunii cu clientul care o utilizeaza. De exemplu, daca un client contacteaza un session bean pentru a realiza functia de bussiness de introducere a unei noi comenzi, serverul EJB este responsabil de crearea unei instante a acelei componente session bean. Atunci când clientul se va deconecta, serverul EJB va distruge acea instanta a session bean - ului. Session beans sunt utilizabile de catre un singur client la un moment dat, cu alte cuvinte session beans nu sunt partajate de mai multi clienti.
La rândul lor, session beans sunt de doua tipuri: statefull session beans si stateless session beans.
Un statefull session bean este proiectat sa deserveasca procese de business care se întind pe mai multe apeluri de metode sau chiar tranzactii. Pentru a realiza aceasta, statefull session beans vor mentine starea de partea clientului. Daca starea unui statefull session bean se modifica în timpul apelului unei metode, aceeasi stare va fi disponibila clientului la urmatorul apel de metoda.
Un exemplu de statefull session bean este cazul unui magazin pe Web. Pe masura ce clientul se "plimba" prin magazin, va adauga produse în cosul de produse, va scoate unele si va pune altele etc. Acesta este un exemplu de proces de business care se întinde pe durata mai multor apeluri de metode. Componenta cos de produse trebuie sa îsi pastreze ultima stare de la un apel de metoda la altul, de aceea ea va fi modelata ca session bean.
Unele procese de business, în mod natural, pot fi modelate dupa paradigma unei singure cereri. În cadrul unui asemenea proces, nu este nevoie ca sa se pastraze starea de la un apel de metoda la altul. Aceste procese sunt modelate cu stateless session beans. Acestea sunt furnizori anonimi de metode, deoarece nu cunosc istoria clientului.
Un exemplu de stateless session bean este cel al unei componente care realizeaza operatii matematice complexe asupra intrarii, ca de exemplu compresia datelor audio sau video. Clientul poate furniza datelele necomprimate într-un buffer, împreuna cu factorul de compresie dorit. Componenta va realiza compresia si va returna tot un buffer, dar cu datele comprimate. Dupa aceasta, componenta poate deservi si orice alt client, deoarece nu are nevoie sa retina nici un fel de date referitoare la clientul pe care tocmai l-a deservit, cu alte cuvinte nu are nevoie sa retina informatii legate de starea clientului.
Entity beans sunt componente care reprezinta date persistente, ca de exemplu conturi bancare, stocuri, etc. Datele prezentate de entity beans sunt, de obicei, stocate în baze de date. Entity beans sunt utilizate pentru a modela datele si nu sunt proiectate pentru a contine logica de business. Session beans sunt cele care vor realiza logica de business. Entity beans furnizeaza o vedere obiectuala asupra datelor aflate într-un mediu de stocare, ca de exemplu o baza de date. Metoda traditionala, în care aplicatiile manipuleaza datele, este de a citi si scrie dupa nevoie datele din tabelele unei baze de date relationale. Entity beans sunt o reprezentare obiectuala a acestor date.
Un exemplu de entity bean ar putea fi cel al unui cont bancar. Toate datele din baza de date care tin de contul bancar al unui anume client sunt reprezentate de un entity bean. Acest bean poate fi manipulat prin apelul metodelor pe care le expune. De exemplu, se poate realiza operatia de retragere de numerar folosind metoda withdraw(), care va modifica o variabila numita balance (sold). Când se solicita bean - ului sa stocheze datele în baza de date, se va realiza modificarea si în tabelele bazei de date, astfel încât aceasta sa contina noul sold.
Deoarece entity bean modeleaza date permanente, ele au o durata mare de viata. Ele supravietuiesc în cazul unor caderi majore, ca de exemplu caderea serverului sau defectarea unei masini, datorita faptului ca pot fi reconstruite prin simpla citire a datelor din baza de date. Deoarece baza de date supravietuieste caderilor, si aceste componente vor supravietui. Aceasta este cea mai mare diferenta între session beans si entity beans. Entity beans au un ciclu de viata mult mai mare decât durata session beans, deoarece session beans au durata de viata egala cu durata sesiunii cu clientul, pe când entity beans pot dura ani de zile, durata lor de viata fiind egala cu cea a datelor pe care le reprezinta din baza de date.
O alta diferenta majora între entity beans si session beans este ca entity beans pot fi utilizate de mai multi clienti în mod simultan. Cu alte cuvinte, mai multi clienti pot manipula datele din baza de date simultan. Aceasta se realizeaza prin intermediul tranzactiilor, aspect care va deveni mai clar în subcapitolele care urmeaza.
Dupa cum tocmai s-a mentionat, session beans au fost proiectate pentru a reprezenta procese de business (orice actiune care necesita logica, algoritmi). Exemple concrete de procese de business includ verificarea validitatii unui credit card, realizarea unei comenzi pentru produse, realizarea unor calcule, etc.
Cea mai mare diferenta dintre session beans si entity beans este durata lor de viata. În vreme ce entity beans au o durata de viata egala cu cea a datelor din baza de date pe care le reprezinta, session beans, dupa cum arata si numele, au o durata de viata egala cu a sesiunii cu clientul.
Durata sesiunii cu clientul poate fi egala cu cea în care este deschisa fereastra browserului, când acesta e conectat la o aplicatie care utilizeaza session beans sau, poate în alt caz, egala cu cea în care appletul Java ruleaza. O caracteristica interesanta este faptul ca ele pot fi distruse de containerul EJB atunci când expira timpul de lucru cu clientul. Daca codul clientului utilizeaza bean - ul timp de 10 minute, atunci timpul de viata ar putea fi setat pe server la aproximativ o jumatate de ora, dar nu la zile sau saptamâni. Session beans traiesc doar în memorie, motiv pentru care nu pot supravietui caderilor serverului sau ale masinii. Session beans sunt nepersistente (nonpersistent), deoarece ele nu sunt salvate în mediu persistent.
Toate tipurile de enterprise beans mentin conversatii cu clientii mai mult sau mai putin. O conversatie este o interactiune dintre client si bean. Ea este compusa dintr-un apel succesiv de metode între client si bean. O conversatie se întinde de-a lungul unui proces de business pentru client, ca de exemplu configurarea unui comutator ATM sau cumpararea de bunuri de pe internet sau introducerea datelor despre un nou client.
Un stateless session bean este un bean care mentine o conversatie de durata unui singur apel de metoda. Acest bean nu are stare (este stateless), fiindca nu trebuie sa mentina nici o informatie de la un apel de metoda la altul. Dupa un apel de metoda, un stateless session bean pierde toata informatia legata de acel apel de metoda si este disponibila pentru un nou apel. Cu alte cuvinte, orice instanta a unui stateless session bean poate deservi orice client, deoarece oricum ea nu mentine informatii legate de clientii care au apelat-o în trecut. Aceasta înseamna ca stateless session beans pot fi, cu usurinta, reutilizate de mai multi clienti. Aceasta se poate observa în Figura 2.17.
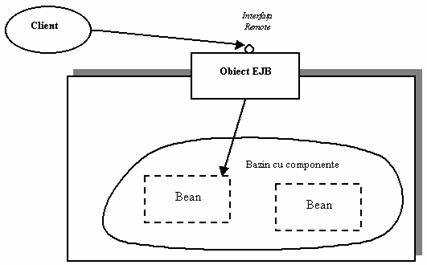
Figura 2.17. Modul de utilizare al stateless session beans
Pentru a scrie o clasa care sa reprezinte un session bean trebuie implementa interfata javax.ejb.SessionBean. Aceasta interfata defineste câteva metode care sunt utilizate de catre containerul EJB pentru a anunta bean - ul de anumite evenimente importante. Clientii bean - ului nu vor apela niciodata aceste metode, deoarece ele sunt disponibile clientilor via obiectul EJB. Interfata javax.ejb.SessionBean este expusa în continuare.
|
Interfata javax.ejb.SessionBean |
|
public interface javax.ejb.EJBHome extens javax.ejb.EnterpriseBean |
Metoda setSessionContext(SessionContext ctx) este utilizata de catre container pentru a asocia bean - ului un session context. Un session context este poarta de interactiune a bean - ului cu containerul. O implementare tipica de bean va pastra contextul într-o variabila membru, pentru a o utiliza mai târziu,când va fi necesar. Enterprise beans mai avansate au nevoie sa afle date despre starea în care se afla la runtime. Aceasta include:
Informatii despre obiectul Home sau EJB al bean - ului
Informatii despre tranzactiile curente în care este implicat bean - ul. Acestea ar putea ajuta bean - ul, de exemplu, sa sara anumiti pasi de calcul care nu sunt necesari în cazul în care tranzactia oricum nu a reusit.
Informatii de securitate pentru autentificarea clientului. Un bean poate sa interogheze mediul în care se afla, daca clientul are nivelul de drepturi necesar pentru a realiza o anumita operatiune.
Metodele ejbCreate (...) initializeaza session bean - ul. Se pot defini mai multe metode ejbCreate(...) care pot primi diferite argumente. Aceasta permite clientilor sa initializeze bean - urile în mai multe moduri. Deoarece se pot defini propriile metode ejbCreate(), care au propriul lor set de parametrii pe care-i primesc la apel, nu este plasata metoda ejbCreate() în interfata javax.ejb.SessionBean. Trebuie observat ca este necesara implementarea a cel putin o metoda ejbCreate() în session bean pentru ca sa existe cel putin o metoda de initializare a bean - ului.
Metoda ejbCreate() implementata în codul bean - ului trebuie sa realizeze toate initializarile de care are acesta nevoie, ca de exemplu setarea variabilelor membru cu valorile primite prin apelul metodei. Aceasta reiese din Exemplul 2.1.
|
Exemplu 2.1. O metoda ejbCreate |
| import javax.ejb.*; public class FirstBean implements SessionBean |
Metodele de tipul ejbCreate() sunt invocate de container si niciodata direct de clienti. Dar clientii trebuie sa dispuna de metode de a trimite parametrii la metodele ejbCreate(), fiindca ei sunt aceia care furnizeaza valorile de initializare. Interfata home este cea pe care o apeleaza clientii la initializarea bean - ului. Din acest motiv, trebuie ca fiecare metoda de tipul ejbCreate() din bean sa aiba un corespondent in interfata home.
De exemplu, daca în cadrul bean - ului este declarata metoda:
public void ejbCreate(int i),
trebuie sa fie pusa în interfata Home urmatorarea metoda:
public void create(int i).
Trebuie observat ca în interfata Home nu mai apare prefixul "ejb". Când un client apeleaza metoda create(int i) asupra interfetei Home, parametrii sunt pasati metodei ejbCreate() din bean.
Metoda ejbPassivate este apelata de container atunci când sunt instantiate prea multe bean - uri si apare pericolul de a avea putine resurse. Când se ajunge în aceasta stare, containerul poate pasiva (passivate) unele dintre bean - uri, în sensul ca le salveaza temporar într-un mediu de stocare, ca de exemplu o baza de date sau un sistem de fisiere. Aceasta este posibila datorita faptului ca bean - urile sunt serializabile. Înainte de pasivizare, containerul apeleaza metoda ejbPassivate(), astfel anuntând bean - ul sa elibereze orice resurse sistem pe care le detine, ca de exemlu socket - uri sau conexiuni la baze de date. Observati Exemplul 2.2.
|
Exemplul 2.2. O metoda ejbPassivate |
|
import javax.ejb.*; public class FirstBean implements SessionBean |
De remarcat ca în cazul stateless session beans nu se aplica pasivizarea, pentru ca aceste bean - uri nu pastreaza starea si pot fi create/distruse pur si simplu, nefiind necesar mecanismul de activare/pasivizare.
Atunic când un client are nevoie sa utlizeze un bean care a fost pasivizat, apare procesul invers: containerul aduce bean - ul din mediul de stocare înapoi în memorie si apoi îl activeaza. Imediat ce bean - ul a fost activat, acesta va apela metoda ejbActivate(), la apelul careia bean - ul obtine toate resursele de care are nevoie. Aceste resurse sunt, de obicei, cele care au fost eliberate la pasivizare. Un exemplu pentru activarea unui bean este Exemplul 2.3.
|
Exemplul2.3. O metoda ejbActivate |
|
import javax.ejb.*; public class FirstBean implements SessionBean |
Ca si în cazul pasivizarii, nu este necesara implementarea mecanismului de activare pentru stateless session beans, deoarece se foloseste mecanismul de creare/distrugere.
Atunci când containerul este pe punctul de a distruge o instanta a unui bean, el va apela metoda ejbRemove() a bean - ului. ejbRemove() este o metoda de a anunta bean - ul ca este pe punctul de a fi distrus si de a-i permite sa-si încheie existenta asa cum considera. Aceasta metoda este necesara pentru toate bean - urile si nu primeste parametrii, motiv pentru care este doar un per bean, spre deosebire de ejbCreate() care sunt mai multe. Implementarea metodei ejbRemove() trebuie sa pregateasca bean - ul pentru distrugere, eliberând toate resursele pe care le-a ocupat. Containerul poate apela metoda ejbRemove() în orice moment, inclusiv în cazurile în care containerul decide ca timpul de viata al bean - ului a expirat.
Pe lânga metodele pe care le-am descris pâna acum si care sunt apelate doar de container pentru a gestiona bean - ul, mai exista metodele de business (business methods). Aceste metode sunt cele care rezolva, de fapt, problemele de business, ca în Exemplul 2.4.:
|
Exemplul 2.4. O metoda de business |
| import javax.ejb.*; public class FirstBean implements SessionBean |
Pentru ca un client sa poata invoca o anume metoda de business, aceasta trebuie sa fie declarata în interfata Remote.
Privind si din partea clientului, acesta încerca sa rezolve probleme concrete prin utilizarea unuia sau mai multor beans. Un client trebuie sa urmeze mai multi pasi în rezolvarea unei probleme, folosind un bean. În primul rând, el trebuie sa obtina obiectul Home, apoi sa creeze un obiect EJB , sa apeleze ce metode are nevoie folosind interfata Remote si la urma sa îl distruga.
Pentru a obtine obiectul Home, trebuie ca, în codul clientului, sa se utilizeze Java Naming and Directory Interface (JNDI).
În proiectarea J2EE, s-a avut în vedere transparenta locatiei (location transparency). Aceasta înseamna ca modul în care este scris codul nu trebuie sa depinda de modul cum sunt distribuite bean - urile pe nivele (tiers) sau pe ce masini sunt acestea plasate. Aceasta transparenta este castigata prin intermediul serviciului de naming and directory. Acest serviciu are rolul de a stoca si gasi resurse în retea. Exemple de servicii de naming and directory sunt Active Directory de la Microsoft sau Lotus Notes de la IBM.
În mod traditional, corporatiile au folosit serviciile de directory pentru a stoca numele utilizatorilor si parolele, locatia unde se gasesc masinile sau imprimantele etc. Produsele J2EE exploateaza serviciile de directory pentru a stoca informatii în legatura cu resursele pe care aplicatia le foloseste. Aceste resurse pot fi obiecte home EJB, proprietati ale mediului enterprise bean, drivere de baze de date sau orice alte resurse foloseste bean -ul. Acestea toate fac codul EJB independent de configuratia resurselor, fiindca mai târziu, daca una dintre resurse este mutata, nu este nevoie sa se efectueze vreo modificare în cod, pentru ca se poate, pur si simplu, modifica directory service ca sa arate noua locatie a resurselor. Aceasta trasatura, transparenta locatiei, este foarte valoroasa atunci când se fac modificari în privinta locatiei resurselor, dar este necesara mai ales când se cumpara componente gata realizate.
Pentru a putea gasi o resursa în cazul unei aplicatii J2EE, este necesara parcurgerea a doi pasi:
Fiecarei resurse sa i se asocieze un identificator, iar containerul va asocia identificatorul cu resursa
Clientii vor folosi identificatorul asociat resursei si JNDI pentru a gasi resursa respectiva
Pentru a avea transparenta locatiei în cazul obiectelor Home, containerele EJB mascheaza locatia efectiva a obiectelor Home în codul clientului. Clientii nu vor utiliza numele masinii pe care rezida obiectele, ci vor utiliza serviciile JNDI pentru a gasi acele obiecte. Obiectele Home sunt localizate undeva pe retea, cel care dezvolta un bean nu se preocupa de locatia ce o avea bean - ul.
Pentru ca utilizatorii sa poata localiza un obiect Home, acesta trebuie sa aiba un identificator pe care containerul îl va asocia, în mod automat, cu obiectul Home.
De exemplu, pentru un bean numit FirstBean se poate specifica un identificator "firstBeanIdentif". Acesta va fi asociat automat de container pentru obiectul Home al bean - ului, iar apoi orice client de pe orice masina poate folosi acest identificator pentru a gasi obiectul Home, fara a se mai interesa de locul fizic unde se afla bean - ul. În spatele scenelor, JNDI cauta, în cadrul mai multor directory services, obiectul Home care are asociat acel identificator. Daca obiectul Home este gasit, se va returna clientului o referinta la el.
În cazul aplicatiilor, contextul initial (obiectul de tip InitialContext), care este furnizat de container când apeleaza metoda bean - ului setInitialContext(), dispune de toate configurarile necesare pentru a beneficia de serviciul de naming and directory. Pentru a gasi interfata Home a bean - ului, folosind contextul initial, nu este necesar decât apelul metodei lookup.
În Exemplul 2.5. s-a obtinut o referinta la obiectul Home al bean - ului de tipul FirstBean cu identificatorul "firstBeanIdentif" în interiorul bean - ului SecondBean.
|
Exemplul 2.5. Utilizarea unui bean în cadrul altui bean |
|
import javax.ejb.*; public class SecondBean implements SessionBean // a method that uses other bean named "firstBeanIdentif" public void businessMethod1() |
Dupa ce s-a obtinut obiectul Home, acesta se poate folosi pentru a crea obiecte EJB. Aceasta se face prin intermediul unei metode de create expuse de obiectul Home (si bine - nteles ca aceasta este implementata în codul bean - ului prin metoda ejbCreate()). În cazul de fata, FirstBean este de tipul stateless session bean (aceasta se va specifica la deployment), deoarece stateless session beans nu contin nici un fel de stare, nici nu primesc parametrii de initializare.
Obiectul EJB odata obtinut poate fi utilizat pentru a apela metodele pe care bean - ul le expune prin intermediul acestui obiect. Atunci când un client apeleaza o metoda asupra obiectului EJB, acesta trebuie sa aleaga o instanta de tipul bean - ului care sa duca la îndeplinire cererea. Obiectul EJB s-ar putea sa fie nevoit sa instantieze un nou bean sau sa reutilizeze o instanta deja existenta. Modul în care este implementat mecanismul de pooling este lasat la latitudinea constructorului containerului.
Ultimul pas este distrugerea obiectului EJB în momentul în care acesta nu mai este necesar. Aceasta se realizeza prin apelul metodei remove() prevazuta în interfata sa. La apelul acestei metode se anunta containerului ca obiectul poate fi distrus. Containerul poate sa-l distruga literalmente din memorie sau poate sa-l "goleasca de informatia ce o contine" si sa-l puna în pool (bazin), de unde va putea fi luat si refolosit pentru un alt client. Aceasta este, de fapt, implementarea mecanismului de pooling pentru obiectele EJB si care, ca si în cazul anterior, tine de constructorul containerului.
Un exemplu cât se poate de simplu, care ilustreaza toti pasii în utilizarea unui bean discutati anterior, este Exemplul 2.5. Acesta reprezinta utilizarea bean - ului FirstBean (descris în parte, atât cât este nevoie, în exemplele anterioare) pentru a aduna numarul 2 cu 3. Acesta este utilizat în cadrul metodei denumita metoda 1 a altui bean denumit SecondBean.
La crearea bean - ului SecondBean containerul va furniza contextul lui SecondBean prin apelul metodei acestuia setInitialContext. Contextul este salvat în variabila secondCtx.
În cadrul metodei businessMethod1 a bean - ului FirstBean, se obtine o referinta la obiectul Home al bean - ului de tipul FirstBean cu identificatorul "firstBeanIdentif", folosind contextul initial al lui SecondBean.
Asupra obiectului Home se aplica metoda create pentru a obtine obiectul EJB pentru bean - ul FirstBean. Dupa ce obiectul EJB este obtinut, se apeleaza metoda add a acestuia pe care acesta o expune.
Când obiectul EJB pentru FirstBean nu mai este necesar, se apeleaza metoda de remove() pe care acesta o expune, comunicând astfel containerului ca obiectul poate fi distrus sau pus în bazin (pool) pentru a implementa mecanismul de pooling.
Sinteza a tot ceea ce s-a spus despre utilizarea unui session bean este prezentata în Figura 2.18. Aici sunt ilustrati toti pasii care trebuie urmati, dar în cazul putin mai complex al apelului unui bean din alta parte (nu din interiorul unui bean). Tot ce se modifica în acest caz este faptul ca gasirea obiectului Home este putin mai complicata, deoarece trebuie utilizat serviciul JNDI direct, nu prin intermediul contextului initial care a usurat aceasta gasire în cazul nostru.
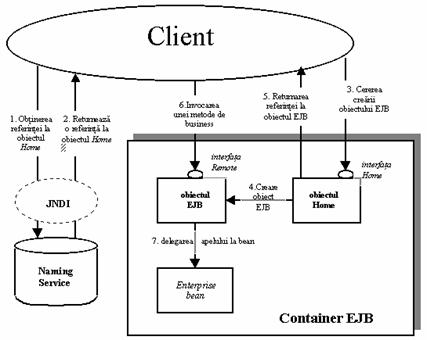
Figura
2.18. Apelul unui bean din codul
clientului
Stateless session beans sunt, dupa cum s-a amintit mai sus, bean - uri care reprezinta logica de business a aplicatiilor, însa nu mentin o conversatie cu clientul, deci datele despre client sunt utilizate doar pe parcursul unui apel de metoda a acestuia. În continuare, sunt prezentate alte careacteristici ale acestora.
Stateless session beans, desi au o stare interna, nu mentin nici o stare legata de un anume client, deci nu sunt particularizate pentru un anume client. Aceasta înseamna ca toate stateless session beans apar ca fiind identice când sunt privite de un anume client. Pentru ca un stateless session bean sa poata fi utilizat de un client, acesta trebuie sa trimita la apelul metodei toti parametrii necesari pentru logica de business. Eventual bean - ul poate încarca date si dintr-o sursa externa, ca de exemplu o baza de date.
Deoarece stateless session beans nu pot mentine starea de la un apel al unei metode la alt apel al ei, nu sunt necesare mai multe metode de ejbCreate(), ba chiar si singura metoda necesara nu primeste nici un parametru. Aceasta în contrast cu statefull session beans, care au mai multe metode de create, deoarece ele pot mentine starea de la un apel de metoda la altul. Evident ca interfata Home va expune metoda create() fara nici un parametru si, sigur, fara prefixul "ejb", dupa cum este prezentat în paragrafele anterioare.
Stateless session beans permit implementarea relativ usoara a mecanismului de pooling în interiorul containerului. Aceste bean - uri nu contin informatii legate de client, decât pe durata executiei metodei cerute de acesta, apoi nici macar nu mentin date cu privire la ce client au deservit. Aceasta permite ca un bean sa deserveasca un client, apoi sa poata fi reutilizat pentru alti clienti. Adica containerul poate sa aleaga dinamic care bean sa-l foloseasca pentru apelul unei metode venite de la un client. Câstigul sta în faptul ca bazinul (pool) poate fi mult mai mic decât numarul de clienti care se conecteaza. Aceasta din cauza ca nu toti clientii au nevoie de servicii de la aceste beans tot timpul. În vreme ce clientul sta sa se gândeasca, containerul poate reutiliza un bean pentru a deservi orice alt client si astfel se consuma mai putine resurse. Oricum, desi interesante, aceste mecanisme sunt lasate pe seama constructorului containerului.
Un alt aspect demn de luat în seama este ca stateless session beans sunt independente de obiectele EJB. Cu alte cuvinte, un obiect EJB poate utiliza oricare bean care este disponibil. De aceea nu este necesar ca sa fie creat un nou bean atunci când este creat un nou obiect EJB.
Exemplul de fata este, probabil, cel mai simplu posibil folosind tehnologia EJB. El îsi propune sa creeze o componenta stateless session bean care sa dispuna de o metoda la al carei apel se returneaza un String "Hello, World".
Primul pas îl constituie definirea interfetei Remote. Conform cu ceea ce s-a mentionat în capitolele anterioare, interfata Remote trebuie sa prezinte orice metoda de business pe care o are si obiectul EJB. Obiectul EJB va delega toate cererile clientului la bean. De remarcat ca interfata aceasta extinde javax.ejb.EJBObject, adica obiectul EJB, care este generat automat de container, va implementa aceasta interfata. Va trebui ca în aceasta interfata sa apara si metoda pe care dorim sa o apelam asupra bean - ului, adica hello(). Codul acestei interfete este prezentat în continuare.
|
Exemplul 2.6.1. Interfata Remote pentru beanul hello world |
|
import javax.ejb.*; import javax.rmi.RemoteException; import javax.rmi.Remote; public interface Hello extends EJBObject |
Urmatorul pas este crearea bean - ului propriu-zis. Trebuie implementata metoda de business hello() si metodele interfata javax.ejb.SessionBean pe care bean - ul de fata le implementeaza pentru a deveni session bean.
|
Exemplul 2.6.2. Beanul HelloBean |
|
import javax.ejb.*; public class HelloBean implements SessionBean public void ejbRemove() public void ejbActivate() public void ejbPassivate() public void setSessionContext(SessionContext ctx) public String hello() |
De remarcat ca bean - ul nu implementeaza interfata Remote din cauza ca interfata Remote extinde javax.ejb.EJBObject, care ar aduce noi metode. Deci, nu este logic ca bean - ul sa le implementeze. În plus, este si un motiv mai subtil. Acesta apare când se doreste transferul unei referinte la un bean. Problema care poate aparea este ca obiectul EJB ar putea fi confundat cu bean - ul însusi de catre un programator neatent, deoarece ambele implementeaza aceeasi interfata. În acest caz, compilatorul nu va da nici o eroare, totusi greseala ar fi majora, deoarece niciodata nu trebuie sa se poata ajunge la un bean decât prin intermediul obiectului EJB corespunzator. Daca totusi se doreste utilizarea interfetelor, pentru a evita acest caz, se recomanda sa se utilizeze o interfata care sa contina doar metodele de business. Aceasta interfata va fi implementata de bean si extinsa de interfata Remote.
Bean - ul este stateless si nu contine nici un fel de stare legata de client, care sa se extinda de la un apel al unei metode la altul. Metoda de create ejbCreate() nu primeste nici un parametru. La distrugerea bean - ului nu este nimic care trebuie distrus, asa ca metoda ejbRemove() este si ea goala. La fel este si metoda setSessionContext(), care asociaza bean - ului contextul în care el se afla si pe care îl poate interoga cu privire la starea sa. Desi contextul este foarte util, în acest exemplu extrem de simplu, nu s-a utilizat, deci nu a fost stocat într-un membru a clasei.
Metodele ejbActivate() si ejbPassivate() sunt folosite pentru a anunta bean - ul când este pasivizat, respectiv activat. Deoarece aceste concepte nu sunt aplicate asupra stateless session beans, vom lasa aceste metode fara implementare.În schimb, ele sunt folosite de catre statefull session beans.
Interfata Home specifica mecanismul de creare si distrugtere a obiectelor EJB. Aceasta interfata extinde javax.ejb.EJBHome si trebuie sa expuna unica metoda de create de care se dispune si care nu primeste nici un parametru, deoarece este pentru un stateless session bean.
|
Exemplul 2.6.3. Interfata home pentru beanul hello bean |
|
import javax.ejb.*; import javax.rmi.RemoteException; public interface Hello extends EJBHome |
Metoda de create expusa în interfata poate arunca doua tipuri de exceptii. Exceptia de tipul RemoteException este legata de faptul ca se foloseste RMI pentru a comunica în retea între obiecte distribuite si pot aparea erori legate de comunicare, ca de exemplu caderea retelei sau a masinii distante sau orice alta eroare ce tine de comunicarea cu obiectele distante într-un mediu distribuit. În schimb, eroarea CreateException este legata de o problema care apare la nivelul aplicatiei si care are cu siguranta o mare însemnatate pentru client.
O întrebare care reiese de aici este aceasta: de ce se face o diferenta între cele doua tipuri de exceptii? Motivul este ca, în general, este util sa se faca o diferenta între exceptiile care apar la nivelul aplicatiei si cele care apar la nivelul sistemului. În general, exceptiile la nivelul sistemului nu sunt de interes pentru client. Unele aplicatii profesionale vor prinde aceste exceptii si vor încerca sa realizeze aceeasi cerere de apel de metoda poate la un alt server. Exceptiile de la nivelul aplicatiei sunt, în schimb, întotdeauna de interes pentru client. De exemplu, pentru o aplicatie bancara, daca un client nu are suficienti bani în cont si, totusi, doreste sa extraga o anumita suma, se va ridica o exceptie de nivel aplicatie, pentru a marca faptul ca operatiunea bancara nu a reusit din cauza insuficientei banilor din cont.
Pentru a vedea cum functioneaza acest bean, este nevoie de un client care sa utilizeze stateless session bean - ul HelloBean. Un astfel de client este prezentat în Exemplul 2.6.4.
|
Exemplul 2.6.4. Client care utilizeaza beanul HelloBean |
|
import javax.ejb.*; import javax.naming.* import javax.rmi.*; import java.util.Properties; public class HelloClient catch(Exception ex) |
Pentru a putea rula acest exemplu, este nevoie sa se realizeze deployment -ul lui HelloBean pe un server J2EE, ca de exemplu j2sdkee, care poate fi gasit pe site-ul firmei Sun la adresa https://java.sun.com/j2ee/j2sdkee. Trebuie acordata atentie la identificatorul atasat bean - ului ca acesta sa fie exact "HelloHome".
Instructiunile de instalare pot fi gasite la adresa: https://java.sun.com/j2ee/j2sdkee/install.html.
Exemple de aplicatii cu deployment - ul lor pot fi gasite la adresa:
https://java.sun.com/j2ee/j2sdkee/techdocs/guides/ejb/html/DevGuideTOC.html
sau pentru download în format PDF la adresa: https://java.sun.com/j2ee/j2sdkee/devguide1_2_1.pdf
La rularea programului client, vor aparea în consola serverului urmatoarele mesaje:
setSessionContext()
ejbCreate()
hello()
ejbRemove(),
iar la client va aparea mesajul dorit: Hello, World! .
Dupa cum se poate observa, în prima faza, containerul a asociat bean - ului un session context , apoi a apelat metoda create(). Apelul metodei hello() asupra obiectului EJB a fost delegat metodei hello() a bean - ului. Prin distrugerea obiectului EJB s-a realizat si distrugerea bean - ului. Oricum este foarte important de remarcat ca implementarea mecanismului de pooling este lasata pe seama constructorului containerului care poate implementa orice algoritm considera el potrivit de aceea mesajele din consola serverului vor varia de la un container la altul. Este importanta retinerea acestui fapt mai ales la debugging.
Statefull session beans sunt bean - uri care realizeaza logica de business pentru clienti, însa, spre deosebire de stateless session beans, ele pastraza o informatia legata de conversatia cu clientul pe durata mai multor apeluri de metode. Starea conversationala este mentinuta în interiorul bean - ului si este specifica pentru un anume client.
Statefull session beans sunt, dupa cum s-a precizat mai sus, particularizate pentru un anume client, deci starea pe care ele o mentin poate fi utilizata si are sens doar pentru un anume client.
Important la statefull session beans este ca ele trebuie sa implementeze metodele ejbPassivate() si ejbActivate(). În plus, toate atributele care mentin starea bean - ului trebuie sa poata fi serializate. Motivele care stau în spatele acestor necesitati sunt explicate în continuare.
Se presupune un caz în care mii de clienti au conversatii cu diferite statefull session beans din cadrul unui container. O caracteristica generala a utilizatorilor umani este ca ei actioneaza relativ lent si izolat unii de altii. Aceasta înseamna ca bean - urile sunt accesate aleator si nu foarte multe în acelasi timp. Totusi mii de clienti înseamna mii de statefull session beans, iar resursele containerului sunt limitate (memorie, conexiuni la baze de date, conexiuni prin sockets). Daca starea pastrata de un statefull session bean este reprezentata de un volum mare de date, atunci serverul ar putea sa ramâna fara resurse. Pentru a preîntâmpina aceasta situatie ar trebui limitat numarul de instante de statefull session beans aflat în memorie. Pentru aceasta containerul poate sa realizeze operatiunea de pasivizare (passivation) asupra unor bean - uri. Atunci când clientul lanseaza o cerere pentru un bean care este pasivizat, acesta este readus în memorie, proces denumit activare (activation).
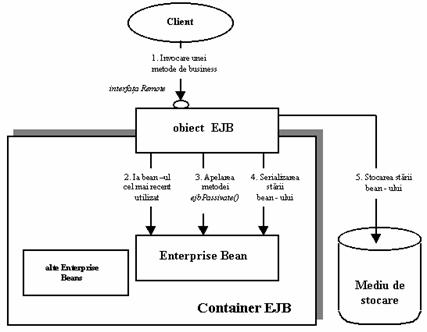
Figura
2.19. Procesul de pasivizare al
statefull session beans
Pasivizarea presupune, în primul rând, ca bean - ul sa elibereze toate resursele pe care le detine, neputând fi serializate conexiunile la bazele de date sau socket - urile deschise. Eliberarea acestor resurse se face la comanda containerului care apeleaza metoda ejbPassivate() a bean - ului. Dupa ce acesta a eliberat resursele, containerul îl serializeaza si îl stocheaza (de obicei sub forma de blob) într-un mediu persistent (de obicei o baza de date). Acum este aproape evident de ce este necesar ca atributele de stare sa poata fi serializate. Daca ele nu pot fi serializate, atunci prin procesul de pasivizare / activare s-ar pierde starea conversationala cu clientul, care, în cele mai multe cazuri, ar face bean - ul inutilizabil. Procesul de pasivizare este prezentat în Figura 2.19.
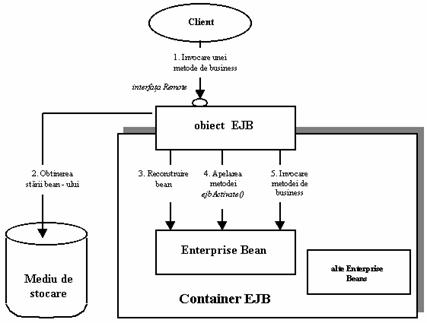
Figura 2.20. Procesul de activare al statetefull session beans
Pasivizarea asupra unui bean poate fi invocata în orice moment de catre container, iar algoritmii folositi de container pentru a decide care bean sa fie pasivizat sunt lasati pe seama constructorului containerului. De aceea, bean - ul trebuie sa fie pregatit pentru pasivizare în orice moment. Totusi exista o exceptie de la regula aceasta: orice bean care este implicat într-o tranzactie nu poate fi pasivizat pâna când tranzactia nu este încheiata.
Activarea bean - urilor presupune procesul invers pasivizarii, adica acestea sunt aduse din mediul de stocare si reconstruite în memorie, apoi se apeleaza metoda ejbActivate() care va recâstiga resursele de care are nevoie bean - ul. Procesul de activare este prezentat în Figura 2.20.
Cel mai simplu bean care trebuie sa mentina starea de la un apel de metoda la altul este unul care numera de câte ori a fost apelata acea metoda. El va realiza aceasta prin intermediul unei metode count() care atunci când este apelata incrementeaza pur si simplu un atribut de stare al bean - ului.
Interfata Remote a acestui bean este de o simplitate dezarmanta, deoarece expune doar metoda count() a carei implementare din bean va incerementa variabila val. Aceasta variabila reprezinta starea conversationala a acestui bean.
|
Exemplul 2.7.1. Interfata Remote pentru beanul CountBean |
|
Import javax.ejb.*; import javax.rmi.RemoteException; import javax.rmi.Remote; public interface Count extends EJBObject |
Implementarea propriu - zisa a acestui bean are o unica metoda de business: count(). Ea va incrementa atributul de stare val. Bean - ul trebuie sa implementeze interfata javax.ejb.SessionBean. Metoda utilizata pentru crearea bean - ului ejbCreate() primeste un parametru cu care se initializeaza starea bean - ului. Desi, evident trebuie mentionat ca val este serialazabil fiindca este de tipul primitv int. Aceasta era necesar pentru a permite activarea si pasivizarea starii bean - ului.
|
Exemplul 2.7.2. Beanul CountBean |
|
Import javax.ejb.*; public class CountBean implements SessionBean public void ejbRemove() public void ejbActivate() public void ejbPassivate() public void setSessionContext(SessionContext ctx) // business method public int count() |
Interfata Home pentru obiectul Home atasat acestui bean va detalia crearea si distrugerea beanurilor. Deoarece se extinde interfata javax.ejb.EJBHome metoda remove() este deja disponibila.
|
Exemplul 2.7.3. Interfata home pentru beanul CountBean |
|
import javax.ejb.*; import javax.rmi.RemoteException; public interface CountHome extends EJBHome |
Clientul pentru acest bean realizeaza urmatoarele: obtine contextul initial, localizeaza obiectul Home folosind JNDI. Folosind obiectul Home, se creeaza un obiect EJB asupra caruia se apeleaza metoda count(), iar apoi obiectul EJB este distrus.
|
Exemplul 2.7.4. Client pentru beanul CountBean |
|
import javax.ejb.*; import javax.naming.*; import java.util.Properties; public class CountClient catch(Exception ex) |
Pentru a putea rula acest exemplu, este nevoie sa se realizeze G-ul lui CountBean pe un server J2EE, ca de exemplu j2sdkee care poate fi gasit pe site-ul firmei Sun la adresa https://java.sun.com/j2ee/j2sdkee. Trebuie acordata atentie la identificatorul atasat bean - ului ca acesta sa fie exact "CountHome".
Instructiunile de instalare pot fi gasite la adresa: https://java.sun.com/j2ee/j2sdkee/install.html.
Exemple de aplicatii si deployment - ul lor pot fi gasite la adresa:
https://java.sun.com/j2ee/j2sdkee/techdocs/guides/ejb/html/DevGuideTOC.html
sau pentru download în format PDF la adresa: https://java.sun.com/j2ee/j2sdkee/devguide1_2_1.pdf
Deja s-au parcurs câte un exemplu de statefull si unul de stateless session beans, urmând a fi prezentate considerentele care trebuie luate în seama la proiectarea unei aplicatii folosind statefull si stateless session beans. Întrebarea care se pune este care dintre cele doua tipuri de bean - uri sunt potrivite în diferite situatii. Cu alte cuvinte care sunt avantajele si dezavantajele celor doua tipuri de bean - uri?
Stateless session beans au avantajul de a fi refolosite cu usurinta de catre containerul EJB pentru mai multi clienti. Daca se încearca aceeasi strategie la statefull session beans,din pacate, este mai complicat, deoarece apar pasivizarea si activarea care vor consuma resurse în plus, putând duce chiar la gâtuituri în sistemul de intrare/iesire (I/O bottlenecks). Deci un mare avantaj al stateless session beans este ca ele pot fi reutilizate fara a consuma resurse în plus aproape deloc.
Deoarece statefull session beans pastreaza starea conversatiei cu clientul în memorie, o eroare aparuta ar putea duce la pierderea întregii conversatii cu clientul. Acest fenomen neplacut poate fi evitat fie prin proiectarea aplicatiei, fie prin utilizarea unui container care permite refacerea statefull session bean - urilor.
Cel mai mare dezavantaj al stateless session beans este ca nu pot mentine nici un fel de informatii de stare. Totusi cele mai multe stateless session beans au nevoie de date legate de client, ca de exemplu numarul contului bancar. Aceasta informatie trebuie furnizata la fiecare apel de metoda, deoarece stateless session beans nu pastraza aceasta stare.
O metoda de a furniza bean - ului date specifice clientului este de a furniza datele prin intermediul parametrilor utilizati la apelul metodelor bean - ului. Aceasta, însa, poate duce la scaderea performantei sau chiar la congestie în retea, daca nu, cel putin, la reducerea benzii disponibile pentru alte procese.
Alta metoda de a evita aceste neplaceri este ca bean - ul sa stocheze date specifice clientului într-o structura de directoare folosind JNDI. Clientul va putea fi identificat prin intermediul unui identificator, care va fi utilizat si pentru localizarea datelor în structura de directoare.
La alegerea dintre statefull si stateless, pe lânga considerentele legate de conversatia cu clientul, trebuie luate în considerare si aspectele de mai sus.
Entity beans sunt enterprise beans care stiu cum sa se salveze pe ele însele într-un mediu permanent de stocare. Entity beans stocheaza date cum ar fi numarul contului bancar, numerarul din cont, etc. Ele au asociate metode ca getBan() sau getAccountBalance(). Entity beans pot fi folosite si pentru integrarea aplicatiilor mai vechi (legacy systems).
Spre deosebire de session beans care modelaza procesele, actiunile pornite de utilizatori, entity beans contin datele legate de aplicatie, ca de exemplu conturi bancare, comenzi, informatii legate de utilizatori, etc. Un entity bean nu realizeaza sarcini complicate, cum e, de exemplu, realizarea platilor de la client.
Entity beans pot fi privite astfel:
o reprezentare în memorie a datelor sub forma de obiect Java
obiecte capabile sa se citeasca din mediul de stocare si sa îsi populeze câmpurile cu aceste date
un obiect care poate fi modificat în memorie si care va schimba datele din mediul de stocare
Entity beans au durata de viata egala cu cea a datelor pe care le reprezinta. De exemplu, un entity bean poate reprezenta contul unui client.
Entity beans supravietuiesc în cazul unor caderi accidentale. Deoarece entity beans sunt parte dintr-un mediu persistent, o cadere a JVM (Java Virtual Machine) sau a bazei de date nu va afecta ciclul de viata al unui entity bean. De îndata ce lucrurile reintra în normal, instantele entity beans pot fi recreate prin simpla citire a datelor din baza de date si crearea unor instante care sa le reprezinte în memorie.
Entity beans au seminificatia unui zoom asupra datelor din baza de date pe care le reprezinta. Cu alte cuvinte, datele din baza de date si obiectul din memorie care le reprezinta (instanta bean - ului asociata lor) trebuie privite ca fiind unul si acelasi. Aceasta înseamna ca, daca datele din memorie, adica din bean, sunt modificate, atunci, în mod automat, sunt modificate si datele din baza de date. Desigur ca, în realitate, obiectul din memorie, instanta entity bean - ului nu este unul si acelasi cu datele din baza de date. Din acest motiv, trebuie sa existe un mecanism prin care sa poata fi transferata informatia între obiectul din memorie si baza de date. Acest transfer este realizat prin intermediul a doua metode speciale pe care orice entity bean trebuie sa le implementeze: ejbLoad() si ejbStore(). Metoda ejbLoad() are rolul de a citi datele din mediul permanent de stocare si de a le plasa în câmpurile bean - ului. Metoda ejbStore() este complementara, realizând salvarea datelor din bean în baza de date.
Întrebarea care se pune este cine decide momentele în care sa fie transferate datele între obiectele din memorie si cele din baza de date. Cu alte cuvinte, cine apeleaza metodele ejbLoad() si ejbStore()? Dupa cum s-a vazut deja, este vorba de containerul EJB. El este cel care alege momentele în care sa transfere datele din memorie în mediul persistent si invers. Bean - ul trebuie sa fie pregatit sa accepte metodele ejbLoad() si ejbStore() aproape în orice moment, dar nu în decursul metodelor de business. Acesta este unul dintre avantajele EJB: programatorul nu trebuie sa se preocupe de sincronizarea între datele din bean - ul din memorie si datele din baza de date.
Sa consideram cazul în care mai multe fire de executie (threads) doresc sa acceseze simultan aceleasi date. De exemplu, se poate întâmpla ca, simultan, mai multi clienti ai unui magazin virtual sa acceseze un catalog de produse.
Pentru a facilita accesul simultan al mai multor clienti la aceleasi date, trebuie sa existe un mecanism de acces la entity beans. O posibilitate ar fi sa se permita clientilor sa partajeze aceeasi instanta a unui entity bean. Aceasta este inadecvata din doua motive: codul din interiorul bean - ului ar trebui sa fie thread-safe si ar aparea o gâtuitura la aceesul la date.
Codul thread-safe este un cod care permite executarea mai multor fire de executie folosind aceleasi date. Daca pentru entity beans ar fi mai multe fire de executie, tranzactiile ar fi aproape imposibile. Din acest motiv, în specificarea EJB, se spune ca în intreriorul unei instante a unui bean poate rula doar un thread. Acelasi lucru este adevarat si pentru session beans.
Gâtuitura în accesul la date ar aparea atunci când mai multi clienti acceseaza un bean, fiindca trebuie ca fiecare sa astepte dupa cei dinaintea lui. Pentru a evita aceasta, se permite containerului sa creeze mai multe instante ale aceluiasi entity bean (adica mai multe instante sa reprezinte exact aceleasi date). Aceasta va permite clientilor sa aiba acces concurent la date.
Totusi procedand asa apare o noua problema. Daca mai multe instante reprezinta aceleasi date, atunci unele dintre ele ar putea reprezenta, la un moment dat, datele vechi, nestiind ca, de fapt, ele s-au modificat între timp. Pentru a avea consistenta datelor, fiecare client are nevoie sa fie sincronizat cu mediul permanent de stocare. Containerul este cel care va realiza aceasta sincronizare între instanta bean - ului si mediul permanent de stocare, folosind metodele ejbStore() si ejbLoad(). Când o instanta de bean este modificata, containerul va apela metoda ejbStore() a acestuia si apoi va apela metoda ejbLoad() asupra fiecarei instante de bean care reprezinta aceleasi date.
Frecventa cu care sunt sincronizate bean - urile cu mediul de stocare este dictata de atributele privitoare la tranzactii. Tranzactiile permit fiecarui client sa fie complet izolat de toate celelalte cereri. Cu alte cuvinte, acestea fac posibila iluzia clientului ca el este singurul care opereaza asupra acelor date.
Cea mai simpla metoda de a satisface cererile clientilor într-un container, care suporta entity beans, ar fi ca, pe masura ce clientii se conecteaza sau se deconecteaza, sa se creeze si sa se distruga bean - uri penrtu acei clienti. Din pacate, desi simpla, aceasta metoda nu este tocmai eficienta, deoarece crearea si distrugerea de obiecte este întotdeauna costisitoare ca resurse, mai ales daca cererile clientilor sunt foarte frecvente.
Un fapt foarte important, care trebuie avut în vedere, este ca respectiva clasa, care defineste entity bean - ul, descrie câmpurile ei si regulile pentru manipularea acelor câmpuri, dar nu si datele specifice din acele câmpuri. De exemplu, o clasa entity bean poate specifica un cont bancar care va contine numele posesorului, identificatorul contului, soldul contului. O instanta de bean poate reprezenta oricare dintre conturile din baza de date.
Din motivul expus mai sus, entity beans sunt privite de catre container ca obiecte reciclabile, asupra carora se poate aplica mecanismul de pooling. În acest fel, se vor salva resurse pretioase, care, alfel, ar fi fost irosite pe instantieri si distrugeri de obiecte. De exemplu, o instanta a unui entity bean, care reprezinta un cont bancar, poate fi reutilizata sa reprezinte datele altui client, dupa ce primul client a terminat de utilizat propriul cont bancar reprezentat de acea instanta a bean - ului. Containerul face aceasta prin asignarea dinamica a instantelor entity beans la diferite obiecte EJB, care sunt specifice câte unui client. Mecanismul de pooling aplicat la entity beans este prezentat si în Figura 2.21.
Din pacate, reasignarea instantelor entity beans la diferite obiecte EJB aduce dupa sine mai multe complicatii. Atunci când un entity bean este asignat unui obiect EJB particular, poate sa detina anumite resurse, cum ar fi conexiuni la baza de date sau conexiuni la alte aplicatii prin socket-uri. Când bean - ul nu mai este legat de vreun client (când se afla în bazin), nu mai are nevoie de acele resurse. Pentru a permite bean - ului sa elibereze si recâstige resursele, se vor utiliza metodele ejbPassivate() si ejbActivate(). De fapt, aceste metode sunt foarte asemanatoare cu cele de la statefull session beans.
Metoda ejbPassivate() este invocata de container atunci când dezasociaza bean - ul de un obiect EJB specific. Pentru identificarea bean - ului se utilizeaza o cheie primara, care poate fi orice tip de obiect. Tot în acest moment, se dezasociaza si cheia primara pe care acest bean a avut-o. La apelul acestei metode, bean - ul trebuie sa elibereze resursele pe care le detine.
Metoda ejbActivate() este invocata de container atunci când bean - ul este asociat unui anume obiect EJB. Tot acum se asociaza bean - ului si o cheie primara, care va fi utilizata ulterior. Bean - ul, acum atasat de un anume client, trebuie sa reobtina resursele pe care le-a eliberat la apelul metodei ejbPassivate().
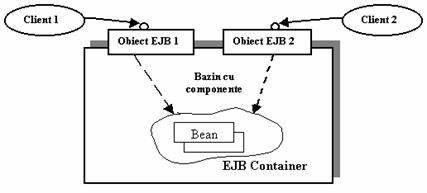
Figura
2.21. Mecanismul de pooling la
entity beans
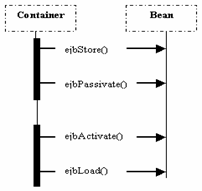
Atunci
când un entity bean este pasivizat,
pe lânga faptul ca elibereaza resursele pe care le detine,
îsi si salveaza starea în mediul de stocare. În acest fel,
mediul de stocare este împrospatat cu ultima stare a instantei bean - ului. Pentru a salva câmpurile bean - ului în mediul de stocare,
containerul invoca metoda ejbStore()
înainte de a apela ejbPassivate(). În
mod similar, atunci când un bean este
activat, el trebuie nu numai sa obtina resursele de care are
nevoie, dar si sa încarce ultimele date din baza de date. Pentru ca
sa încarce datele în câmpurile instantei entity bean - ului, containerul invoca metoda ejbLoad(). Aceasta metoda este
invocata dupa ejbActivate().
Succesiunea metodelor la activare si pasivizare poate fi observata în
Figura
2.22.
Figura 2.22. Succesiunea metodelor la pasivizare si activare
Protocolul pentru transferul starii unei instante a unui entity bean spre mediul de stocare este denumit persistenta. În cadrul entity beans, persistenta poate fi implementata în urmatoarele doua moduri:
Implementarea directa a persistentei în clasa care defineste enterprise bean - ul sau în una sau mai multe clase ajutatoare, care vor fi utilizate în interiorul bean - ului. Acest mecanism de persistenta se numeste bean managed persistance (persistenta gestionata de entity bean).
Delegarea responsabilitatii persistentei la container. Acest mecanism de persistenta se numeste container managed persistance (persistenta gestionata de containerul în care ruleaza entity bean - ul).
În cazul bean managed persistance, cade în responsabilitatea programatorului de a scrie codul de acces la baza de date. Apelurile spre baza de date pot fi codate direct în clasa entity bean - ului sau pot fi încapsulate într-o componenta de Data Access ca parte a unui entity bean. Daca apelurile la baza de date sunt codate direct în clasa entity bean - ului, va fi mult mai dificil sa se realizeze adaptarea entity bean - ului la o noua arhitectura a bazei de date. Încapsularea apelurilor la baza de date într-un Data Access Object va duce la o mult mai mare adaptabilitate a aplicatiei la o noua arhitectura a bazei de date. De fapt, Data Access Object este un design pattern ce va fi reluat separat.
În cazul persistentei gestionate de catre container, programatorul identifica câmpurile care vor fi stocate în baza de date si va utiliza apoi, în momentul deployment - ului, uneltele puse la dispozitie de container pentru a genera codul de acces la baza de date. Tipologia si structura bazei de date sunt transparente pentru programator. Uneltele puse la dispozitie de container pot folosi JDBC (Java Data Base Connectivity) sau SQL/J pentru a accesa starea entity bean - ului din tabelele bazei de date relationale sau din clase care implementeaza accesul la aplicatii enterprise deja existente. Starea bean - ului este definita independent de modul cum si locul unde va fi stocat, motiv pentru care este mai flexibil. Dezavantajul este ca sunt necesare unelte mai sofisticate la deployment pentru a putea mapa datele în câmpurile unei baze de date. Aceste unelte sunt în general specifice fiecarei baze de date.
Atunci când un container suporta container managed persistance, el simplifica sarcina de scriere a codului entity beans, deoarece containerul îsi asuma complet responsabilitatea de a genera codul pentru accesul la baza de date. Programatorii ar trebui sa se foloseasca de acest avantaj pentru a delega sarcina salvarii starii entity bean - ului la container pe cât posibil. Unele containere s-ar putea sa nu fie capabile sa gestioneze starea unor obiecte mai complexe (de exemplu obiectele care reprezinta rezultatul unui select cu mai multe join- uri imbricate). În asemenea cazuri, programatorii vor fi nevoiti sa utilizeze persistenta gestionata de bean.
La session beans exista metoda de creare ejbCreate() si cea de distrugere ejbRemove(). Metoda ejbCreate() este chemata de container pentru a initializa bean - ul. Când un bean este pe cale de a fi distrus, containerul apeleaza metoda ejbRemove() care are rolul de a pregati bean - ul pentru distrugere.
La entity beans, initializarea si distrugerea sunt putin diferite. Entity beans sunt o reprezentare a datelor din baza de date, deci trebuie privite ca fiind una cu datele din baza de date. Din acest motiv, initializarea - crearea unui entity bean- trebuie sa însemne crearea datelor în baza de date. Astfel, când datele sunt initializate în memorie la ejbCreate(), este normal ca ele sa fie inserate si în baza de date. Pe de alta parte, când este apelata metoda ejbRemove(), datele din baza de date sunt sterse. Daca se utilizeaza container managed persistance, este lasata pe seama containerului întreaga sarcina de modificare în baza de date. Din acest motiv, pentru container managed persistance nu este nevoie sa fie completat corpul metodelor ejbCreate() si ejbRemove().
În orice baza de date, datele poarta un identificator unic. Deci este natural ca si entity beans, care sunt o reprezentare a lor, sa aiba un identificator unic. În cazul bazelor de date, se folosesc frazele de SELECT pentru a gasi anumite date. În cazul entity beans, sunt prevazute metodele de find (finder methods). Semnificatia lor este de cautare în mediul persistent dupa datele reprezentate în forma obiectuala. Rezultatul unei operatii de find este o colectie de referinte la obiecte EJB. Aceste obiecte vor fi asociate dinamic de catre container cu instante de bean - uri.
Finder methods apar expuse în interfata Home a bean - ului. O întrebare, poate nu chiar cea mai buna, este de ce în interfata Home? Pentru ca s-ar putea ca sa nu se detina nici o referinta la vreun obiect EJB pentru vreun entity bean si ar fi, în unele cazuri, imposibil sa se obtina una. În plus, scopul obiectului Home este de a furniza instante de obiecte EJB (acest lucru este adevarat si în cazul session beans). Finder methods reprezinta diferenta cea mai mare între interfetele Home pentru entity beans si session beans.
Datele pe care le reprezinta entity beans pot fi modificate si altfel decât prin intermediul entity beans. Daca, de exemplu, se folosesc baze de date relationale si mai sunt alte aplicatii care modifica datele, se poate considera ca s-au modificat si entity beans în acelasi timp. Daca acele aplicatii sterg date, atunci se poate considera ca s-au sters si entity beans, ca si când s-ar fi apelat metoda ejbRemove() asupra interfetei Remote expusa de obiectul EJB. În mod asemanator, la introducerea de noi date, se poate considera ca s-a apelat metoda ejbCreate().
Pentru ca o clasa sa poata fi un entity bean, trebuie sa implementeze interfata javax.ejb.EntityBean. Metodele din aceasta interfata sunt metode pe care le utilizeaza containerul pentru initializare, pasivizare, activare, distrugere, etc. Aceasta interfata are ca parinte interfata javax.ejb.EnterpriseBean, care, desi nu are metode, implementeaza interfata Serializable, deci orice enterprise bean; prin urmare si entity beans sunt serializabile.
Interfata javax.ejb.EntityBean este prezentata în continuare:
|
Interfata javax.ejb.EntityBean |
|
public interface javax.ejb.EntityBean implements javax.ejb.EnterpriseBean |
Pe lânga metodele din aceasta interfata, pentru un entity bean, se mai definesc metodele ejbCreate() si ejbFind(). Metodele de tipul ejbCreate() sunt utilizate pentru a crea entity beans, adica pentru a introduce date în mediul persistent. Cele de tipul ejbFind() sunt utilizate pentru a gasi anumite date.
O metoda ejbCreate() are rolul de a initializa un entity bean pentru un anume client si de a crea datele în baza de date. Fiecare metoda ejbCreate() permite clientului o noua posibilitate de creare a unui entity bean.
Iata câteva reguli pentru metodele ejbCreate() în cazul entity beans:
Nu este obligatorie realizarea unor metode ejbCreate(). Spre deosebire de session beans, unde aceasta era singura modalitate de initializare a unui bean, în cazul entity beans, datele pot fi inserate în baza de date pe alte cai, deci se pot crea entity beans fara a avea nevoie de metodele ejbCreate(). Entity beans trebuie privite ca fiind una cu datele din baza de date, dupa cum s-a precizat mai sus.
Parametrii primiti de metodele ejCreate() pot varia. Aceasta permite existenta mai multor metode de initializare a bean - urilor, de fapt, de introducere a datelor în baza de date.
Metodele ejbCreate() trebuie expuse si în interfata Home pentru a putea fi utilizate. Ca si în cazul session beans, orice entity bean este creat prin invocarea metodelor ejbCreate() asupra obiectului Home, care va crea un obiect EJB si va asocia un bean propriu - zis pentru acel obiect EJB.
De exemplu, se presupune ca exista un entity bean denumit AccountBean, care reprezinta un cont bancar. Acest bean va avea interfata Home AccountHome si cheia primara (acest concept se va clarifica imediat) va avea clasa AccountPK. Metoda ejbCreate() din interfata clasa bean - ului AccountBean
public AccountPK ejbCreate(String accountID, String owner)
trebuie sa poata fi utilizata, deci va apare si în interfata Home, dar sub forma:
public Account create(String accountID, String owner).
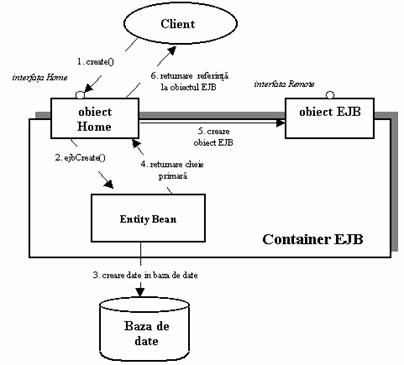
Figura
2.23. Crearea unui entity bean
pentru cazul bean managed persistance
Trebuie remarcat ca cele doua metode returneaza obiecte de tipuri diferite. Instanta bean - ului returneaza o cheie primara de clasa AccountPK, iar obiectul Home returneaza un obiect EJB de clasa Account. Bean - ul returneaza o cheie primara containerului (adica obiectului Home), care, astfel, poate identifica bean - ul. Dupa ce a obtinut cheia primara, containerul va genera obiectul EJB pe care-l va returna clientului. Întregul proces poate fi observat în Figura 2.23.
Finder methods sunt utilizate pentru a gasi bean - uri existente, deja create. Finder methods nu creeaza date în baza de date, ci, doar încarca date din baza de date. Pot exista mai multe metode de gasire, care toate realizeaza operatii diferite.
Câteva reguli pentru finder methods sunt urmatoarele:
Trebuie sa existe cel putin o metoda find denumita ejbFindByPrimaryKey(), care este utilizata pentru a gasi o instanta a unui entity bean în baza de date, folosind cheia primara asociata acestuia. Fiecare entity bean are asociata o cheie unica, care este în legatura cu datele pe care le reprezinta din baza de date.
Pot exista mai multe finder methods care au denumiri diferite si primesc parametri diferiti. Aceasta permite cautarea prin folosirea mai multor semantici. De exemplu, pentru un obiect de business de tipul entity bean, care reprezinta un cont, pot exista, pe lânga ejbFindByPrimaryKey(), si alte metode de find ca: ejbFindBigAccounts(), ejbFindEmptyAccounts(), etc.
O metoda de tipul ejbFind trebuie sa returneze fie o cheie primara, fie o colectie de chei primare, daca gaseste mai mult de una.
Clientii nu invoca niciodata finder methods asupra instantei bean - ului. Aceste metode se invoca asupra obiectului Home implementat de containerul EJB, care le va delega bean - ului. Din acest motiv, pentru fiecare metoda ejbFind, care este declarata în bean, trebuie sa existe un corespondent în interfata Home. De exemplu, pentru metoda:
public AccountPK ejbFindBigAccounts( int minimum) throws ... implementata în clasa entity bean - ului, trebuie sa existe urmatoarea metoda declarata în interfata Home:
public Account findBigAccounts(int minimum ) throws ...
De remarcat ca metoda din interfata nu are prefixul ejb si ca returneaza un tip diferit de obiect. Instanta entity bean - ului returneaza o cheie primara sau o colectie de chei primare, iar obiectul Home returneaza clientului un obiect EJB sau o colectie de obiecte ejb.
Pentru a distruge datele pe care le reprezinta un entity bean, clientul trebuie sa apeleze metoda remove() asupra obiectului EJB sau obiectului Home. Acesta va determina containerul sa realizeze un apel al metodei ejbRemove() a bean - ului.
De remarcat ca metoda ejbRemove() nu realizeaza stergerea din memorie a obiectului, ci va distruge datele din baza de date pe care le reprezinta acel bean. Bean - ul însusi poate fi reutilizat pentru a reprezenta alte date din baza de date.
Aceasta metoda trebuie sa fie definita de orice entity bean si e una singura: ejbRemove().
Fiecare enterprise bean are un obiect context, care contine date despre mediul în care traieste bean - ul. Aceste date sunt completate de container. Bean - ul poate accesa contextul pentru a obtine informatii privitoare la tranzactii, securitate sau alte feluri de informatii. Pentru session beans, contextul este un obiect care implementeaza interfata javax.ejb.SessionContext, iar pentru entity beans, obiectul context implementeaza interafata javax.ejb.EntityContext. Ambele interfete descind din interfata javax.ejb.EJBContext.
|
Interfata javax.ejb.EntityContext |
| public interface javax.ejb.EntityContext implements javax.ejb.EJBContext |
Metoda getEJBObject() este utilizata pentru a obtine obiectul EJB, care este asociat cu entity bean - ul. Clientii nu acceseaza niciodata bean - urile direct, ci fiecare client are asociat un obiectEJB. Obiectul EJB returnat de aceasta metoda poate fi utilizat pentru a avea o referinta la acelasi obiect. Cu alte cuvinte, poate fi utilizat pentru a simula rolul lui this din Java.
Metoda getPrimaryKey() este specifica pentru entity beans. Ea returneaza cheia primara, care este asociata la acel moment cu acea instanta a bean - ului. Cheia primara identifica în mod unic acel entity bean, de fapt si datele în baza de date sunt identificate unic prin cheile primare ale tabelelor. Aceasta metoda este utila pentru a afla care date din baza de date sunt asociate cu un entity bean în momentul apelului. Instantele entity beans sunt asignate când la un obiect EJB, când la altul, conform politicii containerului pentru mecanismul de pooling. Din acest motiv este necesara aflarea cheii primare a datelor pe care le reprezinta bean - ul la un moment dat. Cheia primara obtinuta cu getPrimaryKey() poate fi utilizata la activare, pasivizare, ejbLoad() sau ejbStore().
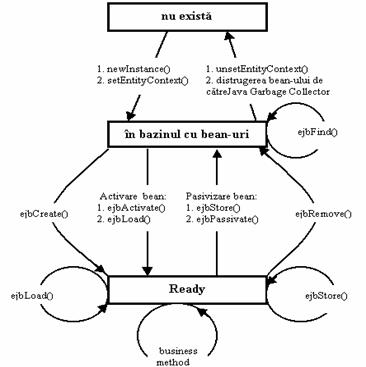
Ciclul de
viata al unui entity bean
este prezentat prin automatul de stare din Figura 2.24.
Figura 2.24. Ciclul de viata al unui entity bean
Se porneste din starea în care bean - ul nu a fost instantiat. Pentru a crea o noua instanta de bean, containerul apeleaza metoda newInstance() asupra clasei entity bean - ului. Aceasta va apela constructorul implicit al clasei. Apoi, prin intermediul metodei setEntityContext(), containerul asociaza bean - ului un EntityContext. Important de observat este faptul ca nu se creeaza o noua instanta de bean atunci când un client se leaga, deoarece instantele entity beans suporta mecanismul de pooling. O noua instanta de entity bean este creata atunci când containerul considera acest lucru necesar, pentru a îsi mari bazinul de bean - uri.
Acum bean - ul se afla într-un bazin cu alte entity beans. Înca nu sunt nici un fel de date asociate cu acest bean si nici un fel de resurse nu au fost obtinute de acest entity bean. În aceasta faza, bean - ul poate fi distrus de catre container prin apelarea metodei unsetEntityContext(), iar apoi Garbage Collector - ul va curata zona de memorie respectiva.
Atunci când un client doreste sa insereze noi date în baza de date, el va apela metoda create() asupra obiectului Home al bean - ului. Containerul va lua o instanta de bean din bazin si va apela metoda acestuia ejbCreate(), care va initializa entity bean - ul cu anumite date. Bean - ul îsi va popula variabilele membru cu aceste date si, daca se utilizeaza bean managed persistance, atunci va si insera datele în baza de date. Acum bean - ul se afla în starea de ready.
În aceasta stare, bean - ul este legat de anumite date din baza de date si de un anume obiect EJB. Daca exista mai multe bean - uri, care reprezinta aceleasi date din baza de date, containerul va trebui sa sincronizeze, ocazional, instanta bean - ului cu baza de date pentru a reprezenta ultimele date. Aceasta se face prin intermediul metodelor ejbLoad() si ejbStore().
Entity bean - ul poate fi trimis din nou în bazin, în cazul în care clientul apeleza metoda remove() asupra obiectului Home sau în cazul în care datele sunt sterse pe alta cale din baza de date. De asemenea, bean -ul este trimis de container în bazin daca acesta a decis ca timpul acordat clientului a expirat sau ca ramâne fara resurse sau ca are nevoie de acea instanta a bean - ului pentru a deservi un alt client. În aceste din urma situatii, containerul va apela metoda ejbStore() pentru a se asigura ca baza de date contine ultima versiune a datelor din memorie. Apoi el va apela metoda ejbPassivate() pentru ca resursele detinute de bean sa fie eliberate si sa poata fi reutilizate.
Atunci când containerul doreste sa asigneze un alt obiect EJB, instanta bean - ului trebuie activata prin apelul metodei ejbActivate(), astfel bean - ul va obtine toate resursele de care are nevoie. Pentru a încarca date din baza de date în bean, containerul va apela metoda ejbLoad().
Orice entity bean trebuie sa implementeze metodele din interfata javax.ejb.EntityBean. Tabelul 2.2. prezinta toate metodele care apar în aceasta interfata, rolul lor, precum si utilizarea lor obisnuita. Pentru o întelegere cât mai buna se recomanda urmarirea ciclului de viata al unui entity bean din Figura 2.24. Metodele sunt prezentate într-o posibila ordine a apelarii lor de catre container.
Tabelul 2.2. Rezumatul metodelor din interfata EntityBean
|
Metoda |
Semnificatie metodei |
Utilizare obisnuita |
|
setEntityContext() |
Este apelata de container atunci când doreste sa creasca numarul de bean - uri din bazinul cu bean -uri. El va instantia un nou obiect de tipul clasei bean - ului. Apoi imediat containerul va apela asupra noii instante metoda setEntityContext() care va asocia bean - ului un context în care bean -ul poate gasi informatii despre mediu. Dupa apelul acestei metode, bean -ul poate sa apeleze metode pentru a afla mediul în care ruleaza. |
Se salveaza într-o variabila membru EntityContext -ul primit. Mai târziu el poate fi utilizat pentru a obtine informatii legate de mediu de la container (ca de exemplu, cele despre securitate). Se obtin acele resurse de care are nevoie un entity bean indiferent de ce date va reprezenta. Acum bean -ul este în bazin si nu este asociat cu nici un obiect, deci nu reprezinta nici un fel de date din baza de date |
|
ejbFind<...>(<...>) |
Cât timp instanta bean - ului se afla înca în bazin ea poate fi utilizata pentru a deservi apelul unei metode de find. Metodele de find sunt utilizate pentru a gasi date în mediul persistent. Este obligatorie implementarea cel putin a metodei ejbFindByPrimaryKey(). |
Se cauta în baza de date, utilizând, de exemplu, JDBC. De obicei, se va realiza o interogare de tipul "SELECT ... FROM ...". Se returneaza containerului cheile primare gasite. Containerul va crea apoi niste obiecte EJB pe care le va putea invoca clientul. Probabil va asocia câtorva obiecte EJB instante de bean-uri. Instantele asociate nu se mai afla în bazin si au anumite date specifice din baza de date cu care sunt asociate. |
|
ejbCreate(<...>) |
Atunci când un client apeleaza create() asupra obiectului Home containerul va apela metoda ejbCreate() a bean - ului. Metoda este responsabila de crearea noilor date în baza de date si de initializarea bean - ului cu acele date. |
Se verifica validitatea parametrilor de initializare si apoi folosind JDBC se vor stoca datele în baza de date. Bean - ul nu mai este în bazin , are asociate anumite date pe care le reprezinta. Containerul va asocia bean - ul cu un anume obiect EJB. |
|
ejbPostCreate(<...>) |
Pentru fiecare metoda ejbCreate() trebuie sa existe o metoda ejbPostCreate() care accepta exact aceeasi parametri. Metoda este apelata imediat dupa ce a fost apelata perechea ei ejbCreate(). |
Este apelata de container imediat dupa ce i s-a asociat bean - ului un obiect EJB. Acum poate fi terminata initializarea. Se poate face orice operatiune care necesita un obiect EJB ca de exemplu pasarea unei referinte spre obiectul EJB la alte bean - uri. |
|
ejbActivate() |
Atunci când un client apeleaza o metoda de business asupra unui obiect EJB si nu este nici un bean asociat cu el, containerul va lua un bean din bazin pe care-l va trece în starea Ready. În cadrul acestui proces denumit activare containerul apeleaza metoda ejbActivate(). Metoda nu este apelata niciodata în decursul unei tranzactii. |
Se obtin orice resurse specifice de care are bean - ul nevoie pentru a deservi un anume client, ca de exemplu socket - uri. Nu este nevoie ca în cadrul acestei metode sa se citeasca datele din baza de date. Aceasta se realizeaza în cadrul metodei ejbLoad() care este apelata imediat dupa ejbActivate(). |
|
ejbLoad() |
Containerul apeleaza aceasta metoda pentru a încarca în bean datele din baza de date pe baza starii tranzactionale curente. |
În primul rând se afla cheia primara a bean - ului prin apelul metodei getPrimaryKey() a EntityContext - ului. Din aceasta cheie primara a bean -ului se va determina care date trebuie încarcate din baza de date folosind de cele mai multe ori JDBC. |
|
ejbStore() |
Containerul va apela aceasta metoda pentru a actualiza datele din baza de date cu cele din bean. Astfel se sincronizeaza datele din baza de date cu cele din bean. Starea tranzactionala curenta este utilizata de container pentru a decide când sa apeleze aceasta metoda. Metoda este apelata si în timpul procesului de pasivizare exact înainte de apelul ejbPassivate(). |
Se actualizeaza datele din baza de date de obicei prin JDBC. Se executa de obicei un statement de tipul "UPDATE ..." în care se salveaza anumite atribute ale bean - ului în tablele bazei de date. |
|
ejbPassivate() |
Containerul înainte sa trimita bean - ul înapoi în bazin el va apelea aceasta metoda. Metoda nu este apelata niciodata în decursul unei tranzactii. |
Se elibereaza orice resurse care au fost obtinute la ejbActivate() sau care depind de clientul pe care l-a deservit pâna în prezent. Nu trebuie salvata starea bean - ului în baza de date deoarece containerul a apelat deja ejbStore() deci starea este deja salvata. |
|
ejbRemove() |
Distruge datele din baza de date. Nu trebuie distrusa si instanta bean - ului deoarece containerul o poate refolosi pentru alt client. |
În primul rând se afla cheia primara a bean - ului prin apelul metodei getPrimaryKey() a EntityContext - ului. Din aceasta cheie primara a bean -ului se va determina care date trebuiesc sterse din baza de folosind de cele mai multe ori JDBC. De obicei se vor executa statementuri de tipul "DELETE ... FROM" |
|
unsetEntityContext() |
Aceasta metoda dezasociaza un bean de mediul cu care a fost asociat la instantiere. Containerul invoca aceasta metoda exact înainte de distrugerea bean - ului. |
Se elibereaza orice resurse care au fost obtinute în cadrul metodei setEntityContext() si se pregateste bean -ul pentru distrugerea sa de catre Java Garbage Collector. |
Tabelul 2.2. Rezumatul metodelor din interfata EntityBean
Acest exemplu de entity bean cu bean managed persistance prezinta un cont bancar. Acest cont bancar este stocat într-o baza de date într-un tabel account. Accesul la baza de date se face folosind JDBC. Tabelul din baza de date poate fi generat cu urmatorul script SQL. Se pastraza numele si prenumele deponentului, soldul contului si un identificator al contului. În cazul de fata, s-a considerat drept identificator unic pentru un client seria si numarul de buletin concatenate într-un sir de caractere.
|
Scriptul SQL pentru tabelul account |
|
CREATE TABLE tbl_account (id VARCHAR(30) firstname VARCHAR(24), lastname VARCHAR(24), balance DECIMAL(10,2) ); ALTER tbl_account ADD CONSTRAINT pk_account PRIMARY KEY |
Clasa entity bean - ului implementeaza metodele din interfata javax.ejb.EntityBean. Pentru accesul la baza de date se folosesc metode. Codul acestei clase este prezentat în continuare:
|
Clasa AccountEJB |
|
package exemple.entityBeanBMP; import java.sql.*; import javax.sql.*; import java.util.*; import javax.ejb.*; import javax.naming.*; public class AccountEJB implements EntityBean public void debit(double amount) throws InsufficientBalanceException balance -= amount; } public String getFirstName() public String getLastName() public double getBalance() //__________EntityBean interface methods ____________ public void setEntityContext(EntityContext context) catch (Exception ex) } public void ejbActivate() public String ejbCreate(String id, String firstName, String lastName, double balance) throws CreateException try catch (Exception ex) this.id = id; this.firstName = firstName; this.lastName = lastName; this.balance = balance; return id; } public void ejbPostCreate(String id, String firstName, String lastName, double balance) public void ejbStore() catch (Exception ex) } public void ejbLoad() catch (Exception ex) } public void ejbRemove() catch (Exception ex) } public void ejbPassivate() public void unsetEntityContext() catch (SQLException ex) } public String ejbFindByPrimaryKey(String primaryKey) throws FinderException catch (Exception ex) if (result) else } public Collection ejbFindInRange(double low, double high) throws FinderException catch (Exception ex) if (result.isEmpty()) else // ________________data base methods _______________ private void makeConnection() throws NamingException, SQLException private void insertRow (String id, String firstName, String lastName, double balance) throws SQLException private void deleteRow(String id) throws SQLException private boolean selectByPrimaryKey(String primaryKey) throws SQLException private Collection selectInRange(double low, double high) throws SQLException prepStmt.close(); return a; } private void loadRow() throws SQLException else } private void storeRow() throws SQLException } } // end of AccountEJB |
Pentru a crea o noua instanta de bean, containerul apeleaza costructorul bean - ului, apoi imediat el va apela setEntityContext(). În cadrul metodei, se stocheza contextul în care se afla bean - ul si se obtin resursele necesare bean - ului. De remarcat ca desi înca bean - ul nu este asociat cu un obiect EJB, totusi obtine o legatura la baza de date. Aceasta din motivul ca indiferent de obiectul EJB cu care va fi asociat bean - ul, acesta are nevoie de aceasta conexiune la baza de date, cu alte cuvinte, indiferent de contul pe care îl va reprezenta bean - ul, el va avea nevoie de conexiune. Bean - ul sta, în acest moment, în bazinul cu bean - uri.
Metoda ejbActivate() este apelata de catre container pentru a asocia un bean cu un obiect EJB. Bean - ul este scos din bazinul cu bean - uri si i se asociaza o cheie primara, care va fi folosita pentru a identifica datele pe care le reprezinta. În cazul de fata, în corpul metodei, singura operatie realizata este setarea atributului cheie primara din bean cu cheia primara asociata de container bean - ului. Daca bean - ul n-ar fi fost proiectat sa obtina o conexiune la baza de date în setEntityContext, aici ar fi fost locul unde s-ar fi putut realiza aceasta.
Metoda ejbCreate() din clasa bean - ului insereaza în baza de date o noua înregistrare cu datele primite la apelul metodei. Înainte de a realiza inserarea în tabelul account din baza de date, se verifica daca suma de bani ce va intra în viitorul cont este pozitiva. Daca suma este negativa, atunci se arunca o exceptie de tipul javax.ejb.CreateException. Exceptia de tipul CreateException este de regula aruncata daca unul dintre parametrii de intrare nu este valid. Daca cheia primara exista deja, se arunca o exceptie de tipul DuplicateKeyException, care, de fapt, descinde din CreateException. Inserarea se va realiza folosind metoda insertRow(), care nu este prezentata si care realizeaza inserarea în baza de date folosind JDBC. Dupa ce inserarea în baza de date a reusit, fara a fi aruncate exceptii, se vor initializa variabilele membru ale clasei cu datele ce au fost inserate în baza de date, deoarece acestea sunt datele pe care le reprezinta acest bean. La ultimul pas al metodei, se va returna cheia primara a acestei înregistrari. Trebuie mentionat ca datele pot fi inserate în baza de date si altfel, de exemplu prin intermediul unui script. Desi datele nu au fost introduse în baza de date prin apelul ejbCreate(), se pot utiliza entity beans pentru a le reprezenta.
Metoda ejbPostCreate() este apelata de catre container imediat dupa ce a fost apelata metoda ejbCreate(), însa, spre deosebire de aceasta, ea poate invoca metoda getPrimaryKey() si getEJBObject() din interfata EntityContext. Aceasta are sens, deoarece containerul afla cheia primara doar dupa ce aceasta a fost returnata de metoda ejbCreate(). În cadrul metodei ejbCreate(), nu are sens apelul celor doua metode. De cele mai multe ori, metoda ejbPostCreate() va fi fara continut. Metoda respecta regulile pe care fiecare metoda ejbPostCreate() trebuie sa le respecte:
primeste exact aceiasi parametri ca si metoda ejbCreate() cu care este pereche
nu returneaza nici un parametru
este publica
Trebuie spus ca modificatorii static si final nu pot fi utilizati.
Metodele ejbLoad() si metodele ejbStore() sunt utilizate de catre container pentru a sincroniza datele din bean cu cele din baza de date. Metoda ejbLoad() reîmprospateaza atributele bean-ului cu datele din baza de date, pe când metoda ejbStore() salveaza datele din atributele bean - ului în baza de date. Daca o metoda de business este asociata cu o tranzactie, atunci containerul invoca metoda ejbLoad() înainte ca metoda sa fie executata. Dupa executia metodei de business, containerul va apela metoda ejbStore(). Deoarece apelul acestor metode este automatizat de catre container, nu este nevoie ca în corpul metodelor de business sa se realizeze sincronizarea datelor din bean cu cele din baza de date. Cu alte cuvinte, este o greseala de întelegere sa se apeleze în metodele de business ejbLoad() sau ejbStore().
Daca cele doua metode nu reusesc sa gasesca datele în baza de date, se va arunca exceptia javax.ejb.NoSuchEntityException. Aceasta este o subclasa a EJBException, care, la rândul ei, descinde din RuntimeException, deci nu trebuie declarata în clauza throws. Atunci când NoSuchEntityException este aruncata, containerul EJB o înfasoara într-o exceptie de tipul RemoteException si o va trimite la client. Salvarea datelor în baza de date se realizeaza prin apelul metodei storeRow(), iar încarcarea lor din baza de date prin metoda loadRow().
Metoda ejbPassivate() este apelata de container pentru a dezasocia instanta bean - ului de un anume obiect EJB. Dupa apelul ei, instanta este trimisa în bazinul cu bean - uri si nu va reprezenta practic nici un fel de date. De aceea, în corpul metodei, s-a setat cheia primara a datelor pe care le reprezinta bean - ul cu null. Daca, pe parcursul ejbActivate(), s-ar fi obtinut anumite resurse, aici era locul unde ele trebuiau eliberate.
Metoda ejbRemove() este utilizata pentru a realiza stergerea entity beanI -ului, deci si a datelor din baza de date pe care le reprezinta. Aceasta se realizeaza prin apelul metodei deleteRow(), care prin JDBC realizeaza operatiunea de stergere a înregistrarii din baza de date. Metoda aceasta nu este prezentata. Daca apare vreo eroare, aceasta este prinsa si se arunca o exceptie de tipul RemoveException. Trebuie mentionat ca datele pot fi sterse si altfel din baza de date, ca de exemplu folosind un script SQL.
Metoda unsetEntityContext() este apelata de container chiar înainte ca instanta bean - ului sa fie stearsa. Din acest motiv, în cadrul ei, se va dezasocia bean - ul de contextul sau. De regula, aici este locul unde se vor elibera resursele pe care bean - ul le-a obtinut în metoda setEntityContext(). În cazul de fata, aici se va elibera conexiunea la baza de date.
Metodele utilizate pentru gasirea bean- urilor au prefixul find. Metoda ejbFindByPrimaryKey() poate fi utilizata pentru a gasi un entity bean dupa cheia primara furnizata de client. Metoda findByPrimaryKey() este obligatorie pentru orice entity bean. Aceasta metoda pare a fi ciudata, deoarece primeste si returneaza un obiect cheie primara. Trebuie remarcat ca cele doua obiecte cheie primara sunt diferite. Obiectul cheie primara primit ca parametru este cheia primara din punctul de vedere al clientului, iar cel returnat este cheia primara din punctul de vedere al containerului. Este posibil ca cele doua obiecte sa nu fie de acelasi tip. În mod obisnuit ele sunt identice ca în cazul de fata. Daca nu exista un entity bean, atunci se va arunca exceptia ObjectNotFoundException. Acesta exceptie descinde din FinderException. Ea este utilizata atunci când o finder method returneaza o singura cheie primara.
Metoda ejbFindInRange() este utilizata pentru a gasi toate acele entity beans a caror sold din cont este într-un anume interval. Metoda returneaza un obiect de tipul java.util.Collection în care sunt stocate cheile primare ale tuturor bean - urilor care satisfac cerintele impuse. Trebuie mentionat ca, folosind fiecare cheie din colectie, containerul va crea un obiect EJB. Clientul poate apela doar metoda findInRange() din interfata Remote care va returna tot o colectie, dar de obiecte EJB. În cadrul metodei ejbFindInRange(), se foloseste metoda de acces la baza de date findInRange(). Aceasta metoda obtine toate cheile primare ale conturilor, care au soldul în intervalul specificat si le adauga într-un obiect de tipul ArrayList. Obiectul de tipul ArrayList implementeaza interfata Collection, motiv pentru care poate fi returnat cu succes de catre metoda.
Metodele de business contin logica de business a bean - ului. De obicei, metodele de business nu acceseaza baza de date. Astfel se realizeaza separea logicii de business de codul de acces la baza de date. Aceasta separare este foarte utila, deoarece permite componentelor sa fie utilizate împreuna cu alta baza de date fara a fi nevoie sa fie facuta vreo modificare în metodele de business. Metodele de business realizeaza exact ceea ce le spune si numele: cu metoda credit() se depun bani în cont, iar cu metoda debit() se extrag bani din cont.
Metodele de acces la baza de date pot fi accesate doar în interiorul clasei. Ele utilizeaza JDBC 2.0. pentru a realiza accesul la baza de date, inserarea, gasirea, stergerea datelor etc. Pentru obtinerea conexiunii la baza de date se utilizeaza serviciul JNDI, cu care se obtine un obiect de tipul DataSource, care este un factory de conexiuni la baza de date.
În cadrul clasei bean - ului, este utilizata exceptia InsufficientBalanceException care este prezentata în continuare.
|
Clasa InsufficientBalanceException |
|
public class InsufficientBalanceException extends Exception public InsufficientBalanceException(String msg) |
Interfata Home defineste metodele pe care le foloseste clientul pentru crearea si gasirea entity bean - urilor.
|
Interfata Home pentru beanul Account |
| package exemple.entityBeanBMP; import java.util.Collection; import java.rmi.RemoteException; import javax.ejb.*; public interface AccountHome extends EJBHome |
Metodele create... din interfata Home trebuie sa aiba aceiasi parametri ca perechea lor ejbCreate... din clasa bean - ului. Ele vor returna un obiect de tipul interfetei Remote a bean - ului. Exceptiile aruncate de o metoda de create sunt identice cu cele pe care le poate arunca metodele ejbCreate... si ejbPostCreate... cu care este pereche. Obligatoriu trebuie aruncate exceptiile javax.ejb.CreateException si java.rmi.RemoteException. În cazul de fata, pentru unica metoda de create pe care o avem toate aceste conditii sunt satisfacute.
La fel, metodele find... vor primi aceiasi parametri ca perechile lor ejbFind... din clasa bean - ului. O metoda find... poate întoarce un obiect de tipul interfetei a bean - ului, cum este cazul metodei findByPrimaryKey() sau poate returna o colectie cu astfel de obiecte, cum este cazul metodei findInRange(). Exceptiile aruncate sunt cele pe care le arunca metoda pereche din clasa bean - ului. Obligatoriu trebuiesc aruncate exceptiile javax.ejb.FinderException si java.rmi.RemoteException.
Interfata Remote defineste toate metodele de business pe care un client le poate invoca. Ea extinde interfata javax.ejb.EJBObject. Fiecare metoda din interfata Remote trebuie sa aiba antetul identic cu cel al metodei din clasa bean - ului si obligatoriu sa arunce exceptia java.rmi.RemoteException. Tipurile de date returnate de metodele de business trebuie sa fie valide RMI, cu alte cuvinte sa fie serializabile. Tipurile primitive de date sunt valide RMI, deoarece pot fi serializate.
|
Interfata Remote pentru beanul Account |
| package exemple.entityBeanBMP; import javax.ejb.EJBObject; import java.rmi.RemoteException; public interface Account extends EJBObject |
Clientul pentu entity bean - ul Account foloseste serviciul JNDI pentru a gasi interfata Home a bean - ului, apoi creeaza doua conturi. Cheia primara pentru aceste conturi este seria buletinului fiecarui posesor al contului. Se creeaza doua conturi în care se depun si se extrag niste sume.
|
Client pentru beanul Account |
|
package exemple.entityBeanBMP; import javax.ejb.*; import javax.naming.*; import java.rmi.*; import java.util.*; public class Client extends Object // .. retragere din contul lui Mihai 150 (mai mult decat soldul) .. // .. se va arunca exceptia InsufficientBalanceException .. trycatch(InsuffiecientBalanceException ibex) } catch(Exception ex) }// end of main }// end of Client class |
Pentru ca exemplul sa poata fi rulat, este necesar ca, la deployment - ul componentei în serverul J2EE, sa se specifice numele JNDI AccountHome. Daca nu se specifica exact acest nume nu se va ridica o exceptie în codul clientului la gasirea componentei folosind JNDI. Deployment - ul unei aplicatii nu este ceva complicat, însa, pentru fiecare server J2EE se face altfel. Pentru implementarea de referinta de la Sun, exista câteva exemple în care se arata cum se instaleaza serverul J2EE si cum se face deployment - ul unei aplicatii.
Serverul J2EE de referinta este gratis pentru utilizari necomerciale si poate fi obtinut de la adresa: https://java.sun.com/j2ee/j2sdkee/ . El poate fi instalat pe Windows NT 4, Windows 2000, Linux, Solaris. Kitul pentru Windows are aproximativ 12MB.
Instructiunile de instalare pot fi gasite la adresa: https://java.sun.com/j2ee/j2sdkee/install.html.
Exemple de aplicatii si deployment - ul lor pot fi gasite la adresa:
https://java.sun.com/j2ee/j2sdkee/techdocs/guides/ejb/html/DevGuideTOC.html
sau pentru download în format PDF la adresa: https://java.sun.com/j2ee/j2sdkee/devguide1_2_1.pdf
Exemplul îsi propune stocarea unor produse care au un indentificator unic, o descriere si un pret. Toate aceste date vor fi stocate de catre container într-o baza de date proprie. Baza aceasta de date ar putea fi una obiectuala, oricum acest aspect nu este important pentru aplicatiile care folosesc container managed persistance. Programatorul scapa de scrierea codului legat de accesul la baza de date. Acest cod va fi generat de catre container, însa programatorul va trebui sa specifice care atribute ale bean - ului trebuie sa fie stocate. Atributele bean - ului, care vor fi stocate în baza de date de catre container, se numesc container managed fields.
Câmpurile bean - ului care vor fi gestionate de catre container sunt productId, description si price. Aceste câmpuri vor fi specificate folosind deployment tool. Containerul poate gestiona doar câmpuri care sunt de un tip primitiv Java, clasa serializabila, referinta la o interfata Home sau o referinta la o interfata Remote. Un câmp gestionat de container trebuie sa aiba specificatorul de acces public si sa nu fie definit cu specificatorul transient, fiindca nu va putea fi serializat. Clasa entity bean - ului este urmatoarea:
|
Clasa entity bean-ului product |
|
package exemple.entityBeanCMP; import java.util.*; import javax.ejb.*; public class ProductEJB implements EntityBean public double getPrice() public String getDescription() public String ejbCreate(String productId, String description, double price) throws CreateException this.productId = productId; this.description = description; this.price = price; return null; } public void setEntityContext(EntityContext context) public void ejbActivate() public void ejbPassivate() public void ejbRemove() public void ejbLoad() public void ejbStore() public void unsetEntityContext() public void ejbPostCreate(String productId, String description, double balance) } // ProductEJB |
Metodele setEntityContext() si unsetEntityContext() au exact aceeasi utilizare ca si în cazul bean managed persistance. În cazul de fata metodele nu contin nici un fel de cod, deoarece bean - ul nu are nevoie de resurse. În exemplul Account, deoarece se utiliza bean managed persistance, se obtinea o conexiune la baza de date.
Metoda ejbCreate() initializeaza câmpurile gestionate de container cu valoarea parametrilor de intrare. Metoda returneaza null, deoarece containerul ignora valoarea de return atunci când se utilizeaza container managed persistance. Dupa executia metodei ejbCreate(), containerul insereaza datele în baza de date.
Metoda ejbPostCreate() este apelata imediat dupa ejbCreate() de catre container si are aceeasi semnificatie ca la bean managed persistance. În cazul de fata, ea nu contine cod.
Metoda ejbActivate() are rolul neschimbat si realizeaza activarea bean - ului, ocazie în care se obtine de la EntityContext cheia primara asociata în momentul în care bean - ul a fost asociat cu obiectul EJB. Aceasta cheie primara este pastrata într-un atribut al bean - ului.
Metoda ejbStore() realizeaza sincronizarea datelor din baza de date cu cele din bean, nu si stocarea datelor în baza de date, deoarece aceasta va fi realizata de catre container imediat dupa apelul acestei metode. În corpul metodei, ar trebui pregatite datele pentru stocare în baza de date, de exemplu pentru un text s-ar putea realiza comprimarea sa.
Metoda ejbLoad() care realizeaza sincronizarea datelor din bean cu cele din baza de date va trebui sa pregateasca datele citite din baza de date de catre container pentru prelucrare. De exemplu, ar putea decomprima un text care a fost salvat în baza de date sub forma comprimata.
Metoda ejbPassivate() are acelasi rol, iar, în cadrul ei, se marcheaza dezasocierea bean - ului de obiectul EJB cu care era asociat mai înainte. Dezasocierea se realizeaza prin setarea cheii primare cu null. Tot aici se realizeaza si curatarea câmpurilor de datele pe care le-au reprezentat mai înainte. Pretul este lasat, deoarece nu poate fi setat la null, deci, oricum, nu poate fi curatat.
Metoda ejbRemove() este aplelata de catre container pentru a permite programatorului sa faca toate operatiunile premergatoare stergerii datelor din baza de date. Datele vor fi sterse de catre container imediat dupa ce s-a executat metoda ejbRemove(). Daca containerul va întâmpina dificultati în stergerea datelor, se va arunca o exceptie de runtime, care nu trebuie declarata în clauza throws.
Interfata Home respecta aceleasi reguli ca si în cazul persistentei gestionate de bean. Se observa ca în interfata apar metode de find care nu au nici un corespondent ejbFind... în clasa bean - ului. Codul pentru aceste metode este generat de catre container, folosind deployment tool.
|
Interfata Home a bean-ului product |
|
package exemple.entityBeanCMP; import java.util.Collection; import java.rmi.RemoteException; import javax.ejb.*; public interface ProductHome extends EJBHome |
Metoda findByPrimaryKey() este implementata în totalitate de catre deployment tool, inclusiv fraza de select care aduce un rând din baza de date. Celelalte doua metode utilizate pentru gasirea datelor sunt: findByDescription() si findInRange(). Ambele metode sunt implementate de catre container, însa clauza where din fraza de select este specificata de catre programator. Dupa cum se poate observa, aceste metode nici macar nu apar în clasa bean - ului, codul lor fiind gestionat de catre container.
Interfata Remote expune toate metodele de business ale bean - ului.
|
Interfata Remote a bean-ului product |
|
package exemple.entityBeanCMP; import javax.ejb.EJBObject; import java.rmi.RemoteException; public interface Product extends EJBObject |
Pentru ca exemplul sa poata fi verificat, se poate folosi codul client prezentat în continuare.
|
Codul client pentru bean - ul ProductEJB |
|
package exemple.entityBeanCMP; import java.util.*; import javax.naming.Context; import javax.naming.InitialContext; import javax.rmi.PortableRemoteObject; public class Client // .. afisarea tuturor obiectelor cu pretul intre 5 si 10 c = home.findInRange(5.00, 10.00); i = c.iterator(); while (i.hasNext()) } catch (Exception ex) } |
Pentru ca exemplul sa poata fi rulat, este necesar ca la deployment - ul componentei în serverul J2EE sa se specifice numele JNDI: "ProductHome". Daca nu se specifica exact acest nume, nu se va putea gasi componenta.
Serverul J2EE de referinta este gratis pentru utilizari necomerciale si poate fi obtinut de la adresa: https://java.sun.com/j2ee/j2sdkee/ . El poate fi instalat pe Windows NT 4, Windows 2000, Linux, Solaris. Kitul pentru Windows are aproximativ 12MB.
Instructiunile de instalare pot fi gasite la adresa: https://java.sun.com/j2ee/j2sdkee/install.html.
Exemple de aplicatii si deployment - ul lor pot fi gasite la adresa:
https://java.sun.com/j2ee/j2sdkee/techdocs/guides/ejb/html/DevGuideTOC.html
sau pentru download în format PDF la adresa: https://java.sun.com/j2ee/j2sdkee/devguide1_2_1.pdf
Unul dintre serviciile foarte valoroase puse la dispozitie de platforma J2EE îl reprezinta tranzactiile. Tranzactiile permit dezvoltarea unor aplicatii robuste, în sensul ca permit operatiilor critice sa ruleze predictibil. În trecut, tranzactiile erau dificil de utilizat, deoarece programatorii trebuiau sa lucreze direct cu Transaction API. În cazul EJB, se beneficiaza de tranzactii fara a fi nevoie sa se scrie cod. Tranzactiile sunt în miezul tehnologiei EJB, motiv pentru care sunt putin mai dificile.
Exista situatii când este preferabil sa se execute mai multe operatiuni distincte împreuna, adica fie sa se execute toate cu succes, fie nici una. Daca una dintre ele nu reuseste, atunci sa se revina la starea initiala în care nici una dintre ele nu s-a executat. Un astfel de exemplu este transferul unei sume de bani dintr- un cont în altul. Trebuie retrase fonduri dintr-un cont si depuse în alt cont. Daca reusesc ambele operatiuni, totul este în ordine, însa, daca, de exemplu, reuseste retragerea din primul cont si nu reuseste depunerea în al doilea cont, este de dorit ca sa se renunte la ambele operatiuni. Cu alte cuvinte, se doreste ca cele doua operatiuni sa fie privite ca o singura operatiune atomica , adica indivizibila.
Desigur aceasta ar putea fi realizata prin prinderea exceptiilor la fiecare pas si, în caz de exceptie, prin refacerea datelor cu cele initiale, ca în urmatorul cod:
|
Cod în care se realizeaza atomicitatea prin prinderea exceptiilor |
| trycatch(Exception ex) trycatch(Exception ex) |
Însa, în aceasta abordare, exista mai multe probleme:
Trebuie luate în calcul toate problemele posibile la fiecare pas si în codul de tratare a exceptiei, trebuie refacute toate modificarile anterioare
Codul este greu de urmarit si de asemenea este foarte predispus la erori
Problema se complica foarte mult si este usor de scapat de sub control daca operatiunile sunt mai complicate si mai multe. De exemplu, în cazul în care se doreste tratarea a 10 pasi.
Problema se complica si mai mult daca luam în calcul faptul ca operatiunile ar putea fi distribuite, adica daca mai multe masini care comunica între ele prin retea vor participa la realizarea operatiunilor (cum este cazul în aplicatiile J2EE mai complexe). În acest caz, trebuie luat în calcul si faptul ca reteaua poate sa cada în decursul unei asemenea operatiuni. Ce se întâmpla daca reteaua cade în decursul unei operatii bancare distante? E drept ca de partea clientului (sa zicem o interfata pentru aplicatia bancara care ruleaza pe server), se va ridica o exceptie, dar aceasta va fi ambigua, deoarece nu se stie daca reteaua a cazut înainte sau dupa ce s-a facut retragerea de bani din cont. Tot ce se observa este ca în decursul celor doua operatii, care se petreceau distant, a aparut o cadere a retelei. Nu se va putea detecta în nici un mod daca banii au fost sau nu retrasi din cont. Acest lucru este complet inacceptabil pentru orice aplicatie serioasa. Problema aceasta este rezolvabila prin tranzactii, deoarece ele pun la dispozitie un mecanism de refacere a datelor, daca apar astfel de erori.
Un alt caz, în care tranzactiile sunt necesare, este cel în care exista mai multe aplicatii care actioneaza simultan asupra acelorasi date. Sa presupunem ca este vorba tot despre un cont bancar asupra caruia actioneaza doua aplicatii din doua departamente diferite. În acest caz, este posibil ca o aplicatie sa modifice unele date, în timp ce cealalta modifica alte date ce tin de acelasi cont bancar. Aceasta duce cu siguranta la date inconsistente, ceea ce este complet inacceptabil pentru un cont bancar. Tot tranzactiile sunt cele care raspund la problema accesului concurent al utilizatorilor asupra datelor. Ele vor garanta ca accesul concurent al mai multor utilizatori asupra acelorasi date nu va duce la coruperea datelor.
O tranzactie este un set de operatii care apare utilizatorului ca fiind executata sub forma unei operatiuni indivizibile (atomice). În acest fel, se elimina si problema caderilor retelei, care va lasa datele într-o forma consistenta indiferent de momentul în care apare caderea retelei, deoarece se va reveni la starea initiala. Tranzactiile permit mai multor utilizatori sa utilizeze aceleasi date si garanteaza ca tot ceea ce un client modifica va fi complet modificat fara a aparea o întretesere cu ceea ce modifica alt client.
Mai mult, când se utilizeaza tranzactii, operatiunile executate vor beneficia de patru avantaje garantate. Ele sunt: atomicitatea, consistenta, izolarea si durabilitatea.
Atomicitatea garanteaza ca operatiunile sunt legate unele de altele si vor fi executate sub forma unei singure operatiuni continue. Se garanteaza totul sau nimic: fie se executa toate operatiunile cu succes, fie nici una. În cadrul unei tranzactii, pot participa mai multe componente, tranzactia va reusi numai daca toate componentele nu îsi folosesc dreptul de veto, cu alte cuvinte numai daca toate operatiunile au fost realizate cu succes.
Consistenta garanteaza ca, dupa terminarea unei tranzactii, starea sistemului va fi una consistenta. De exemplu, pentru un cont bancar, s-ar putea impune regula ca întotdeauna soldul sa fie pozitiv. Totusi, în cadrul unei tranzactii, s-ar putea sa se faca întâi o retragere si apoi o depunere. De moment s-ar putea ca soldul sa fie negativ (dupa retragere), deci contul sa fie într-o stare inconsistenta. Totusi dupa terminarea tranzactiei (dupa ce s-a reusit în acest caz depunerea), starea contului va fi consistenta. Pentru cineva, care priveste din exterior, starea contului va fi tot timpul consistenta.
Izolarea protejeaza fiecare tranzactie de a vedea rezultatele partiale produse de o alta tranzactie, ce lucreaza asupra acelorasi date. Izolarea permite mai multor tranzactii sa scrie si citeasca simultan aceleasi date din baza de date, fara a sti una de cealtalta, deoarece ele sunt izolate unele de altele. Fiecare client vede baza de date ca si cum el ar fi singurul care opereaza asupra ei. Sistemul de tranzactii foloseste, la nivelul de jos, protocoale de sincronizare asupra bazei de date. În decursul unei tranzactii, se obtine, în mod automat, blocarea unor date pentru o anumita tranzactie, dupa nevoie. Aceasta garanteaza ca nici o alta tranzactie nu va putea modifica acele date câta vreme ele sunt blocate. În acest fel, se elimina problema întreteserii actiunilor din tranzactii diferite asupra acelorasi date.
Durabilitatea garanteaza ca modificarile asupra bazelor de date vor supravietui caderilor de orice fel: masinii, retelei, etc. Pentru aceasta se mentine o istorie a tranzactiilor, care poate fi folosita pentru refacere. Daca apare cumva o cadere, datele pot fi reconstruite prin parcurgerea pasilor înregistrati în istorie.
Exista mai multe feluri de a realiza tranzactiile, iar aceste feluri sunt denumite modele de tranzactii. Cele mai populare sunt flat tranzactions si nested tranzactions. Singurul model de tranzactii suportat în prezent de J2EE este flat transactions.
O flat transaction este o serie de operatii executate ca un tot. O tranzactie careia îi reusesc toti pasii este declarata committed (comisa), în vreme ce o tranzactie careia unul dintre pasi nu i-a reusit este declarata aborted (renuntata). Atunci când o tranzactie este declarata committed, toate operatiunile care afecteaza date persistente devin permanente. Daca o tranzactie este declarata aborted, atunci nici una dintre operatiuni nu devine permanenta, ci starea este derulata invers (rolled back). O tranzactie de tipul flat transaction asigura totul sau nimic. În cele ce urmeaza, se va explica cum se realizeaza derularea inversa a unei tranzactii, daca aceasta este declarata aborted.
Se ia în considerare o flat transaction care include operatii asupra unor baze de date. Dupa ce tranzactia începe, una dintre componentele de business obtine o conexiune la o baza de date. Aceasta conexiune este automat adaugata în tranzactia în care participa respectiva componenta. Apoi componenta realizeaza unele operatiuni ce implica persistenta, ca de exemplu un update în baza de date. Toate aceste operatiuni asupra bazei de date nu sunt aplicate permanent asupra datelor de catre resourse manager-ul ei, numai când primeste comanda commit. Aceasta comanda este, însa, trimisa spre baza de date numai când tranzactia a reusit. Daca tranzactia nu a reusit si este declarata aborted, atunci nu se va trimite bazei de date comanda commit, motiv pentru care modificarile nu vor deveni niciodata permanente, ci vor fi complet neglijate.
Cel mai important lucru care trebuie retinut este ca, în mod tipic, componentele de business nu vor contine nici un fel de logica pentru a trata cazul în care se renunta la tranzactie (cu alte cuvinte nu vor contine logica de undo). Aceasta este realizata de sistem în spatele scenelor, bineînteles în colaborare cu baza de date. Rolul componentelor este de a controla tranzactiile si de a le declara aborted; derularea înapoi este realizata în mod automat de sistem. Din perspectiva programatorului, fiecare componenta trebuie sa îsi realizeze operatiunile legate de persistenta, ca si când tranzactia ar reusi.
În EJB, codul componentelor nu este niciodata utilizat de sistemul de tranzactii de la nivelul de jos, în sensul ca nu vor exista niciodata interactiuni cu vreun transaction manager sau resource manager. Codul aplicatiilor este scris la un nivel mai înalt, fara a fi nevoie sa se ia în considerare sistemul de tranzactii efectiv utilizat. Sistemul de tranzactii este abstractizat în totalitate de containerul EJB, care ruleaza în spatele scenelor. Componentele trebuie doar sa specifice daca sunt de acord ca tranzactia sa fie declarata committed, iar, daca ele nu sunt de acord, tranzactia este declarata aborted.
Tranzactiile se deruleaza în spatele scenelor, însa trebuie specificata frontiera lor: cine începe o tranzactie si cine declara o tranzactie committed sau aborted? Demarcarea frontierelor unei tranzactii se poate face declarativ sau programatic.
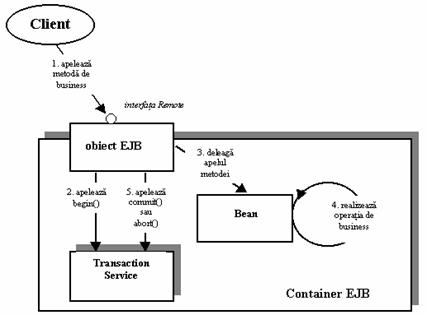
În cazul
demarcarii programatice a tranzactiilor, se va specifica în codul
componentelor EJB când începe o tranzactie, când este ea declarata commited sau aborted. Majoritatea sistemelor lucreaza în acest fel. De
exemplu, în cadrul unei aplicatii bancare, s-ar putea sa existe o
componenta care, printre altele, va avea o metoda ce realizeaza
transferul de bani dintr-un cont în altul. În cadrul acestei metode, înainte de
a se realiza prima operatiune, se va începe din cod o tranzactie,
apoi se vor realiza operatiunile necesare transferului si apoi se va
declara tranzactia drept committed.
Daca, însa, apare vreo exceptie, tranzactia se va declara aborted.
Figura 2.25. Un bean cu tranzactii declarative
Pentru cazul demarcarii declarative a tranzactiilor, sarcina de a începe o tranzactie si de a o declara committed sau aborted, cade asupra containerului. Componentele vor fi adaugate în mod automat într-o tranzactie. Studiind acelasi exemplu de bean, care reprezinta un cont bancar, el va avea, si în acest caz, o metoda de transfer de numerar dintr-un cont în altul. Când un client apeleaza metoda de transfer bancar, containerul EJB va intercepta cererea si va începe o noua tranzactie în mod automat. Apoi containerul va apela metoda bean - ului, care va realiza operatiile din cadrul acelei tranzactii. În cadrul metodei, poate fi realizat orice: executarea de logica, scrierea în baze de date, apelarea altor bean - uri. Daca apare vreo problema, bean - ul va semnaliza containerul ca tranzactia trebuie declarata aborted. Containerul va apela apoi sistemul de tranzactii, ca în cazul bean - ului TellerBean din Figura 2.25.
Tranzactiile declarative reprezinta o facilitate importanta, deoarece bean - urile nu trebuie sa mai apeleze nici un API de tranzactii. De fapt, bean - urile si clientul nici macar nu stiu ca participa în tranzactii, deoarece se vor petrece în spatele scenelor.
Alegerea între tranzactii declarative si programatice este la latitudinea programatorului componentelor. În cadrul unei aplicatii, este de preferat utilizarea tranzactiilor declarative, fiindca pentru tranzactiile programatice va trebui sa se utilizeze Java Transaction API (JTA). Totusi containerul trebuie sa afle ce tip de tranzactii sunt aplicate unui bean. Pentru aceasta este folosit un transaction attribute, care este o setare specificata în deployment descriptor. Fiecare bean are un descriptor pentru deployment, în care sunt continute o serie de proprietati pe care le va folosi containerul EJB pentru a interactiona cu bean - ul.
Containerul EJB va sti cum sa abordeze tranzactiile din atributele continute în deployment descriptor. Se pot specifica atribute pentru deployment care sa fie valabile pentru un întreg bean si se pot specifica atribute pentru fiecare metoda a bean - ului. Daca se specifica atribute pentru o metoda, atunci acel atribut este prioritar fata de atributul specificat pentru întregul bean. Cu alte cuvinte, atributul specificat pentru întregul bean se va aplica numai metodelor care nu au un atribut al lor. Modul de specificare a atributelor privitoare la tranzactii poate fi observat din Figura 2.26.
În exemplul din Figura 2.26., este prezentata modalitatea de specificare a atributelor privitoare la tranzactii pentru un entity bean denumit TheSecurity. Se observa ca, în cadrul atributelor privitoare la tranzactii, s-a specificat container managed transactions, cu alte cuvinte tranzactiile vor fi delimitate de catre container. Pentru metoda getAllTasks(), se specifica un atribut pentru tranzactii.
Valorile posibile ale atributului legat de tranzactii pentru orice metoda sunt cele din combo box si vor fi explicate în continuare.
Valoarea not supported pentru atributul legat de tranzactii semnifica faptul ca metoda respectiva nu poate fi implicata în tranzactii, deoarece nu le suporta. Sa presupunem ca bean - ul A începe o tranzactie si apoi apeleza o metoda de-a altui bean B, care nu suporta tranzactii. Tranzactia începuta de A este suspendata pâna ce se termina metoda din B, apoi este reluata.
Acest atribut ar trebui utilizat atunci când se stie ca nu este nevoie de avantajele pe care le ofera tranzactiile (atomicitate, consistenta, izolare, durabilitate), când, de exemplu, metoda bean - ului nu realizaza operatii critice. De exemplu, o metoda care returneaza, orientativ, numarul de utilzatori ce au vizitat un magazin virtual nu este critica, spre deosebire de cea care va face transferul de bani din contul clientului în cel al magazinului.
Figura 2.26. Specificarea unui atributului privitor la tranzactii cu Deployment Tool din implementarea de referinta J2EE de la Sun
Valoarea required pentru atributul legat de tranzactii semnifica nevoia ca întotdeauna acea metoda sa participe într-o tranzactie. Daca, deja, exista o tranzactie care se deruleaza, atunci apelul metodei bean - ului este adaugat în acea tranzactie, altfel se va începe una noua.
Valoarea requires new semnifica faptul ca, întotdeauna la apelul acelei metode, se va începe o noua tranzactie, indiferent ca este deja una pe rol sau nu. Daca, deja, exista o tranzactie în derulare, ea va fi suspendata pe parcursul derularii noii tranzactii. Când noua tranzactie s-a terminat (cu succes sau nu), se va relua prima tranzactie. Aceast atribut trebuie sa fie utilizat atunci când este nevoie ca o suita de operatiuni sa fie executate ca un tot unitar, fara a permite nici unei alte parti de program sa influenteze executia acelui tot.
Valoarea supports este foarte asemanatoare cu required, cu exceptia faptului ca, daca nu este o tranzactie pe rol de care sa se lipeasca, atunci nu va începe una noua.
Valoarea mandatory semnifica faptul ca este neaparat nevoie ca sa fie deja o tranzactie pe rol în momentul în care se apeleaza metoda bean - ului. Daca nu exista vreo tranzactie în derulare, atunci se va arunca exceptia javax.ejb.TransactionRequired. Containerul nu va începe o noua tranzactie daca nu era una deja în derulare.
Valoarea never semnifica faptul ca niciodata acea metoda nu va participa într-o tranzactie. Daca, în momentul când este apelata metoda exista o tranzactie în derulare, se va arunca o exceptie.
Kassem N. , Enterprise Team, Design Enterprise Applications with the Java 2 Platform Enterprise Edition version 1.0, Final Realease, Sun Microsystems 2000
Ed Roman, Mastering Enterprise Java Beans, John Wiley And Sons 1999
Monica Pawlan, Writing Enterprise Applications with Java 2 SDK Enterprise Edition, Sun Microsystems 1999
Enterprise Java Beans 1.0 Specification, Sun Microsystems 1999
Enterprise Java Beans 1.1 Specification, Sun Microsystems 2000
Calin Vaduva - Programare in Java, Editura Albastra Cluj-Napoca
JavaServer Pages 1.0 Specification, Sun Microsystems 1999
The Java Tutorial, Sun Microsystems, https://java.sun.com, 2001
Java 2 SDK, Standard Edition Documentation, v1.4.0, Sun Microsystems, https://java.sun.com, 2001
|
