Odata cu evolutia tehnologiilor imformatice s-a ajuns la standardizarea unui limbaj SQL (Structured Query Language) cu ajutorul caruia se pot prelucra datele stocate în bazele de date. Ca urmare a standardizarii în 1992 a limbajului SQL, un program poate comunica cu o baza de date fara a avea nevoie de schimbarea comenzilor SQL. Cu toate acestea, din pacate fiecare producator de SGBD a dezvoltat propriile extensii ale SQL si ofera o interfata diferita pentru manipularea datelor.
Ce este ODBC? De ce ODBC?
ODBC(Open Data Base Connectivity) reprezinta o interfata consistenta pentru prelucrarea detelor, indiferent de formatul în care acestea sunt stocate. ODBC reprezinta o colectie de functii apelabile din limbajul C, fiecare functie având un nume bine determinat si o colectie de parametrii clar stabiliti. Spre exemplu functia createTable() permite crearea unei tabele în orice format. La fel si functia getMetaData() stie sa citeasca metadatele (informatii despre structura unei baze de date) indiferent de faptul ca respectiva baza de date a fost creata cu Oracle, Access, Informix sau FoxPro. Ca urmare a acestor avantaje majore, desi ODBC a fost initial conceput ca un standard pentru PC, astazi el a devenit un standard adoptat de toate platformele.
Desi o buna parte din problemele initiale au fost rezolvate, a aparut o noua problema aceasta fiind portabilitatea. Limbajul C++ permite scrierea unei aplicatii performante pentru manipularea datelor, gratie si ODBC-ului, numai ca aplicatia respectiva trebuie rescrisa integral pentru a lucra pe o alta platforma. Acest impas apare datorita faptului ca limbajul C++ nu este unul complet (în cazul limbajului Java se stie foarte clar faptul ca o variabila de tip int va ocupa întodeauna 32 de biti, indiferent de platforma). Unul dintre avantajele pe care le ofera Java este portabilitatea. Aceasta înseamna ca putem rula un program scris în Java pe orice platforma fara sa fie nevoie ca programul sa fie recompilat. Printre bibliotecile implementate pe platformele care ruleaza Java se afla si cea care permite accesul la bazele de date din Java: JDBC (Java DataBase Connectivity). Aceasta biblioteca reprezinta echivalentul lui ODBC din C.
De ce JDBC?
Pâna acum producatorii erau preocupati de dezvoltarea si livrarea driverelor ODBC pentru sistemele lor de gestiune. Astazi ei se orienteaza spre producerea de drivere JDBC. Pentru a permite utilizarea vechilor baze de date firma Sun pune la dispozitia utilizatorilor pachetul java.sql care reprezinta un translator între apelurile JDBC si apelurile ODBC. Folosirea limbajului Java în conjunctie cu JDBC ofera o solutie cu adev& 858g61i #259;rat portabila pentru scrierea aplicatiilor care lucreaza cu baze de date.
În JDBC 1.0 API exista patru categorii de drivere:
JDBC - ODBC bridge este o interfata între JDBC driver manager si ODBC, care a devenit un standard. Acest tip de driver este deschis spre mai multe SGBD-uri. În acest caz, codul binar al ODBC trebuie încarcat pe fiecare calculator client.
Native - API este o interfata între JDBC driver manager si interfata client a SGBD-ului. Spre deosebire de primul tip care este deschis, acesta este dedicat unui SGBD. În schimb este mai performant, deoarece numarul de interfete pentru a accesa baza de date se reduce. Un program Java care realizeaza un driver de tip 2 trebuie sa încarce în memorie codul nativ al interfetei client a SGBD-ului în cauza.
JDBC - Net este o interfata între JDBC driver manager si un serviciu specializat de acces la date (middleware) care se executa pe un alt server. Protocolul de comunicare între JDBC driver manager si middleware este transparent din punct de vedere al programatorului de aplicatii.
Native - protocol este o interfata între JDBC driver manager si interfata server SGBD, încorporând complet interfata SGBD . Astfel un program Java care este utilizat ca driver de tip 4 trebuie sa deschida o conexiune în retea cu un calculator pe care se executa o interfata server a SGBD-ului care ruleaza pe calculatorul client.
Pentru orice aplicatie care lucreaza cu baze de date, exista câteva etape specifice care trebuie urmate. Dintre acestea enumeram:
Crearea unei baze de date.
Înainte de prelucrarea datelor stocate trebuie sa avem la dispozitie "containerul" care va contine toate aceste date. Adica este nevoie ca baza de date sa fie creata. Crearea unei baze de date se poate realiza fie din afara unei aplicatii Java, fie în interiorul aplicatiei Java prin transmiterea comenzilor SQL. Avantajul Java consta în faptul ca nu este nevoie sa modificam codul în functie de formatul de stocare.
Conectarea la o baza de date.
Pentru a putea accesa o baza de date este nevoie ca aplicatia Java sa se "conecteze" la sursa. În spatele acestei sintagme se ascunde urmatorul aspect: o baza de date este stocata într-un anumit format. Datele stocate într-un anumit format sunt accesate cu ajutorul unui anumit format, fie el ODBC sau JDBC. În momentul în care aplicatia noastra doreste sa se conecteze la baza de date este nevoie de alegerea driverului potrivit si încarcarea lui în memorie.
Scrierea în baza de date.
Operatiile de introducere a datelor în baza de date pot avea loc atât din afara unei aplicatii Java cât si prin intermediul unor comenzi SQL specifice transmise din cadrul unei aplicatii Java. Oricare ar fi calea aleasa, una dintre comenzile utilizate este INSERT INTO NumeTabela DATA.
Citirea selectiva a datelor.
De asemenea, operatiile de citire selectiva dintr-o baza de date, pot avea loc atât din afara unei aplicatii Java, cât si din interiorul acesteia, transmitând comanda SQL ca si parametru unei metode care caracterizeaza comportamentul unei clase din pachetul java.sql. Comanda SQL ar putea avea forma SELECT DATA FROM NumeTabela.
Putem spune ca unele dintre obiectivele stocarii datelor este ca prin prelucrarea lor sa obtinem informatii, sau altfel spus sa obtinem sistematizarea lor. Acesta este de fapt obiectul final.
JDBC permite dezvoltarea unor programe client Java (aplicatii stand-alone sau applet-uri) care acceseaza baze de date prin SGBD-ul acestora. În acest sens, un program Java, care utilizeaza JDBC este structurat pe doua straturi:
primul este orientat spre aplicatia Java, se numeste JDBC driver manager si este în ultima instanta un obiect Java la care se adreseaza mai multe obiecte ale aplicatiei.
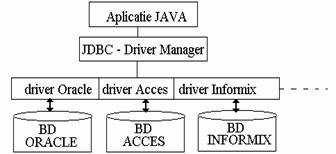
al doilea este
orientat spre SGBD si necesita drivere JDBC specifice bazelor de date
la care aplicatia client trebuie sa aiba acces. JDBC permite
accesul simultan al unei aplicatii Java la mai multe baze de date.
Figura 4.1. JDBC si aplicatiile Java
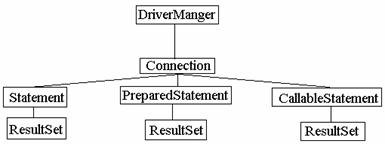
În scopul
accesarii unei baze de date Oracle, Access, Informix, etc.
producatorii driverelor trebuie sa implementeze o colectie de
clase si metode definite în cadrul a opt interfete din biblioteca
JDBC . Asa cum pot fi vazute în figura de mai jos (Figura 4.2) acestea sunt:
Figura 4.2. Interfete din biblioteca JDBC
java.sql.CallableStatement - trebuie sa permita executarea procedurilor stocate în baza de date.
java.sql.Connection - în contextul unei conexiuni cu baza de date se executa comenzile SQL si sunt returnate rezultatele.
java.sql.DatabaseMetaData - permite returnarea informatiilor referitoare la baza de date, numarul de tabele ce fac parte din baza de date, structura tabelelor din baza de date, câte câmpuri cuprinde o anumita tabela, etc.
java.sql.Driver - cadrul oferit de JDBC permite utilizarea a multiple drivere. Orice astfel de driver trebuie sa ofere o clasa care sa implementeze aceasta interfata. La cererea unei aplicatii de conectare la o baza de date, clasa DriverManager va interoga fiecare driver daca poate realiza conexiunea cu sursa de date. Aceasta interogare se poate realiza numai daca aceasta poate implementa metode din interfata Driver.
java.sql.PreparedStatement - un enunt SQL este precompilat si stocat într-un obiect de tip PreparedStatement. Acest obiect poate fi utilizat mai apoi pentru executarea de mai multe ori a respectivului enunt cu o mult mai mare eficienta.
java.sql.ResultSet - metodele acestei interfete permit accesarea tabelei generate în urma executarii unei interogari SQL.
java.sql.ResultSetMetaData - un astfel de obiect poate fi utilizat pentru a afla informatii despre tipurile sau proprietatile unei coloane din ResultSet.
java.sql.Statement - un obiect de tip Statement este utilizat pentru realizarea unei interogari SQL statice si obtinerea rezultatelor produse ca urmare a executiei sale.
Atunci când dorim sa scriem sau sa citim date dintr-un fisier, prima operatiune care se realizeaza este deschiderea fisierului. Accesul la fisier este direct. În cazul fisierului care reprezinta baza de date avem nevoie de un strat intermediar care stie sa citeasca corect datele, dat fiind faptul ca ele sunt pastrate într-un anumit format. Deci pentru citirea datelor din baza de date se utilizeaza un anumit protocol. Stratul intermediar care cunoaste acest protocol este reprezentat de driver. În concluzie contactul între doua componente, aplicatia Java si baza de date, este realizat prin intermediul driver-ului.
Conectarea aplicatiei la baza de date se executa prin intermediul unui obiect de tip Connection. Pentru a obtine conexiunea trebuie sa furnizam adresa, sau altfel spus URL-ul respectivei baze de date. Acest URL reprezinta un mod de identificare a bazei da date în asa fel încât driverul corespunzator recunoaste denumirea si poate stabili o conexiune.
Conectarea aplicatiei la baza de date este o sarcina care revine în special clasei DriverManager. Aceasta este una dintre principalele clase ale pachetului java.sql. În momentul în care se apeleaza metoda getConnection(). Clasa DriverManager încearca sa gaseasca un driver care poate sa realizeze conexiunea cu respectiva baza de date. Aceasta clasa mentine o lista a tuturor driverelor înregistrate pe sistem si la cererea de conectare din partea unei aplicatii verifica raspunsul fiecarui driver din lista la url-ul transmis ca parametru. Schimbul de informatie dintre clasa DriverManager si celelalte drivere, are loc prin intermediul interfetei Driver, interfata pe care trebuie sa o implementeze fiecare driver prin metoda: getConnection(), clasa DriverManager apeleaza metoda connect() din cadrul interfetei Driver, metoda care realizeaza conexiunea reala cu baza de date.
URL-ul transmis ca si parametru la apelul metodei getConnection() contine un sir de caractere cu o semnificatie bine determinata: jdbc.odbc.WebData. Înainte de a studia semnificatia exacta a componentelor acestui URL sa vedem exact care este definitia URL-urilor.
Un URL - Uniform Resource Locator - reprezinta o modalitate de identificare a resurselor pe Internet. În general, atunci când navigam pe Internet furnizam navigatorului o cale care specifica localizarea unui fisier sau a unui sistem legat la Internet, de exemplu https://java.sun.com/index.html. În alcatuirea unui URL se pot identifica doua parti importante: în primul rând este specificat protocolul utilizat pentru accesarea resursei iar mai apoi este furnizata adresa exacta a resursei. Adresa exacta a resursei poate cuprinde inclusiv numele site-ului (sistemului) pe care este localizat fisierul. Protocolul în cazul exemplului dat este http - Hyper Text Transfer Protocol - iar adresa exacta a resursei este data de java.sun.com/index.html.
În cazul URL-urilor JDBC, este vorba despre o cale de identificare a bazelor de date într-un mod specific unui anumit driver. Astfel, la furnizarea URL-ului numai un anumit driver stie sa recunoasca URL-ul si sa decodifice informatiile furnizate în cadrul acestuia. Practic, cei care scriu driverele sunt cei care stabilesc modul în care va arata URL-ul JDBC care identifica driverul lor. Utilizatorii driverului nu trebuie sa-si faca probleme în acest sens: se va utiliza URL-ul furnizat odata cu driverul. Rolul JDBC este doar de a recomanda anumite conventii privind modul de alcatuire a unui URL. Ca urmare a faptului ca URL-urile JDBC pot fi utilizate cu un numar mare de drivere este normal ca structura lor sa fie foarte flexibila. În primul rând, URL-urile JDBC permit diferite scheme pentru denumirea bazelor de date. Apoi, URL-urile JDBC permit producatorilor de drivere sa înglobeze toate informatiile de care au nevoie. Aceasta permite aplicatiilor sa acceseze bazele de date fara ca utilizatorul sa fie nevoit sa recurga la actiuni de administrare a bazei de date. În al treilea rând, URL-urile JDBC permit specificarea unei denumiri logice pentru baza de date si pentru sistemul pe care este localizata baza de date. Maparea denumirii logice în denumirea fizica este realizata de un anumit serviciu de naming disponibil în cadrul retelei sau pe sistemul local.
Sintaxa standard pentru un URL JDBC este urmatoarea:
|
jdbc: < subprotocol > : < subname > |
Se poate observa usor existenta celor trei parti ale unui URL JDBC, parti care au urmatoarea semnificatie:
jdbc reprezinta numele protocolului. În cadrul unui URL JDBC vom folosi întotdeauna protocolul jdbc.
subprotocolul poate reprezenta numele unui driver sau numele unui mecanism de conectare la baza de date. Un exemplu foarte sugestiv pentru denumirea unui subprotocol este odbc. Acest nume este rezervat pentru URL-urile care specifica surse de date de tipul ODBC. Pentru accesarea unei baze de date prin intermediul unui bridge JDBC-ODBC, cazul nostru este demonstrativ - jdbc:odbc:ProDb. În aceasta situatie, subprotocolul este odbc iar numele ProDb este denumirea unei surse de date ODBC locale.
Daca cineva doreste sa utilizeze un serviciu de naming atunci respectivul serviciu trebuie furnizat ca protocol. Utilizarea acestui serviciu este necesara atunci când numele bazei de date nu reprezinta pe cel real. În acest caz URL-ul va arata astfel: jdbc:dnsnaming:ProDb. Aici numele subprotocolului este serviciul de naming DNS. Acest serviciu trebuie sa rezolve numele logic al bazei de date într-un nume real care sa fie utilizat pentru conectarea la baza de date.
subname, este cea de-a treia componenta a URL-ului si reprezinta o modalitate de identificare a bazei de date. Sintaxa acestei componente poate varia în functie de driver si ca urmare poate contine toate informatiile necesare pentru localizarea bazei de date. În exemplul nostru ProDb este suficient pentru identificarea sursei de date pe sistemul local. Daca sursa de date se afla pe un alt sistem în reteaua locala sau chiar pe Internet atunci trebuie sa includem în cadrul URL-ului JDBC adresa respectivului sistem. Presupunând ca baza de date se gaseste pe un sistem aflat în Internet având adresa www.utcluj.ro si numele subprotocolului utilizat pentru conectare este dbnet atunci URL-ul pentru conectarea la baza de date va avea forma: jdbc:dbnet://www.utcluj.ro:nrPort/WebData.
Revenind la exemplul nostru, obtinerea conexiunii are loc prin apelul metodei getConnection() a clasei DriveManager.
|
Connection con = DriveManager.getConnection(url, " ", " "); |
La apelul metodei se transmit trei parametrii. Despre primul dintre acestia, URL-ul JDBC, am discutat mai sus. Urmatorii doi parametrii reprezinta numele utilizatorului care doreste accesarea bazei de date si respectiv parola asociata respectivului utilizator. În exemplul de mai sus acesti parametrii au valori nule pentru ca nu s-a cofigurat baza de date pentru a fi protejata.
Exemplu 1:
|
Utilizarea bridge-ului JDBC-ODBC: |
|
private void getDBConnection() catch (Exception e) } |
Exemplu 2:
|
Utilizarea unui ORACLE Thin Driver în cazul unui client având GUI de tip applet Java: |
|
private void getConnection() catch(Exception s) System.out.println ("Exceptie aparuta in metoda getConnection"); } } |
Exemplu 3
|
Utilizarea unui MySQL Driver |
|
private void getConnection() catch (Exception e) } |
Odata obtinuta conectarea la baza de date avem la dispozitie un obiect de tip Connection. Acest obiect reprezinta conexiunea. O sesiune de conectare cu baza de date cuprinde toate enunturile SQL care sunt executate precum si rezultatele întoarse ca urmare a acestor prelucrari. O aplicatie poate avea una sau mai multe conexiuni cu baza de date.
Comanda SQL CREATE TABLE primeste ca parametru numele tabelei si denumirile campurilor care vor face parte din structura tabelei, in acest caz, Administrator(User, MMType).
Dupa cum am vazut, un obiect de tip Statement este creat cu ajutorul metodei create Statement() a clasei Connection. Pentru executarea efectiva a comenzii SQL, obiectul de tip Statement ne pune la dispozitie trei metode, fiecare cu o sarcina foarte precisa: execute(), executeQuery(), executeUpdate().
Metoda executeQuery() este utilizata pentru acele enunturi care produc un singur set de articole. Mai bine spus, cu ajutorul acestei metode se executa interogarile de tip SELECT.
Metoda executeUpdate() este utilizata pentru executarea enunturilor de tip INSERT, DELETE si UPDATE respectiv pentru enunturi de tip SQL DDL (data definition language) cum ar fi CREATE TABLE respectiv DROP TABLE. Enunturile SQL INSERT, DELETE si UPDATE au ca efect modificarea uneia sau mai multor coloane respectiv rânduri. Metoda returneaza o valoare de tip întreg reprezentând numarul rândurilor care au fost afectate. Pentru enunturi de tip CREATE TABLE sau DROP TABLE metoda executeUpdate returneaza întotdeauna o valoare nula.
Metoda execute() este utilizata atunci când interogarea returneaza mai mult de un singur set de rezultate.
Dupa executarea unui enunt SQL, execute(), executeQuery sau executeUpdate() returneaza un rezultat. Imediat dupa obtinerea rezultatului, obiectul de tip Statement trebuie eliberat. Aceasta actiune este îndeplinita de catre garbage colector. Cu toate acestea, este recomandat ca obiectul sa fie eliberat în mod explicit prin apelarea metodei close(). Astfel se elibereaza resursele necesare pentru baza de date si se evita problemele care ar putea aparea din cauza memoriei insuficiente.
Driverul JDBC realizeaza o conversie între tipurile de date SQL si tipurile de date Java.
Exemplu - Clasa Java care realizeaza, în prima faza, o conexiune la o baza de date Microsoft Access iar apoi executa o serie de operatii care sunt observabile în momentul studierii amanuntite a codului.
|
package myPackage; import java.sql.*; import java.io.*; public class Connex catch (Exception e) }//end of Constructor // citire ID user din tabelul Admin public int getIdPass(String loginID, String parola) } catch(Exception e) return id; }//end of method // citire coloana logID din tabelul Admin public String getLoginAdmin(String logID) } catch(Exception e) return str; }//end of method // închidere conexiune public void allClosing() catch(Exception e) } // citeste int dintr - un tabel public int readIntTabel(String tabel, String coloana, String coloanaStiuta, String valoare) } catch (Exception e) return i; } //citeste String din tabel public String citesteTabel(String tabel, String coloana, String coloanaStiuta, String valoare) } catch (Exception e) return str1; } public String citesteTabel(String tabel, String coloana, String coloanaStiuta, int valoare) } catch (Exception e) return str1; } //stocare atribut in baza de date public void scrieTabel(String tabel, String coloana, String valoare) else } catch (Exception e) } // executa UPDATE public void updateTabel(String tabel, String coloana, String valoare, String coloanaStiuta, String valoareStiuta) catch (Exception e) } // UPDATE public void updateTabel(String tabel, String coloana, String valoare, String coloanaStiuta, int valoareStiuta) catch (Exception e) } public void updateTabel(String tabel, String coloana, int valoare, String coloanaStiuta, String valoareStiuta) catch (Exception e) } //trecere din String in int public int parserSI(String T) // citire id din tabel stiind o coloana public int getId (String tabel, String coloana, String valoare) } catch (Exception e) return id; } public int getId (String tabel, String coloana1, String valoare1, String coloana2, String valoare2) } catch (Exception e) return id; } // citire coloana (String) din tabel public String[] getColoana (String tabel, String coloana) i++; } } catch (Exception e) return tablou; } public int getCount (String tabel) } catch (Exception e) return count; } |
Odata cu maturizarea limbajului si aparitia tehnologiilor având la baza Java Development Kit, firma Sun Microsystem ofera pietei noul API - JDBC 2.0, având ca principal scop completarea precedentului sau JDBC 1.0. Astfel, mostenind capabilitati din prima versiune, acesta îsi propune o serie de lucruri noi, tinând oarecum pasul cu platforma Java. Elemente noi ca si Java Transaction Service (JTS), Java Naming and Directory Interface (JNDI), Enterprise Java Beans (EJB), Internationalization fac din Java 2 Enterprise Edition un produs performant. JDBC 2.0 API cunoaste toate aceste elemente, oferindu-le suport si totodata aliniindu-se si el în galeria plina de success a lui J2EE.
Ce aduce în plus JDBC2.0?
Exista câteva caracteristici importante furnizate bazelor de date care nu sunt suportate de JDBC 1.0 API, cum ar fi suport pentru cursoare scrollable si tipuri de date avansate, sau chiar suport pentru tipul de date BLOB (Binary Large Objects) si care sunt suportate de JDBC 2.0.
De asemenea trebuie sa furnizeze un cadru de lucru care sa permita accesarea instantelor de tipuri de date definite de utilizator, stocate în baza de date. API 2.0 suporta ambele tipuri de baze de date atât cele care furnizeaza capabilitati de stocare ale obiectelor Java, cât si baze de date care stocheaza tipuri de date structurate SQL3.
JDBC 2.0, extensia standard, furnizeaza suport de baza limitat, pentru acces la date de tip tabular non-SQL, de exemplu, date stocate într-un fisier.
Îmbunatatiri aduse tipului ResultSet
În principal este vorba despre doua noi caracteristici: cea de scrolling si cea de actualizare (updating). Cele mai importante metode adaugate driver-ului JDBC pentru a reusi îmbunatatiri simtitoare în aceaste directii sunt ilustrate în cele ce urmeaza:
-Scrolling
Result Set, creat prin executia unui Statement, care asigura abilitati de miscare în ambele sensuri ("last -to-first" si "first-to-last") poarta numele de scrollable Result Set. De asemenea mai suporta pozitionare absoluta si relativa. Prima se traduce prin capacitatea de miscare direct la un rând prin specificarea pozitiei lui în Result Set. Pozitionarea relativa pune în evidenta capacitatea de miscare la un rând prin specificarea pozitiei relative cu rândul current.
Trei tipuri de Result Set
Daca API 1.0 ofera un singur tip de Result Set, API 2.0 furnizeaza trei tipuri: "forward-only", cunoscut si de JDBC 1.0, scroll-insensitive, si scroll-sensitive. Asa cum le spune si numele, noile tipuri suporta scrolling, dar difera în vizibitatea schimbarilor facute în timpul în care este utilizata conexiunea la baza de date: primul este în general nesesizabil la schimbari si furnizeaza vizibilitate statica datelor vizate pe care le contine, al doilea însa, sesizeaza schimbarile aparute în timpul în care conexiunea este deschisa, si furnizeaza vizualizare dinamica a datelor.
-Doua tipuri de concurente
Primul tip se numeste "read-only" si nu permite modificarea continutului acelui Result Set. Al doilea-actualizabil, permite modificari si poate fi utilizat pentru rezolvarea accesului la aceleasi date utilizând tranzactii diferite.
Cum se creaza un ResultSet?
În exemplul de mai jos se creaza un Result Set de tip forward-only ce utlilizeaza concurenta de tip read-only. În crearea unui ResultSet este utilizat nivelul predefinit de izolare al tranzactiei.
|
Connection con = DriverManager.getConnection ("jdbc:my_subprotocol:my_subname"); Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery("SELECT emp_no, salary FROM employees"); |
Exemplul urmator creaza un Result Set scrollabil, modificabil si sensibil la modificari. Se extrag din baza de date 25 de rânduri la un moment de timp.
|
Connection con = DriverManager.getConnection("jdbc:my_subprotocol:my_subname"); Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE ); stmt.setFetchSize(25); ResultSet rs = stmt.executeQuery("SELECT emp_no, salary FROM employees"); |
În exemplul urmator se creaza un Result Set cu aceleasi atribute ca si cel precedent, utilizând însa un obiect de tip PreparedStatement pentru a-l produce.
|
PreparedStatement pstmt = con.prepareStatement("SELECT emp_no, salary FROM employees where emp_no = ?",ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); pstmt.setFetchSize(25); pstmt.setString(1, "100010"); ResultSet rs = pstmt.executeQuery(); |
Metoda supportsResultSetType() din clasa DatabaseMetaData poate fi apelata pentru a vedea ce tipuri ResultSetpot
sunt sustinute de driverul JDBC. Cu toate acestea, s-ar putea ca o aplicatie
sa ceara în continuare un driver
JDBC pentru a crea un obiect Statement, PreparedStatement, sau CallableStatement folosind un tip
ResultSet caruia driverul nu îi poate oferi suport. În acest caz, driverul
ar trebui sa puna problema unui SQLWarning pe conexiunea care produce
obiectul Statement si sa aleaga o varianta alternativa
pentru tipul Result Set al obiectului conform urmatoarelor reguli:
Daca o aplicatie cere un tip ResultSet tabelar, atunci driver-ul ar trebui sa foloseasca un tip tabelar caruia îi poate oferi suport, chiar daca acesta difera de tipul exact cerut de aplicatie.
Daca aplicatia cere un tip Result Set tabelar, iar driver-ul nu poate suporta tabelarea, atunci driver-ul ar trebui sa foloseasca un ResultSet de tip forward-only.
În mod similar, metoda supportsResultSetConcurrency()
a clasei DatabaseMetaData poate fi apelata pentru a
determina ce tipuri concurenta sunt suportate de catre driver.
Daca o aplicatie cere un driver
JDBC pentru un tip concurenta caruia nu îi poate oferi
suport atunci driver-ul ar trebui sa puna problema unui SQLWarning
pe conexiunea care produce obiectul de tip Statement
si sa aleaga tipul concurenta alternativ. Alegerea
tipului ResultSet ar trebui
facuta daca o aplicatie precizeaza atât un tip ResultSet cât si un tip
concurenta, ambele neputând fi suportate.
În anumite cazuri, un driver JDBC ar putea avea nevoie sa
aleaga un tip ResultSet
alternativ sau unul concurenta
pentru un ResultSet la timpul de
executie al obiectului de tip Statement.
De exemplu, un obiect Statement
SELECT, care contine o legatura cu mai multe tabele, s-ar putea
sa nu aiba ca rezultat un obiect de tip ResultSet ce poate fi adaptat. În acest caz driver-ul JDBC ar
trebui sa puna problema unui SQLWarning
asupra obiectului de tip Statement, PreparedStatement sau CallableStatement
care
are ca rezultat ResultSet-ul, si
sa aleaga un tip ResultSet corespunzator
sau unul concurenta dupa cum a fost descris mai sus. O
aplicatie ar putea determina tipul ResultSet
efectiv si cel concurenta ale unui ResultSet apelând metodele getType() si respectiv getConcurrency() din clasa ResultSet.
Un ResultSet poate fi actualizabil daca tipul concurentei
este CONCUR_UPDATABLE. Liniile dintr-un ResultSet asupra caruia se pot face
schimbari pot fi adaptate, inserate sau sterse. Exemplul de mai jos
actualizeaza prima linie a unui ResultSet.
Metodele ResultSet.updateXXX() sunt
folosite pentru a adapta valoarea unei coloane individuale în linia
curenta, si nu pentru a actualiza baza de date în cauza Când este
apelata metoda updateRow() din clasa ResultSet baza de date este
actualizata. Coloanele pot fi specificate prin numele sau numarul
lor.
|
rs.first(); rs.updateString(1, "100020"); rs.updateFloat("salary", 10000.0f); rs.updateRow(); |
Actualizarile pe care
le face o aplicatie trebuie sa fie înlaturate de catre un
server JDBC daca aplicatia muta cursorul de la linia curenta înainte de a apela updateRow().
În plus, o aplicatie poate apela metoda cancelRowUpdates() din
clasa ResultSet pentru a renunta în mod explicit la
actualizarile facute
asupra liniei Metoda cancelRowUpdates() trebuie
apelata dupa apelarea metodei updateXXX() si înainte de a apela
metoda updateRow() în caz
contrar, nu are nici un efect.
Exemplul urmator pune în evidenta stergerea unei linii. Linia a cincea din obiectul de tip ResultSet este stearsa din baza de date.
|
rs.absolute(5); rs.deleteRow(); |
Exemplul de urmator
descrie modul în care poate fi inserata o noua linie într-un obiect
de tip ResultSet. JDBC 2.0 API
defineste conceptul de rând de inserat, asociat fiecarui obiect de
tip ResultSet si utilizat ca
spatiu pentru crearea continutului noului rând înainte ca el sa
fie autoinserat în obiectul de tip ResultSet.
Metoda moveToInsertRow()
din clasa ResultSet este utilizata pentru
pozitionarea cursorului obiectului de tip ResultSet pe linia de inserat.
Metodele updateXXX() si getXXX() din
clasa ResultSet sunt utilizate pentru a actualiza sau a
returna valorile individuale din coloanele liniei de inserat. Continutul
acestei linii este nedefinit imediat dupa apelarea moveToInsertRow() din
clasa ResultSet. Altfel spus, valorile returnate prin
apelarea metodei getXXX() sunt nedefinite dupa ce s-a
apelat metoda moveToInsertRow() înainte
ca valorile sa fie setate prin apelarea metodei updateXXX()
Odata ce toate valorile coloanelor
sunt setate în insert row, este apelata metoda insertRow() pentru a actualiza simultan obiectul de tip ResultSet si baza de date. Daca o coloana nu are
atribuita o valoare prin apelarea metodei
update(), sau o
coloana lipseste din obiectul de tip ResultSet, aceasta valoare
este trecuta implicit cu valoarea null. Altfel, apelarea metodei insertRow() va genera o exceptie de tip SQLException
|
rs.moveToInsertRow(); rs.updateString(1, "100050"); rs.updateFloat(2, 1000000.0f); rs.insertRow(); rs.first(); |
Un obiect de tip ResultSet retine pozitia
curenta a cursorului atâta timp cât cursorul lui este pozitionat pe insert row. Saltul de pe insert row se poate realiza astfel încât
orice metoda de pozitionare a cursorului poate fi apelata, inclusiv metodele speciale moveToCurrentRow() care
returneaza cursorul la fostul rând curent înainte de apelarea metodei moveToInsertRow(). În
exemplul de mai jos este apelata metoda first() pentru
a realiza saltul de pe insert row direct pe primul rând al obiectului de tip
ResultSet.
Datorita diferetei dintre implementarile
bazelor de date, JDBC 2.0 API nu specifica o multime exacta de
interogari SQL care trebuie sa realizeze un obiect de tip ResultSet
adaptabil pentru drivere JDBC care suporta adaptabilitate.
Dezvoltatorii de aplicatii au la dispozitie urmatoarele
tipuri de interogari pentru obtinerea obiectelor de tip ResultSet
Interogari
ce referentiaza un singur tabel în baza de date
Interogare ce
nu contine nici o operatie JOIN
Interogare ce selecteaza primary key al unui tabel.
Interogare ce selecteaza toate coloanele nenule din tabel.
Interogare ce selecteaza toate coloanele care nu au o valoare implicita.
Un obiect de tip ResultSet mentine un pointer intern numit cursor care indica rândul curent accesat din interiorul acestui obiect. Acest cursor este asemeni cursorului întâlnit pe monitorul calculatorului, ce indica pozitia curenta de pe monitor (linia x, coloana y). Cursorul mentinut de un obiect ResultSet de tip forward only nu poate executa decât miscare înainte prin continutul obiectului ResultSet. Deci, rândurile sunt accesate secvential începând cu primul rând. Aceasta se realizeaza prin apelarea metodei next() a interfetei ResultSet asemeni utilizarii lui JDBC 1.0 API.
Obiectele ResultSet scrollabile implementeaza metoda beforeFirst(), care poate fi apelata sa pozitioneze cursorul înaintea primului rând din obiectul ResultSet.
Exemplul de mai jos ilustreaza pozitionarea cursorului înaintea primului rând si trecerea iterativa prin continutul obiectului result set. Metodele getXXX(), metode JDBC 1.0 API, sunt folosite pentru citirea valorilor coloanelor.
|
rs.beforeFirst(); while ( rs.next()) |
Un result set scrollabil poate executa mutarea cursorului si de la sfârsit spre început ca în exemplul de mai jos:
|
rs.afterLast(); while (rs.previous()) |
În acest caz, metoda afterLast() pozitioneaza cursorul dupa ultimul rând în result set. Metoda previous() este apelata pentru a muta cursorul de la sfârsit spre început. Aceasta metoda, asemeni metodei next() returneaza FALSE daca nu exista mai multe elemente, sau în cazul în care cursorul trece ultima pozitie vizata. Dupa examinarea atenta a interfetei ResultSet, veti recunoaste fara dubii ca exista mai multe cai de a parcurge iterativ rândurile unui ResultSet scrollabil. Iata un exemplu incorect:
|
// incorrect!!! while (!rs.isAfterLast()) |
Acest exemplu încearca o parcurgere iterativa prin continutul unui result set scrollabil, fiind însa incorect din câteva motive. Primul, apelarea metodei isAfterLast() din interfata ResultSet când obiectul result set este vid. Un alt motiv îl reprezinta pozitionarea cursorului înaintea primului rând care contine date.
Exemplul de mai jos fixeaza problemele aparute în cel anterior. Apelarea metodei first() este utilizata pentru a distinge daca obiectul ResultSet este sau nu vid. Se face remarcat faptul ca metoda isAfterLast() este apelata doar dupa ce în prealabil, s-a testat daca result set nu este vid. Controlul buclei lucreaza corect, si cu ajutorul metodei relative(1) se parcurge continutul obiectului result set dupa ce s-a facut pozitionarea cursorului pe primul rând.
|
if (rs.first()) |
Chiar daca ne gandim ca cele mai multe drivere JDBC suporta obiecte result set scrollabile, în practica se ocoleste aceast lucru, care duce la un grad de complexitate mare în implementarea lor pentru surse de date care nu suporta proprietatea de scrolling. Daca DBMS asociat cu un driver nu suporta proprietatea de scrolling, atunci aceasta poate fi omisa, sau un driver poate implementa aceasta proprietate ca si un nivel superior al DBMS. Este important de notat ca JDBC rowset, care este o parte a JDBC standard extension API, suporta scrolling si poate fi utilizat când DBMS nu suporta aceasta proprietate.
Aceasta facilitate permite operatiilor de actualizari multiple sa fie executate pentru procesarea unei singure comenzi. Executarea actualizarilor multiple în locul celor individuale pot îmbunatati vizibil performantele, în diferite situatii. Obiecte de tip Statement, PrepareStatement, si CallableStatement pot fi folosite pentru executarea acestei facilitati.
Utilizarea actualizarilor batch (Use of batch updates)
Statements - proprietatea batch updates permite unui obiect de tip Statement sa execute un set de comenzi heterogene de actualizari, ca o singura unitate, sau comanda. În exemplul de mai jos, toate operatiile de actualizare dorite pentru inserarea unui nou angajat în baza de date a unei companii fictive sunt executate ca o singura comanda.
|
// turn off autocommit con.setAutoCommit(false); Statement stmt = con.createStatement(); stmt.addBatch("INSERT INTO employees VALUES (1000, 'Joe Jones')"); stmt.addBatch("INSERT INTO departments VALUES (260, 'Shoe')"); stmt.addBatch("INSERT INTO emp_dept VALUES (1000, 260)"); // submit a batch of update commands for execution int[] updateCounts = stmt.executeBatch(); |
Se observa dezactivarea operatiei autocommit, si acest lucru este important când se doreste utilizarea actualizarilor comenzilor.
În JDBC 2.0, un obiect de tip Statement, cunoaste o lista de comenzi care se pot executa împreuna. La crearea unui astfel de obiect, lista asociata lui este vida. Adaugarea unui element în lista se face folosind metoda addBatch(). Numai comenzi DDL si DML, care returneaza un numar de actualizari simple, pot fi executate în interiorul unui batch. Pentru mai multe informatii se recomanda studierea cu atentie a documentatiei atasate pachetului javax.sql.
Prepared Statements - actualizarea comenzii este folosita si pentru asocierea multimilor multiple de valori ale parametrilor de intrare cu un singur obiect de tip PreparedStatement. Exemplul de mai jos insereaza doua noi înregistrari de angajati în baza de date ca o singura comanda. Metodele setXXX() sunt utilizate pntru a creea fiecare o multime de parametrii, una pentru fiecare angajat, iar metoda addBatch() adauga multimea de parametri la comanda curenta.
|
// turn off autocommit con.setAutoCommit(false); PreparedStatement stmt = con.prepareStatement( "INSERT INTO employees VALUES (?, ?)"); stmt.setInt(1, 2000); stmt.setString(2, "Kelly Kaufmann"); stmt.addBatch(); stmt.setInt(1, 3000); stmt.setString(2, "Bill Barnes"); stmt.addBatch(); // submit the batch for execution int[] updateCounts = stmt.executeBatch(); |
Callable Statements - facilitatea batch update lucreaza asemenea cu obiecte de tip CallableStatement ca si cu obiecte de tip PreparedStatement. Multimi multiple de valori ale parametrilor de intrare pot fi asociate cu un obiect de tip CallableStatement si trimise la DBMS. Procedurile stocate invocate utilizând facilitatea amintita mai sus cu un obiect de tip CallableStatement trebuie sa returneze un numar de actualizari si nu pot avea parametri de intrare sau de iesire. Daca aceasta restrictie este violata metoda executeBatch() va lansa o exceptie.
În API 1.0 am întâlnit suport pentru stocarea si salvarea obiectelor Java dintr - o baza de date utilizând mecanismul format din metodele getObject() si setObject(). API 2.0 intensifica abilitatea driverului JDBC de - a implementa facilitati în lucrul cu obiecte Java, în general, prin furnizarea noilor capacitati metadata care pot fi utilizate în descrierea obiectelor Java pe care sursa de date le contine. Instantele claselor Java pot fi stocate ca si obiecte Java serializate, sau în alte formate specifice furnizorului. Daca este utilizata serializarea obiectelor, atunci, referintele între obiecte pot fi tratate în concordanta cu regulile specifice serializarilor obiectelor Java.
Salvarea obiectelor Java
Exemplul de mai jos descrie modul cum pot fi stocate obiectele Java. Interogarea din exemplu referentiaza tabelul PERSONNEL care contine o coloana numita Emplyee, continând instante de clase Java.
|
ResultSet rs = stmt.executeQuery( "SELECT Employee FROM PERSONNEL"); rs.next(); Employee emp = (Employee)rs.getObject(1); |
Exemplul selecteaza toate obiectele de tip Emplyee din tabelul PERSONNEL. Metoda next(), cunoscuta din API 1.0, pozitioneaza cursorul în obiectul result set pe prima pozitie, continând obiect Employee. Prin apelarea metodei getObject() se citeste instanta clasei Employee ca si obiect neserializat pe care aplicatia o va face Employee prin cast.
Stocarea obiectelor Java
Exemplul urmator ilustreaza procesul de actualizare a obiectelor Java si realizarea copiilor actualizate ale lor.
|
emp.setSalary(emp.getSalary() * 1.5); PreparedStatement pstmt = con.preparedStatement( "UPDATE PERSONNEL SET Employee = ? WHERE Employee.no = 1001"); pstmt.setObject(1, emp); pstmt.executeUpdate(); |
Din start se apeleaza metoda getSalary() pentru a actualiza salarul angajatului. De notat ca semantica metodelor care descriu comportamentul clasei Employee nu sunt specifice JDBC. Noi discutam despre aceasta clasa ca si despre una normala si apelam metoda setSalary() doar pentru a schimba valoarea unor câmpuri de date private continute de instanta clasei Employee.
Apoi obiectul PreparedStatement este creat utilizând comanda extinsa UPDATE - sintaxa utilizata este din nou necunoscuta de JDBC. Aceasta comanda specifica faptul ca, coloana Employee a tabelului PERSONNEL este modificabila. Metoda setObject() este utilizata pentru a trece obiectele de tip Employee obiectului prepared statement, iar pe urma se apeleaza metoda executeUpdate() pentru a actualiza valoarea Employee stocata în baza de date.
Salvarea variabilelor BLOB si CLOB
Tipurile de date BLOB si CLOB sunt tratate similar cu celelalte tipuri de date, existente în JDBC. Valorile acestor tipuri de date pot fi salvate prin apelarea metodelor getBlob() si getClob() care apar în interfetele ReslutSet sau CallableStatement. De exemplu,
|
Blob blob = rs.getBlob(1); Clob clob = rs.getClob(2); |
salveaza valoarea BLOB din prima coloana a obiectului de tip ResultSet si cea CLOB din a doua coloana. Interfata Blob contine metode pentru returnarea lungimii unui BLOB, a numarului de octeti continuti în acel BLOB, etc. Interfata Clob contine operatiile corespunzatoare bazate pe caractere. Pentru mai multe informatii va rugam sa consultati documentatia acestui pachet.
O aplicatie JDBC nu lucreaza direct cu tipuri LOCATOR (blob) si LOCATOR (clob) care sunt definite în SQL. Implicit, driverul JDBC implementeaza interfetele Blob si Clob folosind tipuri de locatori apropiati. De asemenea, implicit, doar obiectele Blob si Clob ramân valide în timpul tranzactiei în care acestea sunt create. Driverul JDBC poate permite schimbarea acestor setari implicite.
Stocarea obiectelor BLOB si CLOB
Valorile obiectelor de tip BLOB si CLOB pot fi folosite ca si parametrii de intrare pentru un obiect de tip PrepareStatement la fel ca în cazul altor tipuri de date JDBC prin apelarea metodelor setBlob() si setClob(). Metodele setBinaryStream() si setObject() pot fi utilizate pentru a facilita lucrul cu obiecte de tip BLOB. Metodele setAsciiStream(), setUnicodeStream(), setObject() pot fi utilizate pentru a facilita lucrul cu obiecte de tip CLOB.
Salvarea tablourilor
Date de tip tablou SQL pot fi salvate apelând metoda getArray() din interfetele ResultSet si CallableStatement. De exemplu,
|
Array a = rs.getArray(1); |
citeste un tablou din prima coloana a obiectului de tip ResultSet. Implicit, driverul ar putea implementa interfata Array utilizând un SQL LOCATOR(array) intern. De asemenea, obiectele tablou implicite ramân valide numai pe durata tranzactiei în care au fost create. Aceaste setari implicite pot fi schimbate pentru tipurile CLOB si BLOB, dar API 2.0 nu specifica modul de realizare.
Interfata Array furnizeaza câteva metode care returneaza continutul tabloului ca un tablou Java sau obiect ResultSet. Aceastea sunt getArray() si respectiv getResultSet(). Pentru mai multe detalii consultati documentatia atasata acestui pacchet.
Stocarea tablourilor
Metoda setArray() din interfata PreparedStatement poate fi apelata pentru a introduce valorile de tablou ca si parametrii de intrare a unui obiect de tip PreparedStatement. Un tablou Java poate fi introdus ca si parametru de intrare si apelând metoda setObject() din interfata PreparedStatement.
Citirea referintelor
O referinta SQL poate fi salvata prin apelarea metodei getRef() din interfetele ResultSet si CallableStatement. De exemplu,
|
Ref ref = rs.getRef(1); |
citeste o referinta din prima coloana a obiectului de tip ResultSet. Implicit, citirea unei valori Ref nu materializeaza datele pe care aceasta le refera. De asemenea, implicit o valoare Ref ramâne valida pâna când sesiunea sau conexiunea creata este deschisa. Aceaste setari implicite pot fi suprascrise, dar API 2.0 nu specifica modul de realizare.
Stocarea referintelor
Prin apelarea metodei setRef() din interfata PreparedStatemet se poate introduce o referinta ca si parametru de intrare a unui obiect prepared statement.
Citirea tipurilor distincte
Implicit, o secventa de date ce contine tipul SQL DISTINCT poate fi salvata prin apelarea oricarei metode getXXX() din interfata ResultSet. Sa urmarim urmatoarea declarare de tip de date:
|
CREATE TYPE MONEY AS NUMERIC(10,2) |
O valoare a tipului MONEY poate fi citita dupa cum urmeaza:
|
java.math.BigDecimal bd = rs.getBigDecimal(1); |
atâta timp cât tipul de date SQL NUMERIC este mapat la tipul de date java.math.BigDecimal.
Stocarea tipurilor distincte
Prin apelarea metodei setXXX() din interfata PreparedStatemet se poate introduce un tip de date DISTINCT ca si parametru de intrare a unui obiect prepared statement. De exemplu, în cazul tipului de date MONEY poate fi utilizata metoda setBigDecimal().
Citirea tipurilor structurate
Totdeauna un obiect facând parte dintr - un tip de date structurat SQL poate fi salvata doar prin apelarea metodei getObject() din interfata ResultSet. Implicit, aceasta metoda returneaza o valoare de tip Struct pentru un tip structurat. De exemplu,
|
Struct struct = (Struct)rs.getObject(1); |
citeste o valoare Struct din prima coloana a rândului curent de result set. Interfata Struct contine metode pentru citirea atributelor de tip structurat cum ar fi un tablou de valori de tip Object. Implicit, un obiect Struct este considerat valid pe atâta timp cât aplicatia pastreaza referinta la el.
Stocarea tipurilor distincte
Prin apelarea metodei setObject() din interfata PreparedStatement se poate introduce un tip de date structurat ca si parametru de intrare a unui obiect prepared statement.
Elementele introduse în acest subcapitol reprezinta doar o trecere în revista a celor mai importante aspecte legate de lucrul cu bazele de date utilizând JDBC 2.0 API. Pentru implementarea unor astfel de idei se poate folosi documentatia pachetului javax.sql.
4.8. Bibliografie
https://java.sun.com/docs/books/tutorial/index.html
www.codeguru.com/java/
www.javaworld.com
Oracle 8, Release 8.0.5. Documentation Libtrary
|
